

{kind=link}
Picture segmentation has change into a preferred know-how, with totally different fine-tuned fashions out there for varied functions. The mannequin labels each pixel in a picture by streaming each area of the enter picture; this idea makes the concept of semantic segmentation into actuality and software.
This Face parsing mannequin is a semantic segmentation know-how fine-tuned from Nvidia’s mit-b5 and Celebmask HQ. Its supposed use is for face parsing, which labels totally different areas in a picture, particularly the facial options.
It may well additionally detect objects and label them with pre-trained information. So, you may get labels for all the things from the background to the eyes, nostril, pores and skin, eyebrows, garments, hat, neck, hair, and different options.
Studying Goal
- Perceive the idea of face parsing as a semantic segmentation mannequin.
- Highlights some key factors about face parsing.
- Discover ways to run the face parsing mannequin.
- Get Perception into the real-life purposes of this mannequin.
This text was printed as part of the Knowledge Science Blogathon.
What’s Face Parsing?
Face parsing is a pc imaginative and prescient know-how that completes duties that assist in the face evaluation of an enter picture. This course of happens by pixel-segmenting the picture’s facial elements and different seen areas. With this picture segmentation job, customers can additional modify, analyze, and make the most of the purposes of this mannequin in varied methods.
Understanding the mannequin structure is a key idea of how this mannequin works. Though this course of has numerous pre-trained information, this mannequin’s imaginative and prescient transformer structure is extra environment friendly.
Mannequin Structure of Face Parsing Mannequin
This mannequin makes use of a transformer-based structure for semantic segmentation, which supplies basis for a way different comparable fashions like Segformer are constructed. Along with integrating the transformer system, it additionally focuses on a light-weight decoding mechanism when processing a picture.
Wanting on the key element of how this mechanism works, you see it consists of a transformer encoder, an MLP decoder, and no positioning embeddings. These are very important attributes of the working system of transformer fashions in picture segmentation.
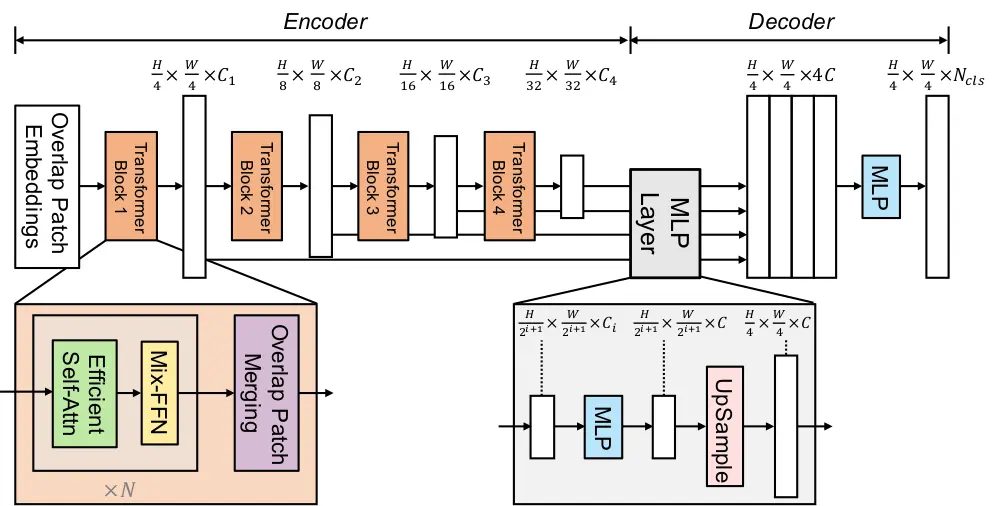
The transformer encoder is an important a part of the mechanism, serving to to extract multi-scale options from the enter picture. Thus, you possibly can seize the pictures with info on totally different spatial scales to enhance the mannequin’s effectivity.
The light-weight decoder is one other very important a part of this mannequin’s structure. It’s primarily based on a multi-layer notion decoder, enabling it to compile info from totally different layers of the transformer encoder. This mannequin can do that by using native and international consideration mechanisms; native consideration helps to acknowledge facial options, whereas international consideration ensures good protection of the facial construction.
This mechanism balances the mannequin’s efficiency and effectivity. Thus, this structure permits minimizing sources with out affecting the output.
No-position encoding is one other important a part of the face parsing structure, which has change into a staple in lots of pc imaginative and prescient and transformer fashions. This function is tailor-made to keep away from picture decision issues, even for photographs past a boundary. So, it maintains effectivity no matter positional codes.
