

{kind=link}
Analytics on DynamoDB
Engineering groups typically have to run advanced filters, aggregations and textual content searches on knowledge from DynamoDB. Nevertheless, DynamoDB is an operational database that’s optimized for transaction processing and never for real-time analytics. Because of this, many engineering groups hit limits on analytics on DynamoDB and look to various choices.
That’s as a result of operational workloads have very completely different entry patterns than advanced analytical workloads. DynamoDB solely helps a restricted set of operations, making analytics difficult and in some conditions not doable. Even AWS, the corporate behind DynamoDB, advises corporations to think about offloading analytics to different purpose-built options. One resolution generally referenced is Elasticsearch which we might be diving into at present.
DynamoDB is likely one of the hottest NoSQL databases and is utilized by many web-scale corporations in gaming, social media, IoT and monetary companies. DynamoDB is the database of selection for its scalability and ease, enabling single-digit millisecond efficiency at scales of 20M requests per second. In an effort to obtain this velocity at scale, DynamoDB is laser targeted on nailing efficiency for operational workloads- excessive frequency, low latency operations on particular person data of information.
Elasticsearch is an open-source distributed search engine constructed on Lucene and used for textual content search and log analytics use circumstances. Elasticsearch is a part of the bigger ELK stack which incorporates Kibana, a visualization software for analytical dashboards. Whereas Elasticsearch is understood for being versatile and extremely customizable, it’s a advanced distributed system that requires cluster and index operations and administration to remain performant. There are managed choices of Elasticsearch obtainable from Elastic and AWS, so that you don’t have to run it your self on EC2 situations.
Shameless Plug: Rockset is a real-time analytics database constructed for the cloud. It has a built-in connector to DynamoDB and ingests and indexes knowledge for sub-second search, aggregations and joins. However this submit is about highlighting use circumstances for DynamoDB and Elasticsearch, in case you need to discover that choice.
Connecting DynamoDB to Elasticsearch Utilizing AWS Lambda
You should utilize AWS Lambda to repeatedly load DynamoDB knowledge into Elasticsearch for analytics. Right here’s the way it works:
- Create a lambda operate to sync each replace from a DynamoDB stream into Elasticsearch
- Create a lambda operate to take a snapshot of the prevailing DynamoDB desk and ship it to Elasticsearch. You should utilize an EC2 script or an Amazon Kinesis stream to learn the DynamoDB desk contents.
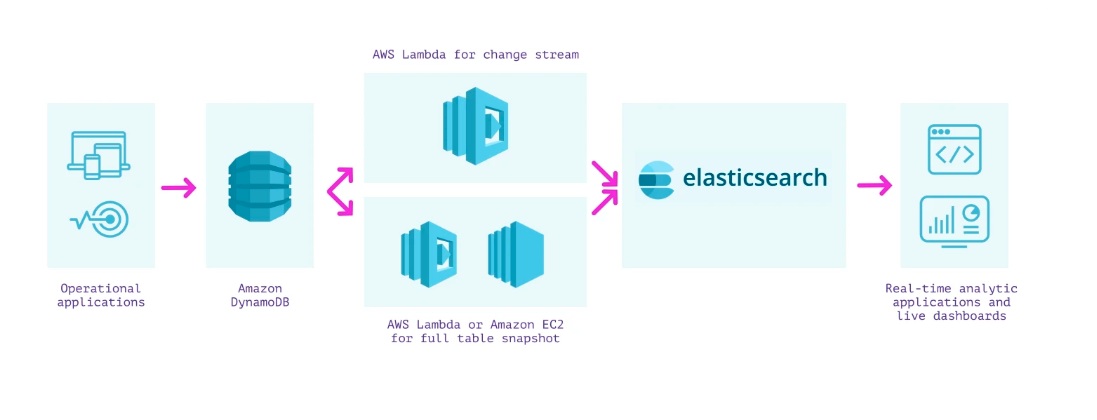
There may be an alternate strategy to syncing knowledge to Elasticsearch involving the Logstash Plugin for DynamoDB however it’s not at the moment supported and might be advanced to configure.
