

{kind=link}
Again in August 2022, Sophos X-Ops revealed a white paper on a number of attackers – that’s, adversaries concentrating on the identical organizations a number of instances. One among our key suggestions in that analysis was to forestall repeated assaults by ‘prioritizing the worst bugs first’: patching crucial or high-profile vulnerabilities that might have an effect on customers’ particular software program stacks. Whereas we predict that is nonetheless good recommendation, prioritization is a fancy problem. How have you learnt what the worst bugs are? And the way do you truly prioritize remediation, provided that assets are roughly the identical however the variety of revealed CVEs per yr continues to extend, from 18,325 in 2020, to 25,277 in 2022, to 29,065 in 2023? And in keeping with latest analysis, the median remediation capability throughout organizations is 15% of open vulnerabilities in any given month.
A standard strategy is to prioritize patching by severity (or by danger, a distinction we’ll make clear later) utilizing CVSS scores. FIRST’s Widespread Vulnerabilities Scoring System has been round for a very long time, gives a numerical rating of vulnerability severity between 0.0 and 10.0, and isn’t solely extensively used for prioritization however mandated in some industries and governments, together with the Cost Card Trade (PCI) and elements of the US federal authorities.
As for the way it works, it’s deceptively easy. You plug in particulars a few vulnerability, and out comes a quantity which tells you whether or not the bug is Low, Medium, Excessive, or Vital. To date, so easy; you weed out the bugs that don’t apply to you, give attention to patching the Vital and Excessive vulnerabilities out of what’s left, and both patch the Mediums and Lows afterwards or settle for the danger. All the pieces is on that 0-10 scale, so in idea that is straightforward to do.
However there’s extra nuance to it than that. On this article, the primary of a two-part collection, we’ll check out what goes on beneath the hood of CVSS, and clarify why it isn’t essentially all that helpful for prioritization by itself. Within the second half, we’ll focus on some different schemes which might present a extra full image of danger to tell prioritization.
Earlier than we begin, an vital notice. Whereas we’ll focus on some points with CVSS on this article, we’re very aware that creating and sustaining a framework of this sort is tough work, and to some extent a thankless job. CVSS is available in for lots of criticism, some pertaining to inherent points with the idea, and a few to the methods wherein organizations use the framework. However we must always level out that CVSS will not be a business, paywalled software. It’s made free for organizations to make use of as they see match, with the intent of offering a helpful and sensible information to vulnerability severity and due to this fact serving to organizations to enhance their response to revealed vulnerabilities. It continues to bear enhancements, usually in response to exterior suggestions. Our motivation in writing these articles will not be in any approach to disparage the CVSS program or its builders and maintainers, however to offer further context and steering round CVSS and its makes use of, particularly on the subject of remediation prioritization, and to contribute to a wider dialogue round vulnerability administration.
CVSS is “a approach to seize the principal traits of a vulnerability and produce a numerical rating reflecting its severity,” in keeping with FIRST. That numerical rating, as talked about earlier, is between 0.0 and 10.0, giving 101 doable values; it will probably then be was a qualitative measure utilizing the next scale:
- None: 0.0
- Low: 0.1 – 3.9
- Medium: 4.0 – 6.9
- Excessive: 7.0 – 8.9
- Vital: 9.0 – 10.0
The system has been round since February 2005, when model 1 was launched; v2 got here out in June 2007, adopted by v3 in June 2015. v3.1, launched in June 2019, has some minor amendments from v3, and v4 was revealed on October 31, 2023. As a result of CVSS v4 has not but been extensively adopted as of this writing (e.g., the Nationwide Vulnerability Database (NVD) and plenty of distributors together with Microsoft are nonetheless predominantly utilizing v3.1), we are going to take a look at each variations on this article.
CVSS is the de facto normal for representing vulnerability severity. It seems on CVE entries within the NVD in addition to in varied different vulnerability databases and feeds. The concept is that it produces a single, standardized, platform-agnostic rating.
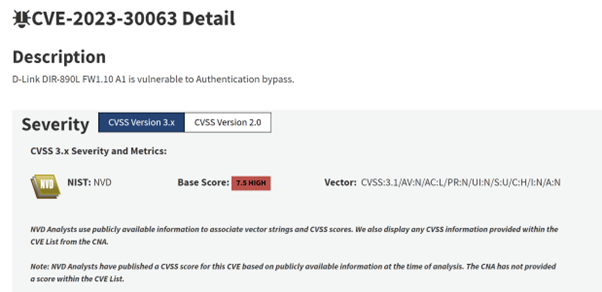
Determine 1: The entry for CVE-2023-30063 on the NVD. Word the v3.1 Base Rating (7.5, Excessive) and the vector string, which we’ll cowl in additional element shortly. Additionally notice that as of March 2024, the NVD doesn’t incorporate CVSS v4 scores
The determine most suppliers use is the Base Rating, which displays a vulnerability’s intrinsic properties and its potential impacts. Calculating a rating entails assessing a vulnerability through two sub-categories, every with its personal vectors which feed into the general equation.