General, the mannequin’s design performs effectively on customary face segmentation benchmarks. It’s efficient and might generalize throughout various face photographs, making it a sturdy selection for duties like facial recognition, avatar era, or AR filters. The mannequin maintains sharp boundaries between facial areas, an important requirement for correct face parsing.
Easy methods to Run the Face Parsing Mannequin
This part outlines the steps for operating this mannequin’s code with sources from the cuddling face library. The outcome would present the labels of every facial function that it will possibly acknowledge. You possibly can run this mannequin utilizing the inference API and libraries. So, let’s discover these strategies.
Operating Inference on the Face Parsing Utilizing Hugging Face
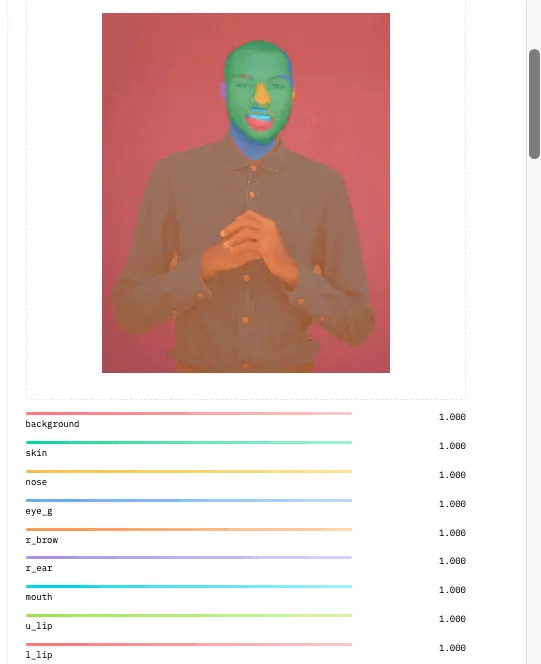
You need to use the inference API out there on hugging face to finish the face parsing duties. The mannequin’s inference API device takes a picture as enter, and the face parsing labels the elements of the face on the picture utilizing colours.
import requests
API_URL = "https://api-inference.huggingface.co/fashions/jonathandinu/face-parsing"
headers = {"Authorization": "Bearer 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"}
def question(filename):
with open(filename, "rb") as f:
information = f.learn()
response = requests.put up(API_URL, headers=headers, information=information)
return response.json()
output = question("/content material/IMG_20221108_073555.jpg")The code above begins with the request library to deal with HTTPS requests and talk with the API over net platforms. So, utilizing hugging face because the API, you may get authorization utilizing the token that may be created at no cost on the platform. Whereas the URL specifies the endpoint of the mannequin, the token is used for authentication when making requests to the cuddling face API.
The remainder of the code sends a picture file to the API and will get the outcomes. The question perform is named with a file that exhibits the situation of the picture. The perform sends the picture to the API and shops the response (JSON format) within the variable output.
outputSubsequent, you enter your ‘output.’ variable to point out the results of the inference.

Importing the Important Libraries
This code imports the required libraries for the picture segmentation job, utilizing Segformer as the bottom mannequin. It additionally brings a picture processor from the Transformers library to course of and run the Segformer mannequin. Then, it imports PIL to deal with picture loading and Matplotlib to visualise the segmentation outcomes. Lastly, requests are imported to fetch photographs from URLs.
import torch
from torch import nn
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
from PIL import Picture
import matplotlib.pyplot as plt
import requestsPartaking {Hardware}– GPU/CPU/
gadget = (
"cuda"
# Machine for NVIDIA or AMD GPUs
if torch.cuda.is_available()
else "mps"
# Machine for Apple Silicon (Steel Efficiency Shaders)
if torch.backends.mps.is_available()
else "cpu"
)
This code engages the out there {hardware} of the native gadget appropriate for operating this mannequin. As proven within the code, it assigns ‘cuda’ for NVIDIA or AMD GPUs and mps for Apple silicon gadgets. By default, this mannequin simply makes use of the CPU with out different out there {hardware}.
