

{kind=link}
As massive language fashions (LLMs) proceed to develop in scale, so does the necessity for environment friendly methods to retailer, deploy, and run them on low-resource units. Whereas these fashions provide highly effective capabilities, their measurement and reminiscence calls for could make deployment a problem, particularly on shopper {hardware}. That is the place mannequin quantization and specialised storage codecs like GGUF (Generic GPT Unified Format) come into play.
On this information, we’ll delve into the GGUF format, discover its advantages, and supply a step-by-step tutorial on changing fashions to GGUF. Alongside the way in which, we’ll contact on the historical past of mannequin quantization and the way GGUF advanced to assist trendy LLMs. By the top, you’ll have a deep understanding of why GGUF issues and learn how to begin utilizing it on your personal fashions.
Studying Targets
- Comprehend the aim and construction of the GGUF format and its evolution from GGML.
- Outline quantization and describe its significance in decreasing mannequin measurement and bettering deployment effectivity.
- Acknowledge the elements of the GGUF naming conference and the way they support in mannequin identification and administration.
- Use llama.cpp to quantize fashions to gguf format.
- Relate the ideas of GGUF and quantization to sensible use circumstances, enabling efficient deployment of AI fashions in resource-constrained environments.
This text was revealed as part of the Knowledge Science Blogathon.
Evolution of Mannequin Quantization
The journey towards GGUF begins with understanding the evolution of mannequin quantization. Quantization reduces the precision of mannequin parameters, successfully compressing them to scale back reminiscence and computational calls for. Right here’s a fast overview:
Early Codecs and Challenges
Within the early days, deep studying fashions have been saved within the native codecs of frameworks like TensorFlow and PyTorch. TensorFlow fashions used .pb recordsdata, whereas PyTorch used .pt or .pth. These codecs labored for smaller fashions however introduced limitations:
- Dimension: Fashions have been saved in 32-bit floating-point format, making file sizes massive.
- Reminiscence Use: Full-precision weights demanded appreciable reminiscence, making deployment on units with restricted RAM impractical.
ONNX (Open Neural Community Alternate)
The rise of interoperability throughout frameworks led to the event of ONNX, which allowed fashions to maneuver between environments. Nonetheless, whereas ONNX supplied some optimizations, it was nonetheless primarily constructed round full-precision weights and supplied restricted quantization assist.
Want for Quantization
As fashions grew bigger, researchers turned to quantization, which compresses weights from 32-bit floats (FP32) to 16-bit (FP16) and even decrease, like 8-bit integers (INT8). This method reduce reminiscence necessities considerably, making it doable to run fashions on extra {hardware} varieties. For instance:
# Import mandatory libraries
import torch
import torch.nn as nn
import torch.quantization as quant
# Step 1: Outline a easy neural community mannequin in PyTorch
class SimpleModel(nn.Module):
def __init__(self):
tremendous(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 50) # First totally linked layer
self.fc2 = nn.Linear(50, 20) # Second totally linked layer
self.fc3 = nn.Linear(20, 5) # Output layer
def ahead(self, x):
x = torch.relu(self.fc1(x)) # ReLU activation after first layer
x = torch.relu(self.fc2(x)) # ReLU activation after second layer
x = self.fc3(x) # Output layer
return x
# Step 2: Initialize the mannequin and swap to analysis mode
mannequin = SimpleModel()
mannequin.eval()
# Save the mannequin earlier than quantization for reference
torch.save(mannequin, "simple_model.pth")
# Step 3: Apply dynamic quantization to the mannequin
# Right here, we quantize solely the Linear layers, altering their weights to INT8
quantized_model = quant.quantize_dynamic(
mannequin, {nn.Linear}, dtype=torch.qint8
)
# Save the quantized mannequin
torch.save(quantized_model, "quantized_simple_model.pth")
# Instance utilization of the quantized mannequin with dummy knowledge
dummy_input = torch.randn(1, 10) # Instance enter tensor with 10 options
output = quantized_model(dummy_input)
print("Quantized mannequin output:", output)

Checking the scale of unique and quantized mannequin
When working with massive language fashions, understanding the scale distinction between the unique and quantized variations is essential. This comparability not solely highlights the advantages of mannequin compression but in addition informs deployment methods for environment friendly useful resource utilization.