The primary subcategory is Exploitability, which accommodates the next vectors (doable values are in brackets) in CVSS v4:
- Assault Vector (Community, Adjoining, Native, Bodily)
- Assault Complexity (Low, Excessive)
- Assault Necessities (None, Current)
- Privileges Required (None, Low, Excessive)
- Consumer Interplay (None, Passive, Energetic)
The second class is Affect. Every of the vectors under have the identical three doable values (Excessive, Low, and None):
- Susceptible System Confidentiality
- Subsequent System Confidentiality
- Susceptible System Integrity
- Subsequent System Integrity
- Susceptible System Availability
- Subsequent System Availability
So how can we get to an precise quantity after supplying these values? In v3.1, as proven in FIRST’s CVSS specification doc, the metrics (barely completely different to the v4 metrics listed above) have an related numerical worth:
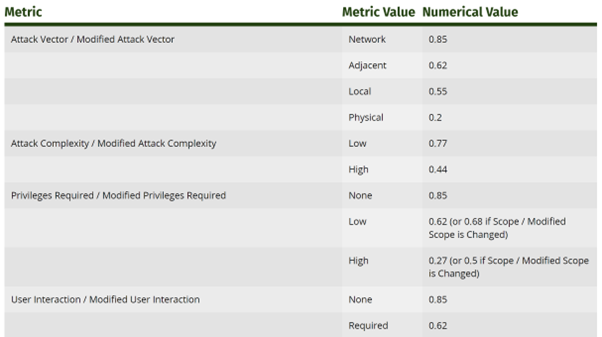
Determine 2: An excerpt from FIRST’s CVSS v3.1 documentation, exhibiting the numerical values of assorted metrics
To calculate the v3.1 Base rating, we first calculate three sub-scores: an Affect Sub-Rating (ISS), an Affect Rating (which makes use of the ISS), and an Exploitability Rating.
Affect Sub-Rating
1 – [(1 – Confidentiality) * (1 – Integrity) * (1 – Availability)]
Affect Rating
- If scope is unchanged, 42 * ISS
- If scope is modified, 52 * (ISS – 0.029) – 3.25 * (ISS – 0.02)15
Exploitability Rating
8.22 * AttackVector * AttackComplexity * PrivilegesRequired * UserInteraction
Base Rating
Assuming the Affect Rating is bigger than 0:
- If scope is unchanged: (Roundup (Minimal [(Impact + Exploitability), 10])
- If scope is modified: Roundup (Minimal [1.08 * (Impact + Exploitability), 10])
Right here, the equation makes use of two customized features, Roundup and Minimal. Roundup “returns the smallest quantity, specified to at least one decimal place, that is the same as or greater than its enter,” and Minimal “returns the smaller of its two arguments.”
On condition that CVSS is an open-source specification, we are able to work by an instance of this manually, utilizing the v3.1 vector string for CVE-2023-30063 proven in Determine 1:
CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:N/A:N
We’ll search for the vector outcomes and their related numerical values, so we all know what numbers to plug into the equations:
- Assault Vector = Community = 0.85
- Assault Complexity = Low = 0.77
- Privileges Required = None = 0.85
- Consumer Interplay = None = 0.85
- Scope = Unchanged (no related worth in itself; as an alternative, Scope can modify different vectors)
- Confidentiality = Excessive = 0.56
- Integrity = None = 0
- Availability = None = 0
First, we calculate the ISS:
1 – [(1 – 0.56) * (1 – 0) * (1 – 0] = 0.56
The Scope is unchanged, so for the Affect rating we multiply the ISS by 6.42, which provides us 3.595.
The Exploitability rating is 8.22 * 0.85 * 0.77 * 0.85 * 0.85, which provides us 3.887.
