

{kind=link}
Each group is challenged with accurately prioritizing new vulnerabilities that have an effect on a big set of third-party libraries used inside their group. The sheer quantity of vulnerabilities printed every day makes guide monitoring impractical and resource-intensive.
At Databricks, certainly one of our firm aims is to safe our Knowledge Intelligence Platform. Our engineering group has designed an AI-based system that may proactively detect, classify, and prioritize vulnerabilities as quickly as they’re disclosed, primarily based on their severity, potential impression, and relevance to Databricks infrastructure. This strategy allows us to successfully mitigate the chance of crucial vulnerabilities remaining unnoticed. Our system achieves an accuracy price of roughly 85% in figuring out business-critical vulnerabilities. By leveraging our prioritization algorithm, the safety group has considerably diminished their guide workload by over 95%. They’re now in a position to focus their consideration on the 5% of vulnerabilities that require fast motion, relatively than sifting by way of a whole lot of points.
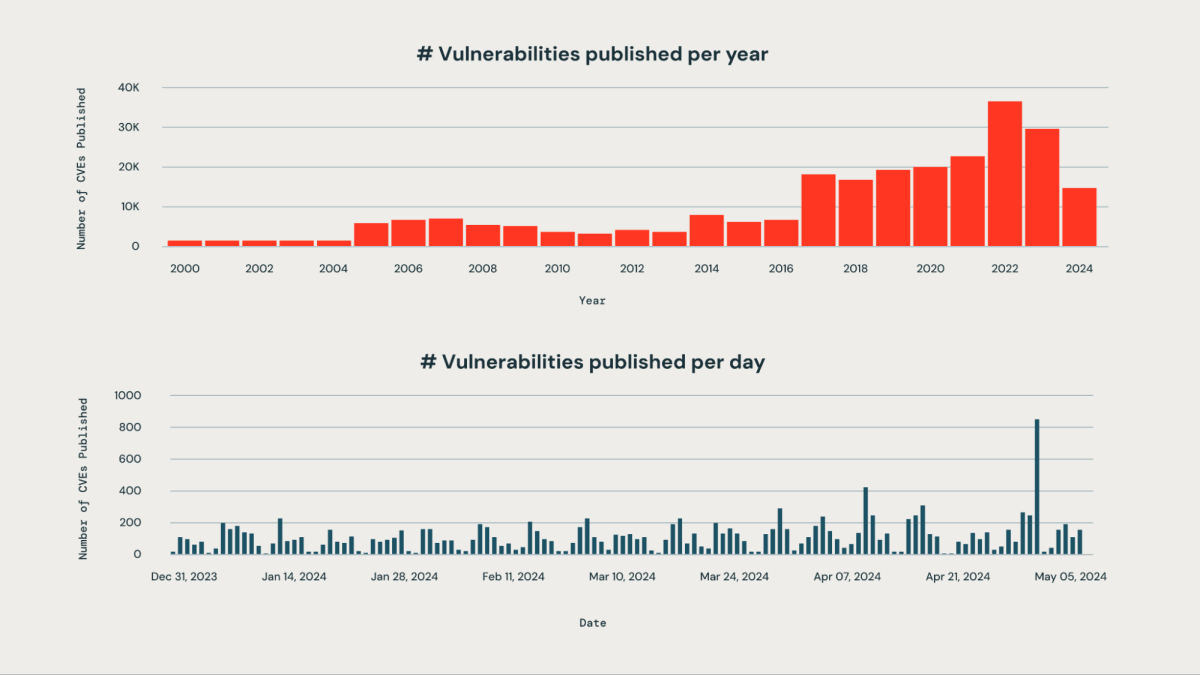
Within the subsequent few steps, we’re going to discover how our AI-driven strategy helps determine, categorize and rank vulnerabilities.