import os
# Paths to the saved fashions
original_model_path = "simple_model.pth"
quantized_model_path = "quantized_simple_model.pth"
# Operate to get file measurement in KB
def get_file_size(path):
size_bytes = os.path.getsize(path)
size_kb = size_bytes / 1024 # Convert to KB
return size_kb
# Verify the sizes of the unique and quantized fashions
original_size = get_file_size(original_model_path)
quantized_size = get_file_size(quantized_model_path)
print(f"Unique Mannequin Dimension: {original_size:.2f} KB")
print(f"Quantized Mannequin Dimension: {quantized_size:.2f} KB")
print(f"Dimension Discount: {((original_size - quantized_size) / original_size) * 100:.2f}%")
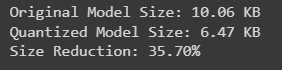
Nonetheless, even 8-bit precision was inadequate for very massive language fashions like GPT-3 or LLaMA, which spurred the event of recent codecs like GGML and, finally, GGUF.
What’s GGUF?
GGUF, or Generic GPT Unified Format, was developed as an extension to GGML to assist even bigger fashions. It’s a file format for storing fashions for inference with GGML and executors primarily based on GGML. GGUF is a binary format that’s designed for quick loading and saving of fashions, and for ease of studying. Fashions are historically developed utilizing PyTorch or one other framework, after which transformed to GGUF to be used in GGML.
GGUF is a successor file format to GGML, GGMF and GGJT, and is designed to be unambiguous by containing all the knowledge wanted to load a mannequin. It is usually designed to be extensible, in order that new data might be added to fashions with out breaking compatibility. It was designed with three objectives in thoughts:
- Effectivity: Allows massive fashions to run effectively on CPUs and consumer-grade {hardware}.
- Scalability: Helps very massive fashions, usually 100GB or extra.
- Flexibility: Permits builders to decide on between completely different quantization ranges, balancing mannequin measurement and accuracy.
Why Use GGUF?
The GGUF format shines for builders who have to deploy massive, resource-heavy fashions on restricted {hardware} with out sacrificing efficiency. Listed below are some core benefits:
- Quantization Assist: GGUF helps a spread of quantization ranges (4-bit, 8-bit), permitting for vital reminiscence financial savings whereas sustaining mannequin precision.
- Metadata Storage: GGUF can retailer detailed metadata, corresponding to mannequin structure, tokenization schemes, and quantization ranges. This metadata makes it simpler to load and configure fashions.
- Inference Optimization: GGUF optimizes reminiscence use, permitting for quicker inference on CPU-based methods.