Lastly, we put this all into the Base Rating equation, which successfully provides these two scores collectively, giving us 7.482. To 1 decimal place that is 7.5, as per the CVSS v3.1 rating on NVD, which implies this vulnerability is taken into account to be Excessive severity.
v4 takes a really completely different strategy. Amongst different modifications, the Scope metric has been retired; there’s a new Base metric (Assault Necessities); and the Consumer Interplay now has extra granular choices. However probably the most radical change is the scoring system. Now, the calculation methodology not depends on ‘magic numbers’ or a system. As a substitute, ‘equivalence units’ of various combos of values have been ranked by consultants, compressed, and put into bins representing scores. When calculating a CVSS v4 rating, the vector is computed and the related rating returned, utilizing a lookup desk. So, for instance, a vector of 202001 has an related rating of 6.4 (Medium).
Whatever the calculation methodology, the Base Rating isn’t supposed to vary over time, because it depends on traits inherent to the vulnerability. Nonetheless, the v4 specification additionally affords three different metric teams: Menace (the traits of a vulnerability that change over time); Environmental (traits which might be distinctive to a consumer’s setting); and Supplemental (further extrinsic attributes).
The Menace Metric Group consists of just one metric (Exploit Maturity); this replaces the Temporal Metric Group from v3.1, which included metrics for Exploit Code Maturity, Remediation Stage, and Report Confidence. The Exploit Maturity metric is designed to replicate the chance of exploitation, and has 4 doable values:
- Not Outlined
- Attacked
- Proof-of-Idea
- Unreported
Whereas the Menace Metric Group is designed so as to add further context to a Base rating based mostly on menace intelligence, the Environmental Metric Group is extra of a variation of the Base rating, permitting a company to customise the rating “relying on the significance of the affected IT asset to a consumer’s group.” This metric accommodates three sub-categories (Confidentiality Requirement, Integrity Requirement, and Availability Requirement), plus the modified Base metrics. The values and definitions are the identical because the Base metrics, however the modified metrics enable customers to replicate mitigations and configurations which can enhance or lower severity. For instance, the default configuration of a software program element won’t implement authentication, so a vulnerability in that element would have a Base metric of None for the Privileges Required measure. Nonetheless, a company might need protected that element with a password of their setting, wherein case the Modified Privileges Required can be both Low or Excessive, and the general Environmental rating for that group would due to this fact be decrease than the Base rating.
Lastly, the Supplemental Metric Group consists of the next non-compulsory metrics, which don’t have an effect on the rating.
- Automatable
- Restoration
- Security
- Worth Density
- Vulnerability Response Effort
- Supplier Urgency
It stays to be seen how extensively used the Menace and Supplemental Metric Teams can be in v4. With v3.1, Temporal metrics hardly ever seem on vulnerability databases and feeds, and Environmental metrics are supposed for use on a per-infrastructure foundation, so it’s not clear how extensively adopted they’re.
Nonetheless, Base scores are ubiquitous, and at first look it’s not arduous to see why. Though so much has modified in v4, the basic nature of the result – a determine between 0.0 and 10.0, which purportedly displays a vulnerability’s severity – is similar.
The system has, nonetheless, are available in for some criticism.
What does a CVSS rating imply?
This isn’t an issue inherent to the CVSS specification, however there will be some confusion as to what a CVSS rating truly means, and what it ought to be used for. As Howland factors out, the specification for CVSS v2 is obvious that the framework’s goal is danger administration:
“At the moment, IT administration should determine and assess vulnerabilities throughout many disparate {hardware} and software program platforms. They should prioritize these vulnerabilities and remediate those who pose the best danger. However when there are such a lot of to repair, with every being scored utilizing completely different scales, how can IT managers convert this mountain of vulnerability information into actionable info? The Widespread Vulnerability Scoring System (CVSS) is an open framework that addresses this problem.”
The phrase ‘danger’ seems 21 instances within the v2 specification; ‘severity’ solely three. By the v4 specification, these numbers have successfully reversed; ‘danger’ seems 3 times, and ‘severity’ 41 instances. The primary sentence of the v4 specification states that the aim of the framework is “speaking the traits and severity of software program vulnerabilities.” So, sooner or later, the acknowledged goal of CVSS has modified, from a measure of danger to a measure of severity.
That’s not a ‘gotcha’ in any means; the authors might have merely determined to make clear precisely what CVSS is for, to forestall or tackle misunderstandings. The actual problem right here doesn’t lie within the framework itself, however in the best way it’s generally applied. Regardless of the clarifications in latest specs, CVSS scores should generally be (mis)used as a measure of danger (i.e., “the mixture of the chance of an occasion and its penalties,” or, as per the oft-cited system, Menace * Vulnerability * Consequence), however they don’t truly measure danger in any respect. They measure one side of danger, in assuming that an attacker “has already situated and recognized the vulnerability,” and in assessing the traits and potential influence of that vulnerability if an exploit is developed, and if that exploit is efficient, and if the cheap worst-case situation happens consequently.
