

{kind=link}
Many enterprises have heterogeneous knowledge platforms and know-how stacks throughout completely different enterprise models or knowledge domains. For many years, they’ve been battling scale, velocity, and correctness required to derive well timed, significant, and actionable insights from huge and various large knowledge environments. Regardless of varied architectural patterns and paradigms, they nonetheless find yourself with perpetual “knowledge puddles” and silos in lots of non-interoperable knowledge codecs. Fixed knowledge duplication, advanced Extract, Remodel & Load (ETL) pipelines, and sprawling infrastructure results in prohibitively costly options, adversely impacting the Time to Worth, Time to Market, general Complete Value of Possession (TCO), and Return on Funding (ROI) for the enterprise.
Cloudera’s open knowledge lakehouse, powered by Apache Iceberg, solves the real-world large knowledge challenges talked about above by offering a unified, curated, shareable, and interoperable knowledge lake that’s accessible by a wide selection of Iceberg-compatible compute engines and instruments.
The Apache Iceberg REST Catalog takes this accessibility to the subsequent stage simplifying Iceberg desk knowledge sharing and consumption between heterogeneous knowledge producers and shoppers through an open customary RESTful API specification.
REST Catalog Worth Proposition
- It supplies open, metastore-agnostic APIs for Iceberg metadata operations, dramatically simplifying the Iceberg consumer and metastore/engine integration.
- It abstracts the backend metastore implementation particulars from the Iceberg shoppers.
- It supplies actual time metadata entry by instantly integrating with the Iceberg-compatible metastore.
- Apache Iceberg, along with the REST Catalog, dramatically simplifies the enterprise knowledge structure, decreasing the Time to Worth, Time to Market, and general TCO, and driving better ROI.
The Cloudera open knowledge lakehouse, powered by Apache Iceberg and the REST Catalog, now supplies the flexibility to share knowledge with non-Cloudera engines in a safe method.
With Cloudera’s open knowledge lakehouse, you possibly can enhance knowledge practitioner productiveness and launch new AI and knowledge functions a lot sooner with the next key options:
- Multi-engine interoperability and compatibility with Apache Iceberg, together with Cloudera DataFlow (NiFi), Cloudera Stream Analytics (Flink, SQL Stream Builder), Cloudera Knowledge Engineering (Spark), Cloudera Knowledge Warehouse (Impala, Hive), and Cloudera AI (previously Cloudera Machine Studying).
- Time Journey: Reproduce a question as of a given time or snapshot ID, which can be utilized for historic audits, validating ML fashions, and rollback of misguided operations, as examples.
- Desk Rollback: Allow customers to rapidly appropriate issues by rolling again tables to an excellent state.
- Wealthy set of SQL (question, DDL, DML) instructions: Create or manipulate database objects, run queries, load and modify knowledge, carry out time journey operations, and convert Hive exterior tables to Iceberg tables utilizing SQL instructions.
- In-place desk (schema, partition) evolution: Evolve Iceberg desk schema and partition format on the fly with out requiring knowledge rewriting, migration, or utility adjustments.
- Cloudera Shared Knowledge Expertise (SDX) Integration: Present unified safety, governance, and metadata administration, in addition to knowledge lineage and auditing on all of your knowledge.
- Iceberg Replication: Out-of-the-box catastrophe restoration and desk backup functionality.
- Straightforward portability of workloads between public cloud and personal cloud with none code refactoring.