How Our System Constantly Flags Vulnerabilities
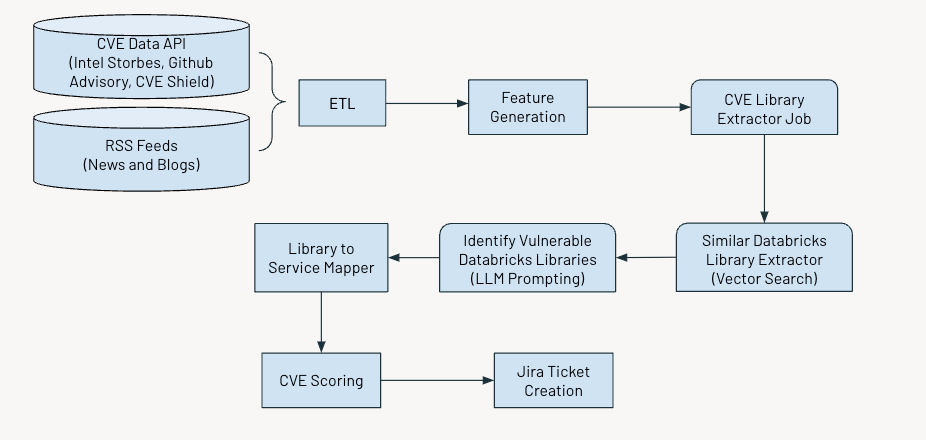
The system operates on a daily schedule to determine and flag crucial vulnerabilities. The method entails a number of key steps:
- Gathering and processing knowledge
- Producing related options
- Using AI to extract details about Widespread Vulnerabilities and Exposures (CVEs)
- Assessing and scoring vulnerabilities primarily based on their severity
- Producing Jira tickets for additional motion.
The determine under reveals the general workflow.
Knowledge Ingestion
We ingest Widespread Vulnerabilities and Exposures (CVE) knowledge, which identifies publicly disclosed cybersecurity vulnerabilities from a number of sources akin to:
- Intel Strobes API: This gives data and particulars on the software program packages and variations.
- GitHub Advisory Database: Usually, when vulnerabilities usually are not recorded as CVE, they seem as Github advisories.
- CVE Protect: This gives the trending vulnerability knowledge from the latest social media feeds
Moreover, we collect RSS feeds from sources like securityaffairs and hackernews and different information articles and blogs that point out cybersecurity vulnerabilities.
Characteristic Technology
Subsequent, we are going to extract the next options for every CVE:
- Description
- Age of CVE
- CVSS rating (Widespread Vulnerability Scoring System)
- EPSS rating (Exploit Prediction Scoring System)
- Impression rating
- Availability of exploit
- Availability of patch
- Trending standing on X
- Variety of advisories
Whereas the CVSS and EPSS scores present helpful insights into the severity and exploitability of vulnerabilities, they might not absolutely apply for prioritization in sure contexts.
The CVSS rating doesn’t absolutely seize a corporation’s particular context or surroundings, which means {that a} vulnerability with a excessive CVSS rating won’t be as crucial if the affected element will not be in use or is satisfactorily mitigated by different safety measures.
Equally, the EPSS rating estimates the chance of exploitation however would not account for a corporation’s particular infrastructure or safety posture. Due to this fact, a excessive EPSS rating may point out a vulnerability that’s more likely to be exploited usually. Nonetheless, it’d nonetheless be irrelevant if the affected techniques usually are not a part of the group’s assault floor on the web.
Relying solely on CVSS and EPSS scores can result in a deluge of high-priority alerts, making managing and prioritizing them difficult.
Scoring Vulnerabilities
We developed an ensemble of scores primarily based on the above options – severity rating, element rating and matter rating – to prioritize CVEs, the main points of that are given under.
Severity Rating
This rating helps to quantify the significance of CVE to the broader group. We calculate the rating as a weighted common of the CVSS, EPSS, and Impression scores. The info enter from CVE Protect and different information feeds allows us to gauge how the safety group and our peer firms understand the impression of any given CVE. This rating’s excessive worth corresponds to CVEs deemed crucial to the group and our group.