GGUF Format Construction and Naming Conventions
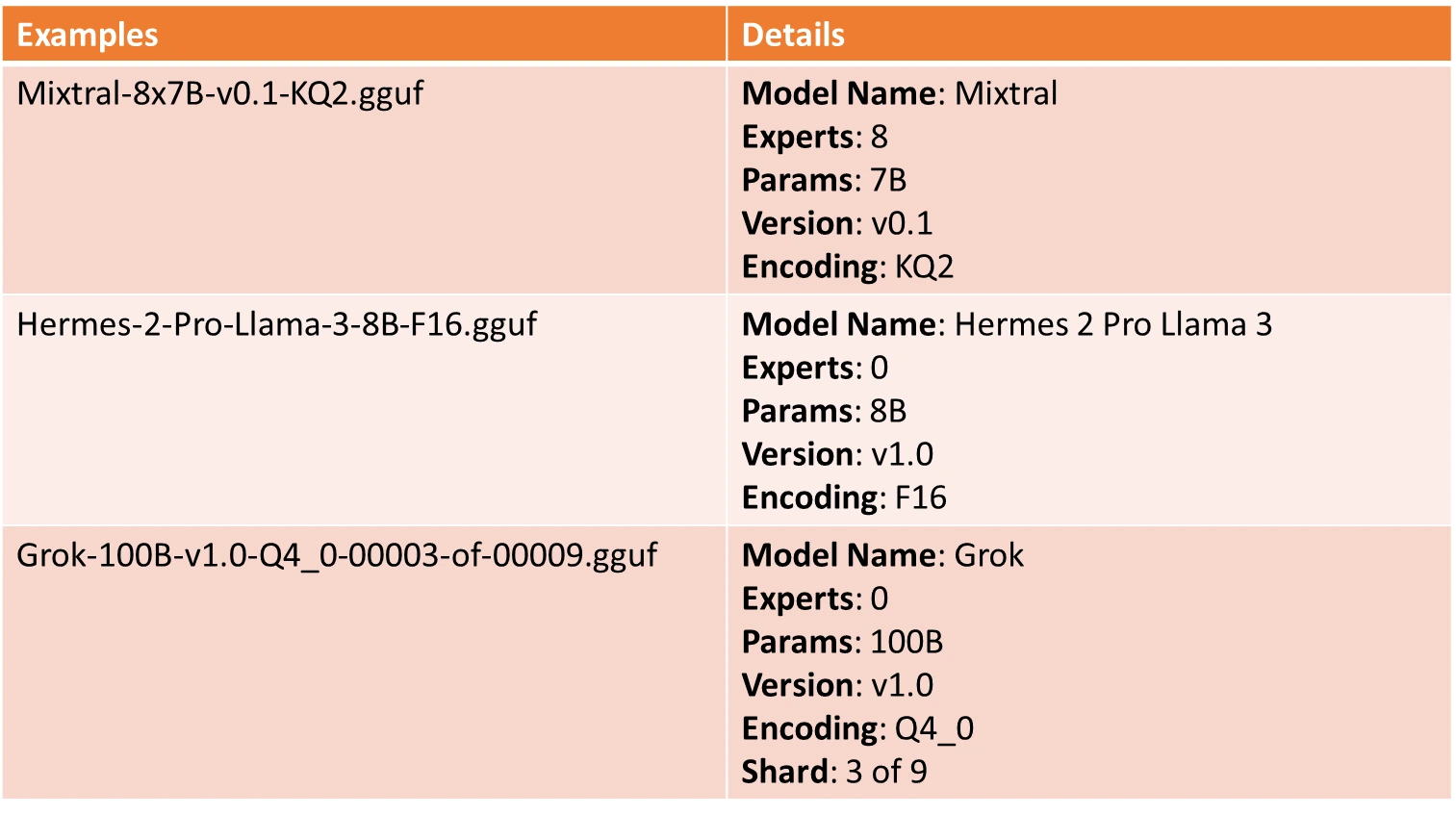
The GGUF format employs a particular naming conference to supply key mannequin data at a look. This conference helps customers determine essential mannequin traits corresponding to structure, parameter measurement, fine-tuning kind, model, encoding kind, and shard knowledge—making mannequin administration and deployment simpler.
The GGUF naming conference follows this construction:

Every part within the title gives perception into the mannequin:
- BaseName: Descriptive title for the mannequin base kind or structure, derived from metadata (e.g., LLaMA or Mixtral).
- SizeLabel: Signifies mannequin measurement, utilizing an x format i.e. <expertCount>: Variety of specialists (e.g., 8), <depend><scale-prefix>: Mannequin parameter scale, like Q for Quadrillion, T for Trillion, B for Billion, M for Million, Okay for Thousand parameters.
- FineTune: Mannequin fine-tuning aim, corresponding to “Chat” or “Instruct.”
- Model: Mannequin model quantity in v<Main>.<Minor> format, with v1.0 as default if unspecified.
- Encoding: Weight encoding scheme, customizable per venture.
- Kind: Signifies GGUF file kind, corresponding to LoRA for adapters or vocab for vocabulary knowledge.