Resolution Overview
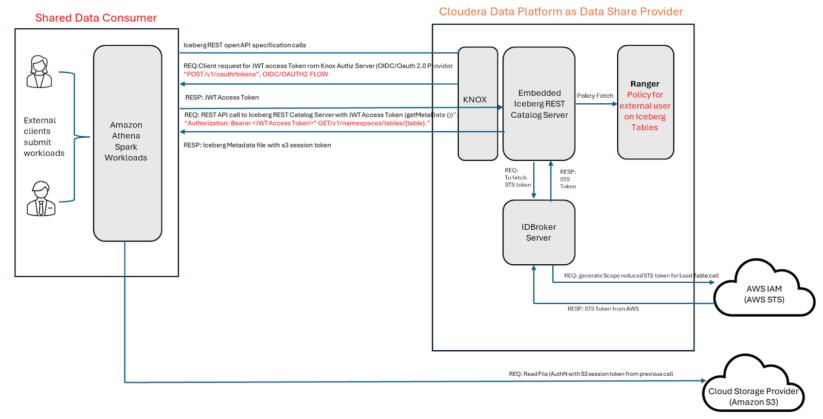
Knowledge sharing is the aptitude to share knowledge managed in Cloudera, particularly Iceberg tables, with exterior customers (shoppers) who’re exterior of the Cloudera surroundings. You may share Iceberg desk knowledge together with your shoppers who can then entry the info utilizing third occasion engines like Amazon Athena, Trino, Databricks, or Snowflake that assist Iceberg REST catalog.
The answer coated by this weblog describes how Cloudera shares knowledge with an Amazon Athena pocket book. Cloudera makes use of a Hive Metastore (HMS) REST Catalog service applied primarily based on the Iceberg REST Catalog API specification. This service will be made out there to your shoppers through the use of the OAuth authentication mechanism outlined by the
KNOX token administration system and utilizing Apache Ranger insurance policies for outlining the info shares for the shoppers. Amazon Athena will use the Iceberg REST Catalog Open API to execute queries in opposition to the info saved in Cloudera Iceberg tables.
Pre-requisites
The next elements in Cloudera on cloud ought to be put in and configured:
The next AWS stipulations:
- An AWS Account & an IAM position with permissions to create Athena Notebooks
On this instance, you will note the best way to use Amazon Athena to entry knowledge that’s being created and up to date in Iceberg tables utilizing Cloudera.
Please reference consumer documentation for set up and configuration of Cloudera Public Cloud.
Comply with the steps beneath to setup Cloudera:
1. Create Database and Tables:
Open HUE and execute the next to create a database and tables.
CREATE DATABASE IF NOT EXISTS airlines_data; DROP TABLE IF EXISTS airlines_data.carriers; CREATE TABLE airlines_data.carriers ( carrier_code STRING, carrier_description STRING) STORED BY ICEBERG TBLPROPERTIES ('format-version'='2'); DROP TABLE IF EXISTS airlines_data.airports; CREATE TABLE airlines_data.airports ( airport_id INT, airport_name STRING, metropolis STRING, nation STRING, iata STRING) STORED BY ICEBERG TBLPROPERTIES ('format-version'='2');
2. Load knowledge into Tables:
In HUE execute the next to load knowledge into every Iceberg desk.
INSERT INTO airlines_data.carriers (carrier_code, carrier_description) VALUES ("UA", "United Air Traces Inc."), ("AA", "American Airways Inc.") ; INSERT INTO airlines_data.airports (airport_id, airport_name, metropolis, nation, iata) VALUES (1, 'Hartsfield-Jackson Atlanta Worldwide Airport', 'Atlanta', 'USA', 'ATL'), (2, 'Los Angeles Worldwide Airport', 'Los Angeles', 'USA', 'LAX'), (3, 'Heathrow Airport', 'London', 'UK', 'LHR'), (4, 'Tokyo Haneda Airport', 'Tokyo', 'Japan', 'HND'), (5, 'Shanghai Pudong Worldwide Airport', 'Shanghai', 'China', 'PVG') ;
3. Question Carriers Iceberg desk:
In HUE execute the next question. You will note the two service data within the desk.