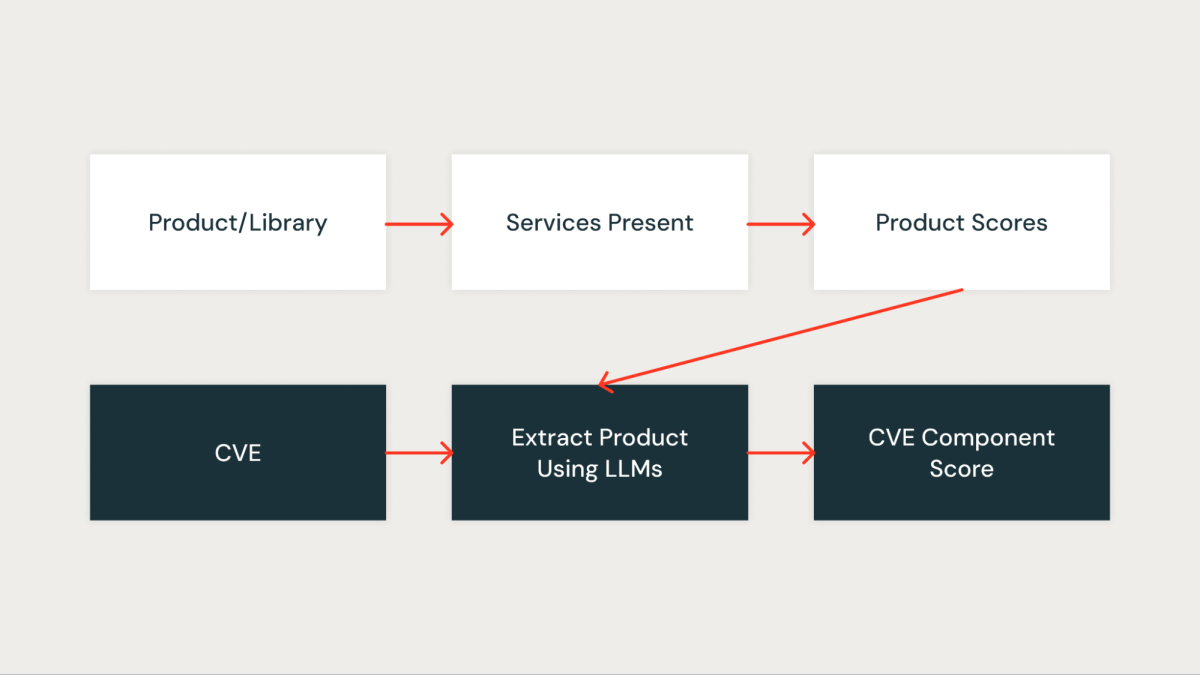
Element Rating
This rating quantitatively measures how necessary the CVE is to our group. Each library within the group is first assigned a rating primarily based on the companies impacted by the library. A library that’s current in crucial companies will get a better rating, whereas a library that’s current in non-critical companies will get a decrease rating.
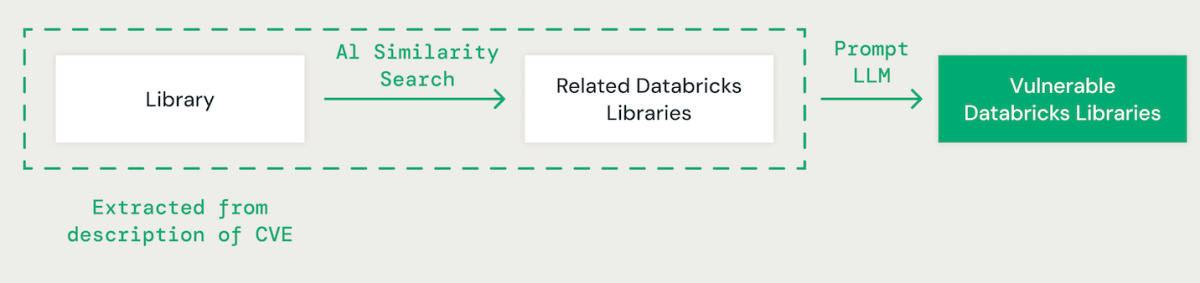
AI-Powered Library Matching
Using few-shot prompting with a big language mannequin (LLM), we extract the related library for every CVE from its description. Subsequently, we make use of an AI-based vector similarity strategy to match the recognized library with present Databricks libraries. This entails changing every phrase within the library title into an embedding for comparability.
When matching CVE libraries with Databricks libraries, it is important to grasp the dependencies between totally different libraries. For instance, whereas a vulnerability in IPython might indirectly have an effect on CPython, a difficulty in CPython might impression IPython. Moreover, variations in library naming conventions, akin to “scikit-learn”, “scikitlearn”, “sklearn” or “pysklearn” should be thought-about when figuring out and matching libraries. Moreover, version-specific vulnerabilities needs to be accounted for. As an example, OpenSSL variations 1.0.1 to 1.0.1f could be susceptible, whereas patches in later variations, like 1.0.1g to 1.1.1, might handle these safety dangers.