Textual content Search on DynamoDB Knowledge Utilizing Elasticsearch
Textual content search is the looking of textual content inside a doc to search out essentially the most related outcomes. Oftentimes, you’ll need to seek for part of a phrase, a synonym or antonyms of phrases or a string of phrases collectively to search out the very best outcome. Some functions will even weight search phrases in a different way based mostly on their significance.
DynamoDB can help some restricted textual content search use circumstances simply by utilizing partitioning to assist filter knowledge down. As an illustration, if you’re an ecommerce website, you may partition knowledge in DynamoDB based mostly on a product class after which run the search in-memory. Apparently, that is how Amazon.com retail division handles a variety of textual content search use circumstances. DynamoDB additionally helps a comprises operate that lets you discover a string that comprises a specific substring of information.
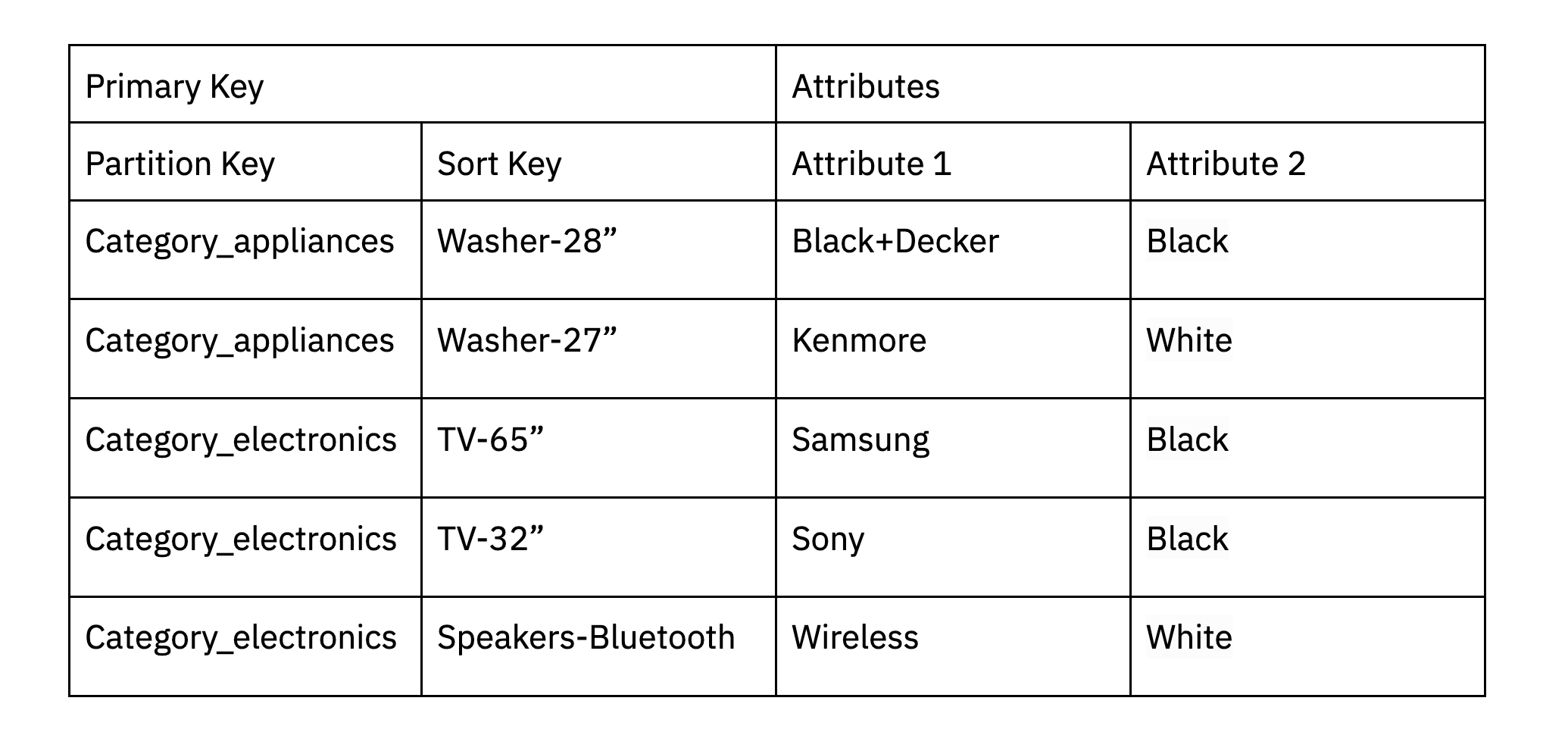
An e-commerce website would possibly partition knowledge based mostly on product class. Further attributes could also be proven with the info being searched just like the model and shade.