SELECT * FROM airlines_data.carriers;
4. Setup REST Catalog
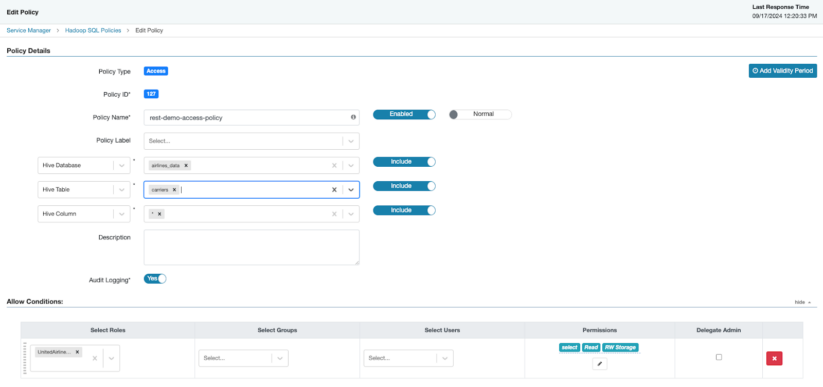
5. Setup Ranger Coverage to permit “rest-demo” entry for sharing:
Create a coverage that can permit the “rest-demo” position to have learn entry to the Carriers desk, however could have no entry to learn the Airports desk.
In Ranger go to Settings > Roles to validate that your Function is on the market and has been assigned group(s).
On this case I’m utilizing a task named – “UnitedAirlinesRole” that I can use to share knowledge.
Add a Coverage in Ranger > Hadoop SQL.
Create new Coverage with the next settings, remember to save your coverage
- Coverage Identify: rest-demo-access-policy
- Hive Database: airlines_data
- Hive Desk: carriers
- Hive Column: *
- In Enable Situations
- Choose your position below “Choose Roles”
- Permissions: choose
Comply with the steps beneath to create an Amazon Athena pocket book configured to make use of the Cloudera Iceberg REST Catalog:
6. Create an Amazon Athena pocket book with the “Spark_primary” Workgroup
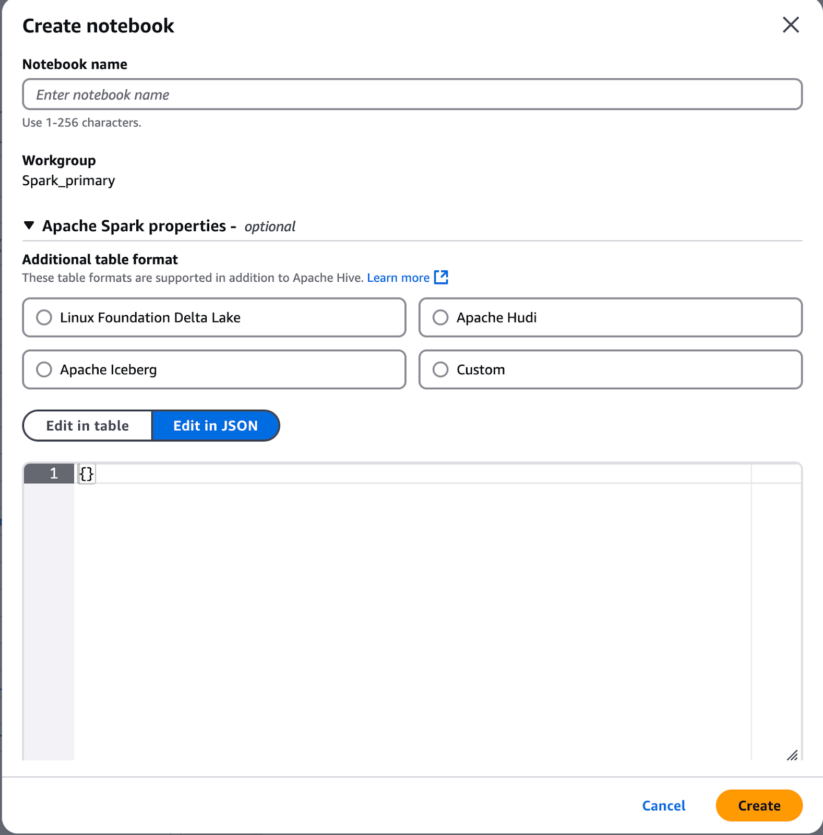
a. Present a reputation in your pocket book
b. Extra Apache Spark properties – it will allow use of the Cloudera Iceberg REST Catalog. Choose the “Edit in JSON” button. Copy the next and change <cloudera-knox-gateway-node>, <cloudera-env-name>, <client-id>, and <client-secret> with the suitable values. See REST Catalog Setup weblog to find out what values to make use of for substitute.