LLMs improve the library matching course of by leveraging superior reasoning and trade experience. We fine-tuned varied fashions utilizing a floor fact dataset to enhance accuracy in figuring out susceptible dependent packages.
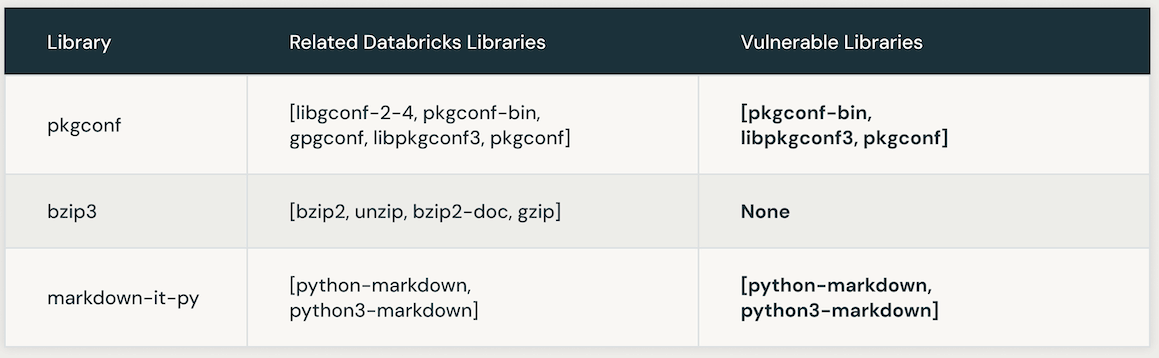
The next desk presents situations of susceptible Databricks libraries linked to a selected CVE. Initially, AI similarity search is leveraged to pinpoint libraries carefully related to the CVE library. Subsequently, an LLM is employed to establish the vulnerability of these comparable libraries inside Databricks.
Automating LLM Instruction Optimization for Accuracy and Effectivity
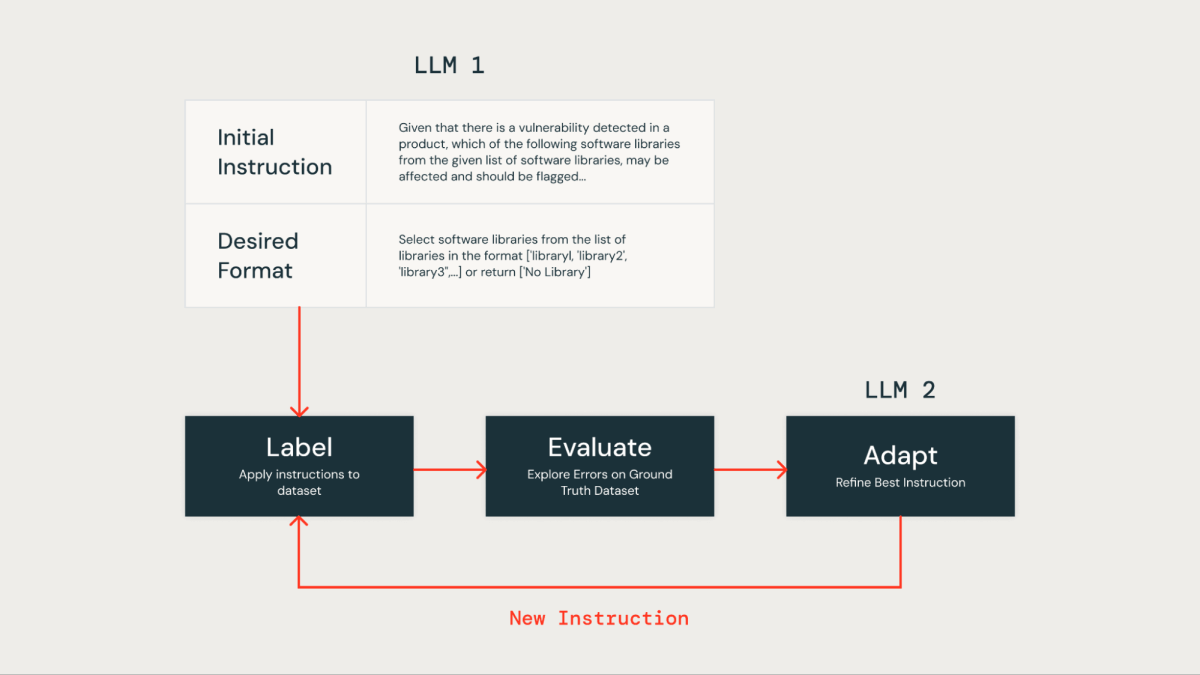
Manually optimizing directions in an LLM immediate will be laborious and error-prone. A extra environment friendly strategy entails utilizing an iterative methodology to robotically produce a number of units of directions and optimize them for superior efficiency on a ground-truth dataset. This methodology minimizes human error and ensures a simpler and exact enhancement of the directions over time.