In situations the place full textual content search is core to your utility, you’ll need to use a search engine like Elasticsearch with a relevancy rating. Right here’s how textual content search works at a excessive degree in Elasticsearch:
- Relevance rating: Elasticsearch has a relevance rating that it provides to the search outcomes out-of-the-box or you may customise the rating in your particular utility use case. By default, Elasticsearch will create a rating rating based mostly on the time period frequency, inverse doc frequency and the field-length norm.
- Textual content evaluation: Elasticsearch breaks textual content down into tokens to index the info, known as tokenizing. Analyzers are then utilized to the normalized phrases to boost search outcomes. The default commonplace analyzer splits the textual content in line with the Unicode Consortium to supply basic, multi-language help.
Elasticsearch additionally has ideas like fuzzy search, auto-complete search and much more superior relevancy might be configured to satisfy the specifics of your utility.
Advanced Filters on DynamoDB Knowledge Utilizing Elasticsearch
Advanced filters are used to slim down the outcome set, thereby retrieving knowledge quicker and extra effectively. In lots of search situations, you’ll need to mix a number of filters or filter on a variety of information, resembling over a time frame.
DynamoDB partitions knowledge and selecting a very good partition key might help make filtering knowledge extra environment friendly. DynamoDB additionally helps secondary indexes so as to replicate your knowledge and use a special main key to help extra filters. Secondary indexes might be useful when there are a number of entry patterns in your knowledge.
As an illustration, a logistics utility may very well be designed to filter objects based mostly on their supply standing. To mannequin this state of affairs in DynamoDB, we’ll create a base desk for logistics with a partition key of Item_ID, a kind key of Standing and attributes purchaser, ETA and SLA.
We additionally have to help a further entry sample in DynamoDB for when supply delays exceed the SLA. Secondary indexes in DynamoDB might be leveraged to filter down for under the deliveries that exceed the SLA.
An index might be created on the sphere ETADelayedBeyondSLA which is a duplicate of the ETA attribute already within the base desk. This knowledge is barely included in ETADelayedBeyondSLA when the ETA exceeds the SLA. The secondary index is a sparse index, decreasing the quantity of information that must be scanned within the question. The purchaser is the partition key and the type key’s ETADelayedBeyondSLA.