- Shard: Denotes a mannequin break up into components, formatted as <ShardNum>-of-<ShardTotal>.
Naming Examples
Setting Up for Conversion to GGUF Format
Earlier than diving into conversion, guarantee you will have the next stipulations:
- Python 3.8+ put in in your system.
- Mannequin supply file: Sometimes, a PyTorch or TensorFlow mannequin (e.g., LLaMA, Falcon) or mannequin from hugging face.
- GGUF Conversion Instruments: These instruments, usually primarily based on GGML libraries or particular model-conversion scripts.
Some Noteworthy Quantization Methods
Quantization methods play a pivotal position in optimizing neural networks by decreasing their measurement and computational necessities. By changing high-precision weights and activations to decrease bit representations, these strategies allow environment friendly deployment of fashions with out considerably compromising efficiency.
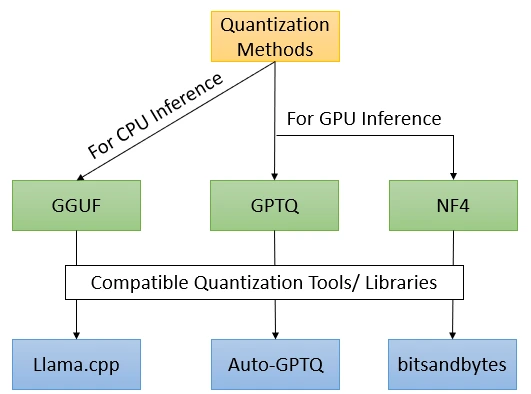
Changing Fashions to GGUF
Under is how you would convert your mannequin to GGUF format.
Step 1: Select the Mannequin to Quantize
On this case, we’re selecting Google’s Flan-T5 mannequin to quantize. You can comply with the command to instantly obtain the mannequin from Huggingface
!pip set up huggingface-hub
from huggingface_hub import snapshot_download
model_id="google/flan-t5-large" # Change with the ID of the mannequin you wish to obtain
snapshot_download(repo_id=model_id, local_dir="t5")Step 2: Clone the llama.cpp repository
We’re utilizing llama.cpp to quantize mannequin to gguf format
!git clone https://github.com/ggerganov/llama.cppStep 3: Set up the required dependencies
If in Google Collaboratory, comply with the beneath code, else you would navigate to the necessities listing to put in the “requirements-convert_hf_to_gguf.txt”
!pip set up -r /content material/llama.cpp/necessities/requirements-convert_hf_to_gguf.txtStep 4: Select the Quantization Stage
The quantization degree determines the trade-off between mannequin measurement and accuracy. Decrease-bit quantization (like 4-bit) saves reminiscence however might cut back accuracy. For instance, when you’re focusing on a CPU-only deployment and don’t want most precision, INT4 is likely to be a good selection. Right here we’re selecting “q8_0”.
Step 5: Run the Conversion Script
If in Google Collab, run the beneath script, else comply with the remark.
# !python {path to convert_hf_to_gguf.py} {path to hf_model} --outfile {name_of_outputfile.gguf} --outtype {quantization kind}
!python /content material/llama.cpp/convert_hf_to_gguf.py /content material/t5 --outfile t5.gguf --outtype q8_0- path to hf_model: Path to the mannequin listing.
- name_of_outputfile.gguf: Identify of the output file the place the GGUF mannequin shall be saved. Use gguf naming conference if pushing quantized mannequin again to hugging face.
- quantization kind: Specifies the quantization kind (on this case, quantized 8-bit integer).
Evaluating Dimension of Unique Vs Quantized Mannequin
When deploying machine studying fashions, understanding the scale distinction between the unique and quantized variations is essential. This comparability highlights how quantization can considerably cut back mannequin measurement, resulting in improved effectivity and quicker inference occasions with out substantial lack of accuracy.