We utilized this automated instruction optimization approach to enhance our personal LLM-based resolution. Initially, we offered an instruction and the specified output format to the LLM for dataset labeling. The outcomes had been then in contrast towards a floor fact dataset, which contained human-labeled knowledge offered by our product safety group.
Subsequently, we utilized a second LLM often known as an “Instruction Tuner”. We fed it the preliminary immediate and the recognized errors from the bottom fact analysis. This LLM iteratively generated a collection of improved prompts. Following a assessment of the choices, we chosen the best-performing immediate to optimize accuracy.
After making use of the LLM instruction optimization approach, we developed the next refined immediate:
Selecting the best LLM
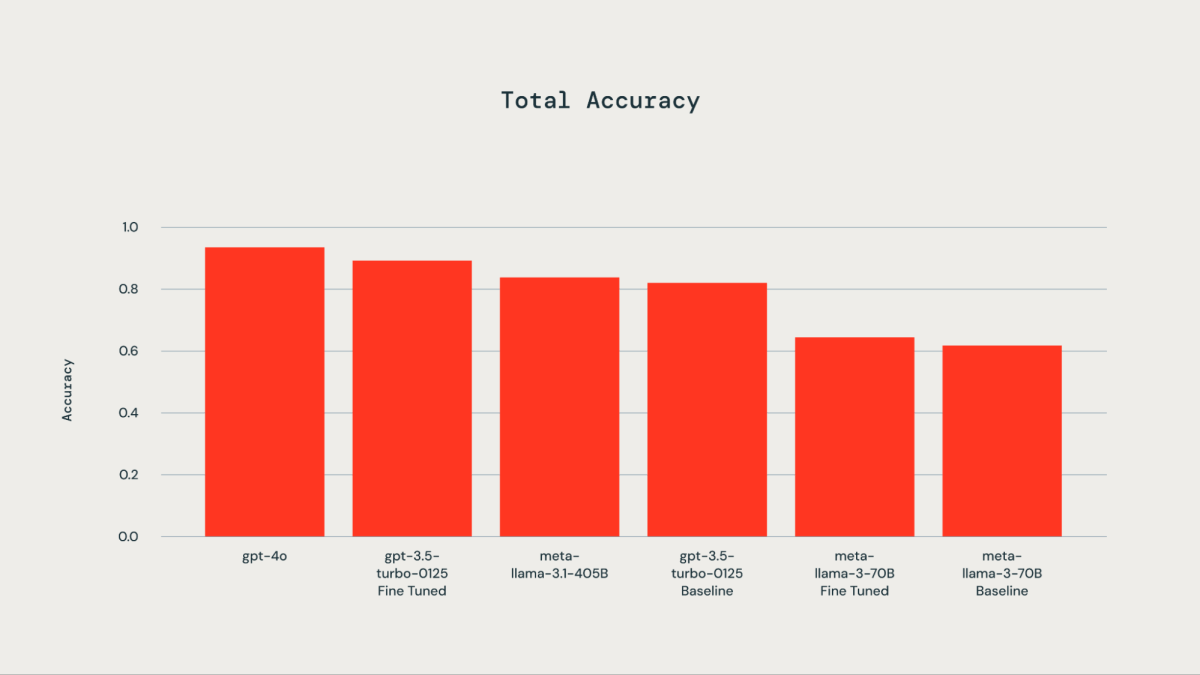
A floor fact dataset comprising 300 manually labeled examples was utilized for fine-tuning functions. The examined LLMs included gpt-4o, gpt-3.5-Turbo, llama3-70B, and llama-3.1-405b-instruct. As illustrated by the accompanying plot, fine-tuning the bottom fact dataset resulted in improved accuracy for gpt-3.5-turbo-0125 in comparison with the bottom mannequin. Superb-tuning llama3-70B utilizing the Databricks fine-tuning API led to solely marginal enchancment over the bottom mannequin. The accuracy of the gpt-3.5-turbo-0125 fine-tuned mannequin was corresponding to or barely decrease than that of gpt-4o. Equally, the accuracy of the llama-3.1-405b-instruct was additionally corresponding to and barely decrease than that of the gpt-3.5-turbo-0125 fine-tuned mannequin.