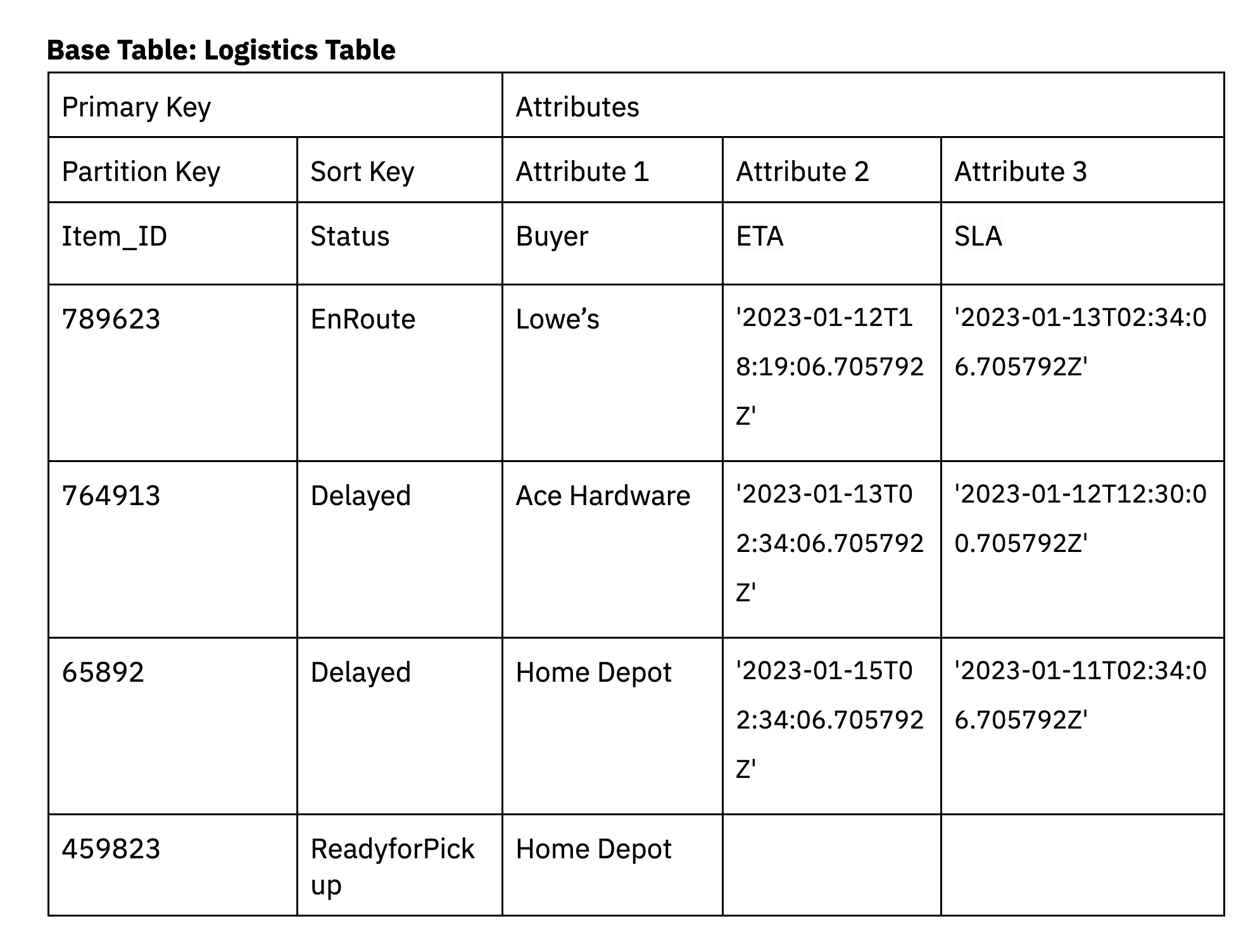
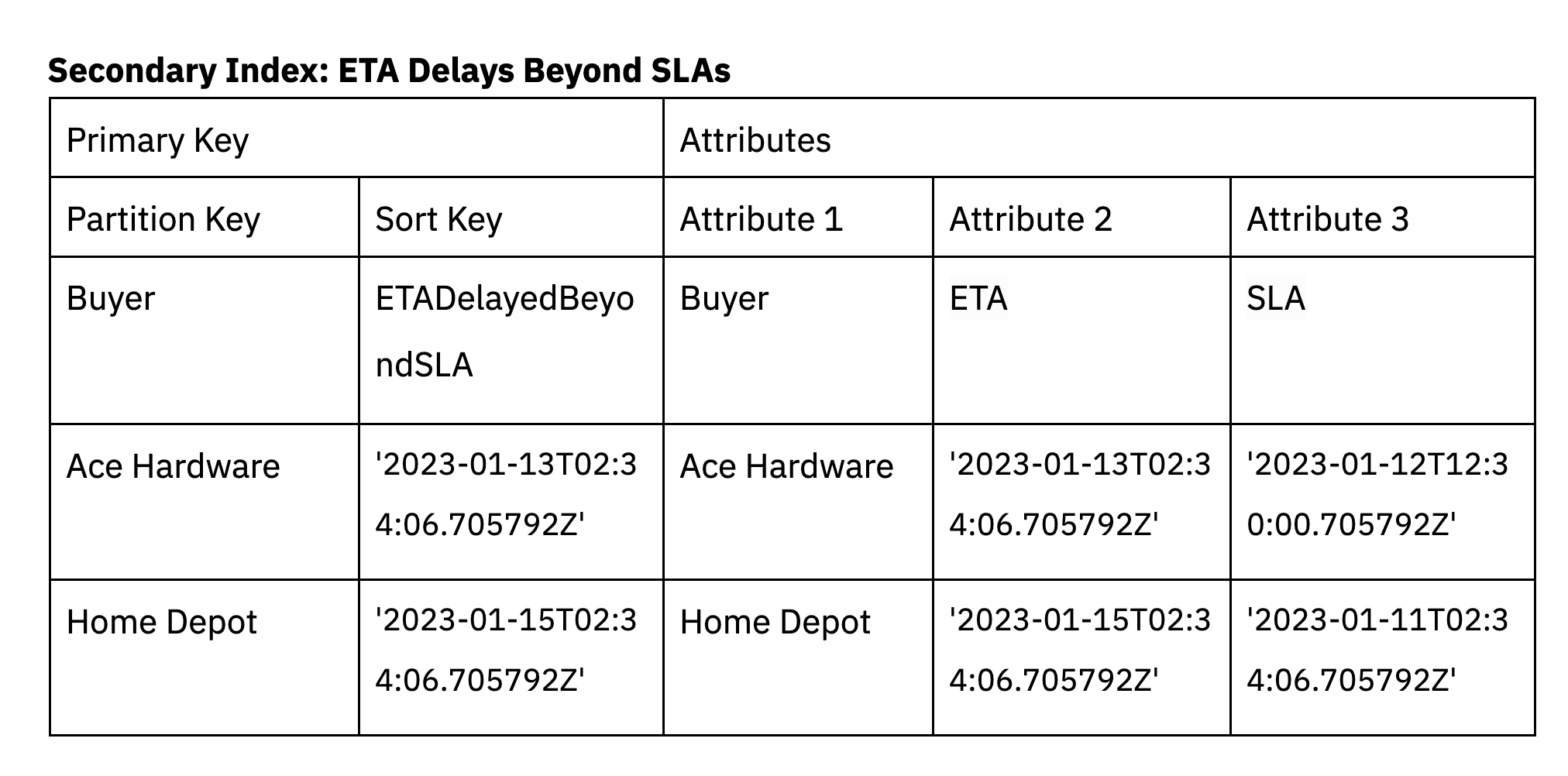
Secondary indexes can be utilized to help a number of entry patterns within the utility, together with entry patterns involving advanced filters.
DynamoDB does have a filterexpression operation in its Question and Scan API to filter outcomes that don’t match an expression. The filterexpression is utilized solely after a question or scan desk operation so you might be nonetheless sure to the 1MB of information restrict for a question. That stated, the filterexpression is useful at simplifying the appliance logic, decreasing the response payload measurement and validating time-to-live expiry. In abstract, you’ll nonetheless have to partition your knowledge in line with the entry patterns of your utility or use secondary indexes to filter knowledge in DynamoDB.
DynamoDB organizes knowledge in keys and values for quick knowledge retrieval and isn’t splendid for advanced filtering. While you require advanced filters it’s possible you’ll need to transfer to a search engine like Elasticsearch as these programs are perfect for needle within the haystack queries.