{ "spark.sql.catalog.demo": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.demo.default-namespace": "airways", "spark.sql.catalog.demo.kind": "relaxation", "spark.sql.catalog.demo.uri": "https://<cloudera-knox-gateway-node>/<cloudera-env-name>/cdp-share-access/hms-api/icecli", "spark.sql.catalog.demo.credential": "<client-id>:<client-secret>", "spark.sql.defaultCatalog": "demo", "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" }
c. Click on on the “Create” button, to create a brand new pocket book
7. Spark-sql Pocket book – execute instructions through the REST Catalog
Run the next instructions 1 at a time to see what is on the market from the Cloudera REST Catalog. It is possible for you to to:
- See the record of accessible databases
spark.sql(present databases).present();
- Swap to the airlines_data database
spark.sql(use airlines_data);
- See the out there tables (shouldn’t see the Airports desk within the returned record)
spark.sql(present tables).present();
- Question the Carriers desk to see the two Carriers presently on this desk
spark.sql(SELECT * FROM airlines_data.carriers).present()
Comply with the steps beneath to make adjustments to the Cloudera Iceberg desk & question the desk utilizing Amazon Athena:
8. Cloudera – Insert a brand new report into the Carriers desk:
In HUE execute the next so as to add a row to the Carriers desk.
INSERT INTO airlines_data.carriers VALUES("DL", "Delta Air Traces Inc.");
9. Cloudera – Question Carriers Iceberg desk:
In HUE and execute the next so as to add a row to the Carriers desk.
SELECT * FROM airlines_data.carriers;
10. Amazon Athena Pocket book – question subset of Airways (carriers) desk to see adjustments:
Execute the next question – it’s best to see 3 rows returned. This exhibits that the REST Catalog will robotically deal with any metadata pointer adjustments, guaranteeing that you’ll get the latest knowledge.
spark.sql(SELECT * FROM airlines_data.carriers).present()
11. Amazon Athena Pocket book – attempt to question Airports desk to check safety coverage is in place:
Execute the next question. This question ought to fail, as anticipated, and won’t return any knowledge from the Airports desk. The explanation for that is that the Ranger Coverage is being enforced and denies entry to this desk.
spark.sql(SELECT * FROM airlines_data.airports).present()
Conclusion
On this put up, we explored the best way to arrange an information share between Cloudera and Amazon Athena. We used Amazon Athena to attach through the Iceberg REST Catalog to question knowledge created and maintained in Cloudera.
Key options of the Cloudera open knowledge lakehouse embody:
- Multi-engine compatibility with varied Cloudera merchandise and different Iceberg REST suitable instruments.
- Time Journey and Desk Rollback for knowledge restoration and historic evaluation.
- Complete SQL assist and in-place schema evolution.
- Integration with Cloudera SDX for unified safety and governance.
- Iceberg replication for catastrophe restoration.
Amazon Athena is a serverless, interactive analytics service that gives a simplified and versatile approach to analyze petabytes of information the place it lives.. Amazon Athena additionally makes it simple to interactively run knowledge analytics utilizing Apache Spark with out having to plan for, configure, or handle assets. Whenever you run Apache Spark functions on Athena, you submit Spark code for processing and obtain the outcomes instantly. Use the simplified pocket book expertise in Amazon Athena console to develop Apache Spark functions utilizing Python or Use Athena pocket book APIs. The Iceberg REST Catalog integration with Amazon Athena permits organizations to leverage the scalability and processing energy of EMR Spark for large-scale knowledge processing, analytics, and machine studying workloads on massive datasets saved in Cloudera Iceberg tables.
For enterprises dealing with challenges with their various knowledge platforms, who is likely to be battling points associated to scale, velocity, and knowledge correctness, this answer can present important worth. This answer can cut back knowledge duplication points, simplify advanced ETL pipelines, and cut back prices, whereas bettering enterprise outcomes.
To be taught extra about Cloudera and the best way to get began, consult with Getting Began. Take a look at Cloudera’s open knowledge lakehouse to get extra details about the capabilities out there or go to Cloudera.com for particulars on every thing Cloudera has to supply. Confer with Getting Began with Amazon Athena