As soon as the Databricks libraries in a CVE are recognized, the corresponding rating of the library (library_score as described above) is assigned because the element rating of the CVE.
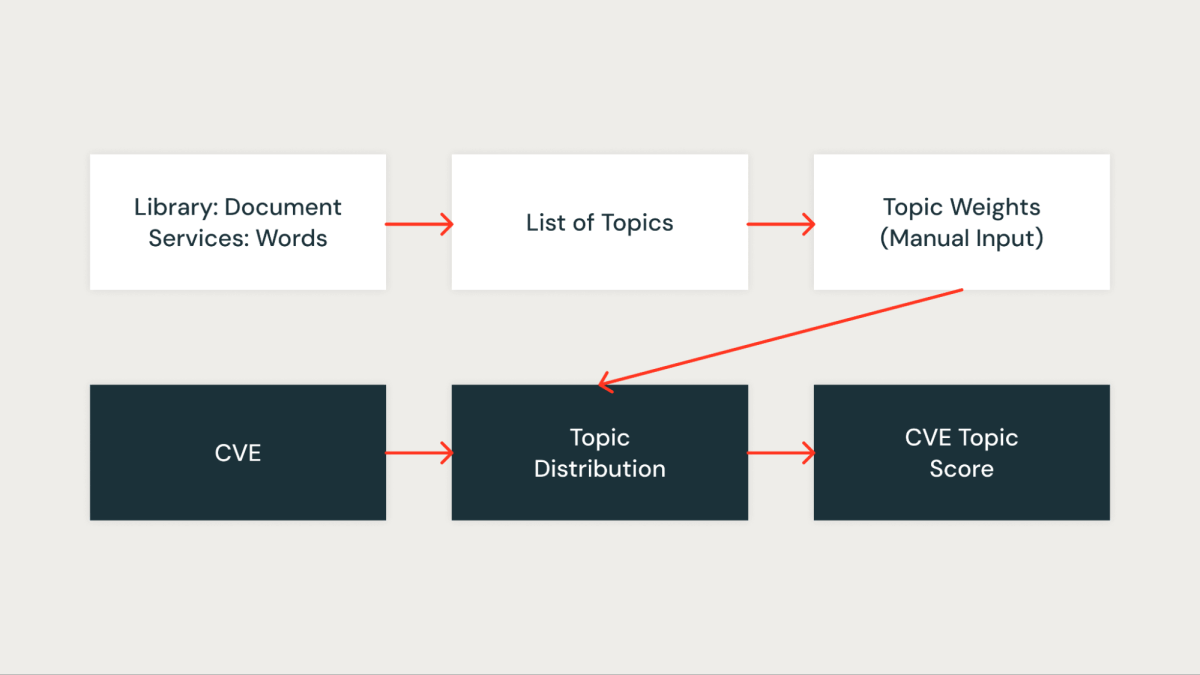
Subject Rating
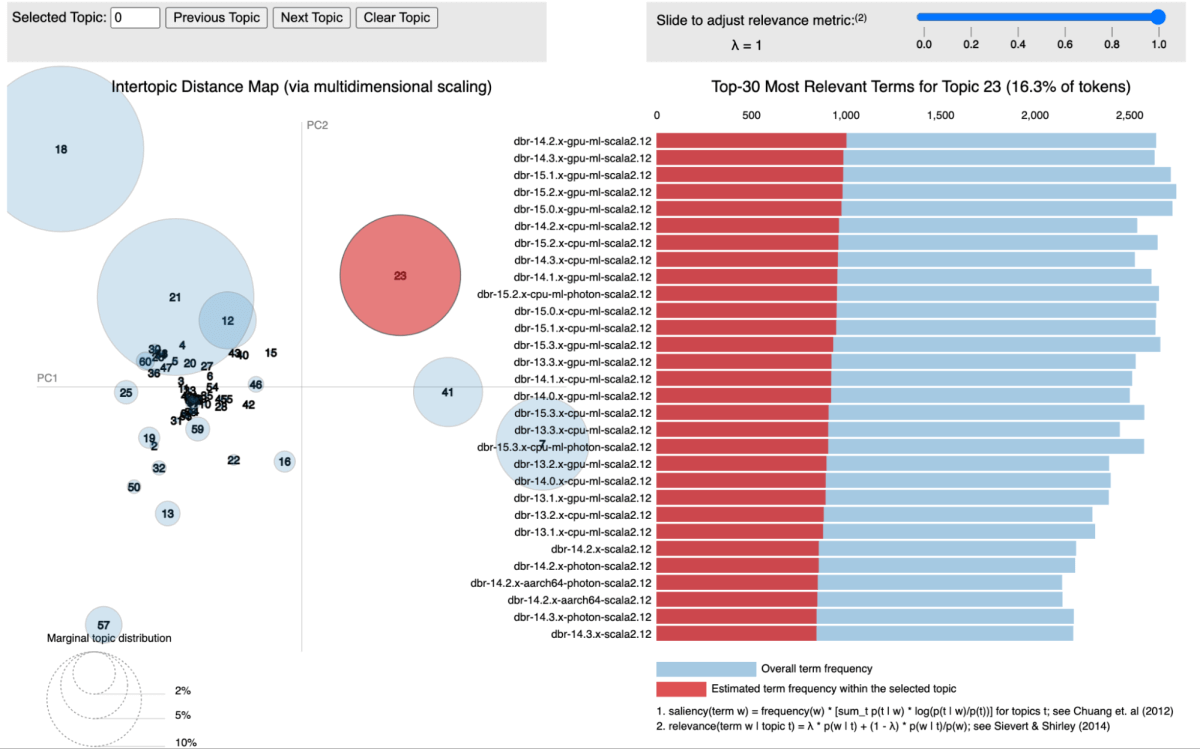
In our strategy, we utilized matter modeling, particularly Latent Dirichlet Allocation (LDA), to cluster libraries in line with the companies they’re related to. Every library is handled as a doc, with the companies it seems in performing because the phrases inside that doc. This methodology permits us to group libraries into subjects that signify shared service contexts successfully.
The determine under reveals a selected matter the place all of the Databricks Runtime (DBR) companies are clustered collectively and visualized utilizing pyLDAvis.
For every recognized matter, we assign a rating that displays its significance inside our infrastructure. This scoring permits us to prioritize vulnerabilities extra precisely by associating every CVE with the subject rating of the related libraries. For instance, suppose a library is current in a number of crucial companies. In that case, the subject rating for that library can be larger, and thus, the CVE affecting it should obtain a better precedence.
Impression and Outcomes