In Elasticsearch, knowledge is saved in a search index which means the record of paperwork for which column-value is saved as a posting record. Any question that has a predicate (ie: WHERE consumer=A) can rapidly fetch the record of paperwork satisfying the predicate. Because the posting lists are sorted, they are often merged rapidly at question time so that every one filtering standards is met. Elasticsearch additionally makes use of easy caching to hurry up the retrieval means of ceaselessly accessed advanced filter queries.
Filter queries, generally known as non-scoring queries in Elasticsearch, can retrieve knowledge quicker and extra effectively than textual content search queries. That’s as a result of relevance will not be wanted for these queries. Moreover, Elasticsearch additionally helps vary queries making it doable to retrieve knowledge rapidly between an higher and decrease boundary (ie: age between 0-5).
Aggregations on DynamoDB Knowledge Utilizing Elasticsearch
Aggregations are when knowledge is gathered and expressed in a abstract kind for enterprise intelligence or pattern evaluation. For instance, it’s possible you’ll need to present utilization metrics in your utility in real-time.
DynamoDB doesn’t help combination capabilities. The workaround advisable by AWS is to make use of DynamoDB and Lambda to keep up an aggregated view of information in a DynamoDB desk.
Let’s use aggregating likes on a social media website like Twitter for instance. We’ll make the tweet_ID the first key after which the type key the time window by which we’re aggregating likes. On this case, we’ll allow DynamoDB streams and fix a Lambda operate in order that as tweets are appreciated (or disliked) they’re tabulated in like_count with a timestamp (ie: last_ up to date).
On this state of affairs, DynamoDB streams and Lambda capabilities are used to tabulate a like_count as an attribute on the desk.
Another choice is to dump aggregations to a different database, like Elasticsearch. Elasticsearch is a search index at its core and has added extensions to help aggregation capabilities. A type of extensions is doc values, a construction constructed at index time to retailer doc values in a column-oriented approach. The construction is utilized by default to fields that help doc values and there’s some storage bloat that comes with doc values. Should you solely require help for aggregations on DynamoDB knowledge, it might be cheaper to make use of an information warehouse that may compress knowledge effectively for analytical queries over broad datasets.
- Right here’s a high-level overview of Elasticsearch’s aggregation framework:
- Bucket aggregations: You may consider bucketing as akin to
GROUP BYon the planet of SQL databases. You may group paperwork based mostly on discipline values or ranges. Elasticsearch bucket aggregations additionally embody the nested aggregation and parent-child aggregation which can be widespread workarounds to the shortage of be a part of help. - Metric aggregations: Metrics permit you to carry out calculations like
SUM,COUNT,AVG,MIN,MAX, and so on. on a set of paperwork. Metrics can be used to calculate values for a bucket aggregation. - Pipeline aggregations: The inputs on pipeline aggregations are different aggregations fairly than paperwork. Widespread makes use of embody averages and sorting based mostly on a metric.
There might be efficiency implications when utilizing aggregations, particularly as you scale Elasticsearch.
Various to Elasticsearch for Search, Aggregations and Joins on DynamoDB
Whereas Elasticsearch is one resolution for doing advanced search and aggregations on knowledge from DynamoDB, many serverless proponents have echoed considerations with this selection. Engineering groups select DynamoDB as a result of it’s severless and can be utilized at scale with little or no operational overhead. We’ve evaluated a number of different choices for analytics on DynamoDB, together with Athena, Spark and Rockset on ease of setup, upkeep, question functionality and latency in one other weblog.
Rockset is an alternative choice to Elasticsearch and Alex DeBrie has walked via filtering and aggregating queries utilizing SQL on Rockset. Rockset is a cloud-native database with a built-in connector to DynamoDB, making it straightforward to get began and scale analytical use circumstances, together with use circumstances involving advanced joins. You may discover Rockset as an alternative choice to Elasticsearch in our free trial with $300 in credit.