# Verify the sizes of the unique and quantized fashions
original_model_path="/content material/t5/mannequin.safetensors"
quantized_model_path="t5.gguf"
original_size = get_file_size(original_model_path)
quantized_size = get_file_size(quantized_model_path)
print(f"Unique Mannequin Dimension: {original_size:.2f} KB")
print(f"Quantized Mannequin Dimension: {quantized_size:.2f} KB")
print(f"Dimension Discount: {((original_size - quantized_size) / original_size) * 100:.2f}%")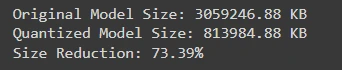
We might see a measurement discount of staggering 73.39% utilizing GGUF quantization method.
Finest Practices for GGUF Conversion
To get the perfect outcomes, maintain the following tips in thoughts:
- Experiment with Quantization Ranges: Take a look at a number of ranges (e.g., 4-bit, 8-bit) to seek out the perfect steadiness between mannequin accuracy and reminiscence effectivity.
- Use Metadata to Your Benefit: GGUF’s intensive metadata storage can simplify mannequin loading and cut back runtime configuration wants.
- Benchmark Inference: At all times benchmark the GGUF mannequin in your goal {hardware} to make sure it meets pace and accuracy necessities.
Way forward for GGUF and Mannequin Storage Codecs
As fashions proceed to develop, codecs like GGUF will play an more and more crucial position in making large-scale AI accessible. We might quickly see extra superior quantization methods that protect much more accuracy whereas additional decreasing reminiscence necessities. For now, GGUF stays on the forefront, enabling environment friendly deployment of enormous language fashions on CPUs and edge units.
Conclusion
The GGUF format is a game-changer for deploying massive language fashions effectively on limited-resource units. From early efforts in mannequin quantization to the event of GGUF, the panorama of AI mannequin storage has advanced to make highly effective fashions accessible to a wider viewers. By following this information, now you can convert fashions to GGUF format, making it simpler to deploy them for real-world purposes.
Quantization will proceed to evolve, however GGUF’s capacity to assist various precision ranges and environment friendly metadata administration ensures it would stay related. Strive changing your fashions to GGUF and discover the advantages firsthand!
Key Takeaways
- The Generic GPT Unified Format (GGUF) allows environment friendly storage and deployment of enormous language fashions (LLMs) on low-resource units, addressing challenges related to mannequin measurement and reminiscence calls for.
- Quantization considerably reduces mannequin measurement by compressing parameters, permitting fashions to run on consumer-grade {hardware} whereas sustaining important efficiency ranges.
- The GGUF format encompasses a structured naming conference that helps determine key mannequin traits, facilitating simpler administration and deployment.
- Utilizing instruments like
llama.cpp, customers can simply convert fashions to GGUF format, optimizing them for deployment with out sacrificing accuracy. - GGUF helps superior quantization ranges and intensive metadata storage, making it a forward-looking resolution for the environment friendly deployment of more and more massive AI fashions.
Incessantly Requested Questions
A. GGUF (Generic GPT Unified Format) is a sophisticated mannequin storage format designed to effectively retailer and run quantized massive language fashions. In contrast to its predecessor, GGML, which has restricted scalability for fashions exceeding 100GB, GGUF helps intensive 4-bit and 8-bit quantization choices and gives a wealthy metadata storage functionality, enhancing mannequin administration and deployment.
A. Quantization reduces the precision of a mannequin’s parameters, considerably reducing its measurement and reminiscence utilization. Whereas it could actually result in a slight drop in accuracy, well-designed quantization methods (like these in GGUF) can preserve acceptable efficiency ranges, making it possible to deploy massive fashions on resource-constrained units.
A. The GGUF naming conference consists of a number of elements, together with the BaseName (mannequin structure), SizeLabel (parameter weight class), FineTune (fine-tuning aim), Model (mannequin model quantity), Encoding (weight encoding scheme), Kind (file function), and Shard (for break up fashions). Collectively, these elements present important details about the mannequin.
A. You’ll be able to validate GGUF file names utilizing an everyday expression that checks for the presence of not less than the BaseName, SizeLabel, and Model within the appropriate order. This ensures the file adheres to the naming conference and incorporates the required data for mannequin identification.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.