We now have utilized a variety of aggregation strategies to consolidate the scores talked about above. Our mannequin underwent testing utilizing three months’ price of CVE knowledge, throughout which it achieved a formidable true constructive price of roughly 85% in figuring out CVEs related to our enterprise. The mannequin has efficiently pinpointed crucial vulnerabilities on the day they’re printed (day 0) and has additionally highlighted vulnerabilities warranting safety investigation.
To gauge the false negatives produced by the mannequin, we in contrast the vulnerabilities flagged by exterior sources or manually recognized by our safety group that the mannequin did not detect. This allowed us to calculate the share of missed crucial vulnerabilities. Notably, there have been no false negatives within the back-tested knowledge. Nonetheless, we acknowledge the necessity for ongoing monitoring and analysis on this space.
Our system has successfully streamlined our workflow, reworking the vulnerability administration course of right into a extra environment friendly and targeted safety triage step. It has considerably mitigated the chance of overlooking a CVE with direct buyer impression and has diminished the guide workload by over 95%. This effectivity achieve has enabled our safety group to focus on a choose few vulnerabilities, relatively than sifting by way of the a whole lot printed every day.
Acknowledgments
This work is a collaboration between the Knowledge Science group and Product Safety group. Thanks to Mrityunjay Gautam Aaron Kobayashi Anurag Srivastava and Ricardo Ungureanu from the Product Safety group, Anirudh Kondaveeti Benjamin Ebanks Jeremy Stober and Chenda Zhang from the Safety Knowledge Science group.