Loading the Processors
The code beneath masses the segformer picture processor and semantic segmentation mannequin, pre-trained on ‘jonathandinu/face-parsing’ with datasets for face parsing duties.
image_processor = SegformerImageProcessor.from_pretrained("jonathandinu/face-parsing")
mannequin = SegformerForSemanticSegmentation.from_pretrained("jonathandinu/face-parsing")
mannequin.to(gadget)The following step includes fetching the picture for the picture segmentation job. You are able to do this by importing the file or loading the URL of the picture as proven within the picture beneath;
url = "https://photographs.unsplash.com/photo-1539571696357-5a69c17a67c6"
picture = Picture.open(requests.get(url, stream=True).uncooked)
This code processes a picture utilizing the `image_processor,` changing it right into a PyTorch tensor and shifting it to the desired gadget (GPU, MPS, or CPU).
inputs = image_processor(photographs=picture, return_tensors="pt").to(gadget)
outputs = mannequin(**inputs)
logits = outputs.logits # form (batch_size, num_labels, ~top/4, ~width/4)The processed tensor is fed into the Segformer mannequin to generate segmentation outputs. The logits are extracted from the mannequin’s output, representing the uncooked scores for every pixel throughout totally different labels, with dimensions scaled down by 4 for top and width.
Output
To get the output, there are a couple of traces of code that can assist you show the picture outcomes. Firstly, you resize the output to make sure that it matches the scale of the picture enter. That is accomplished by utilizing linear interpolation to get a worth to estimate the factors of the picture dimension.
# resize output to match enter picture dimensions
upsampled_logits = nn.purposeful.interpolate(logits,
dimension=picture.dimension[::-1], # H x W
mode="bilinear",
align_corners=False)
Secondly, that you must run the label masks to assist the output worth within the class dimensions.
# get label masks
labels = upsampled_logits.argmax(dim=1)[0]
Lastly, you possibly can visualize the picture utilizing the ‘metaplotlib’ library.
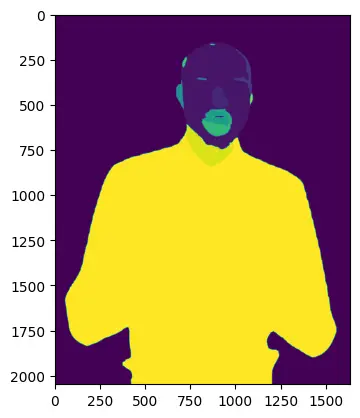
# transfer to CPU to visualise in matplotlib
labels_viz = labels.cpu().numpy()
plt.imshow(labels_viz)
plt.present()
The picture brings the labels of the facial options as proven beneath;
Actual-Life Utility of Face Parsing Mannequin
This mannequin has varied purposes throughout totally different industries with many comparable fine-tuned fashions already in use. Listed below are a few of the common purposes of face-parsing know-how;
- Safety: This mannequin has facial recognition capabilities, which permit it to establish folks by way of facial options. It may well additionally assist establish a listing of individuals allowed into an occasion or personal gathering whereas blocking unrecognized faces.
- Social media: Picture segmentation has change into rampant within the social media area, and this mannequin additionally brings worth to this trade. The mannequin can modify pores and skin tones and different facial options, which can be utilized to create magnificence results in photographs, movies, and on-line conferences.
- Leisure: Face parsing has an enormous affect on the leisure trade. Varied parsing attributes may help producers change the colours and tones in numerous positions of a picture. You possibly can analyze the picture, add ornaments, and modify some elements of a picture or video.
Conclusion
The face parsing mannequin is a robust semantic segmentation device designed to label and analyze facial options in photographs and movies precisely. This mannequin makes use of a transformer-based structure to effectively extract multi-scale options whereas making certain efficiency by way of a light-weight decoding mechanism and the absence of positional encodings.
Its versatility permits varied real-world purposes, from enhancing safety by way of facial recognition to offering superior picture modifying options in social media and leisure.
Key Takeaways
- Transformer-Based mostly Structure: This mechanism performs an important function within the effectivity and efficiency of this mannequin. Additionally, this method’s no positional encoding attribute avoids picture decision issues.
- Versatile Purposes: This mannequin will be utilized in numerous industries; safety, leisure, and social media areas can discover precious makes use of of face parsing know-how.
- Semantic Segmentation: By precisely segmenting each pixel associated to facial options, the mannequin facilitates detailed evaluation and manipulation of photographs, offering customers with precious insights and capabilities in face evaluation.
Sources
Continuously Requested Questions
A. Face parsing is a pc imaginative and prescient know-how that segments a picture into totally different facial options, labeling every space, such because the eyes, nostril, mouth, and pores and skin.
A. The mannequin processes enter photographs by way of a transformer-based structure that captures multi-scale options. That is adopted by a light-weight decoder that aggregates info to provide correct segmentation outcomes.
A. Key purposes embody safety (facial recognition), social media (photograph and video enhancements), and leisure (picture and video modifying).
A. The transformer structure permits for environment friendly picture processing, higher dealing with of various picture resolutions, and improved segmentation accuracy without having positional encoding.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.