A CVSS rating generally is a piece of the puzzle, however under no circumstances the finished jigsaw. Whereas it could be good to have a single quantity on which to base choices, danger is a much more complicated sport.
However I can nonetheless use it for prioritization, proper?
Sure and no. Regardless of the growing numbers of revealed CVEs (and it’s price declaring that not all vulnerabilities obtain CVE IDs, in order that’s not a accomplished jigsaw both), solely a small fraction – between 2% and 5% – are ever detected as being exploited in-the-wild, in keeping with analysis. So, if a vulnerability intelligence feed tells you that 2,000 CVEs have been revealed this month, and 1,000 of them have an effect on property in your group, solely round 20-50 of these will probably ever be exploited (that we’ll learn about).
That’s the excellent news. However, leaving apart any exploitation that happens earlier than a CVE’s publication, we don’t know which CVEs menace actors will exploit sooner or later, or when – so how can we all know which vulnerabilities to patch first? One may assume that menace actors use an analogous thought course of to CVSS, albeit much less formalized, to develop, promote, and use exploits: emphasizing high-impact vulnerabilities with low complexity. Wherein case, prioritizing excessive CVSS scores for remediation makes good sense.
However researchers have proven that CVSS (not less than, as much as v3) is an unreliable predictor of exploitability. Again in 2014, researchers on the College of Trento claimed that “fixing a vulnerability simply because it was assigned a excessive CVSS rating is equal to randomly selecting vulnerabilities to repair,” based mostly on an evaluation of publicly accessible information on vulnerabilities and exploits. Extra lately (March 2023), Howland’s analysis on CVSS exhibits that bugs with a CVSS v3 rating of seven are the almost definitely to be weaponized, in a pattern of over 28,000 vulnerabilities. Vulnerabilities with scores of 5 had been extra more likely to be weaponized than these with scores of 6, and 10-rated vulnerabilities – Vital flaws – had been much less more likely to have exploits developed for them than vulnerabilities ranked as 9 or 8.
In different phrases, there doesn’t look like a correlation between CVSS rating and the chance of exploitation, and, in keeping with Howland, that’s nonetheless the case even when we weight related vectors – like Assault Complexity or Assault Vector – extra closely (though it stays to be seen if this can nonetheless maintain true with CVSS v4).
It is a counterintuitive discovering. Because the authors of the Exploit Prediction Scoring System (EPSS) level out (extra on EPSS in our follow-up article), after plotting CVSS scores in opposition to EPSS scores and discovering much less correlation than anticipated:
“this…gives suggestive proof that attackers are usually not solely concentrating on vulnerabilities that produce the best influence, or are essentially simpler to take advantage of (reminiscent of for instance, an unauthenticated distant code execution).”
There are numerous the explanation why the belief that attackers are most fascinated about exploiting exploits for extreme, low-effort vulnerabilities doesn’t maintain up. As with danger, the legal ecosystem can’t be diminished to a single aspect. Different components which could have an effect on the chance of weaponization embody the set up base of the affected product; prioritizing sure impacts or product households over others; variations by crime kind and motivation; geography, and so forth. It is a complicated, and separate, dialogue, and out of scope for this text – however, as Jacques Chester argues in an intensive and thought-provoking weblog put up on CVSS, the primary takeaway is: “Attackers don’t seem to make use of CVSSv3.1 to prioritize their efforts. Why ought to defenders?” Word, nonetheless, that Chester doesn’t go as far as to argue that CVSS shouldn’t be used in any respect. However it in all probability shouldn’t be the only think about prioritization.
Reproducibility
One of many litmus checks for a scoring framework is that, given the identical info, two individuals ought to be capable of work by the method and are available out with roughly the identical rating. In a subject as complicated as vulnerability administration, the place subjectivity, interpretation, and technical understanding usually come into play, we’d fairly count on a level of deviation – however a 2018 research confirmed important discrepancies in assessing the severity of vulnerabilities utilizing CVSS metrics, even amongst safety professionals, which might end in a vulnerability being finally labeled as Excessive by one analyst and Vital or Medium by one other.
Nonetheless, as FIRST factors out in its specification doc, its intention is that CVSS Base scores ought to be calculated by distributors or vulnerability analysts. In the true world, Base scores usually seem on public feeds or databases which organizations then ingest – they’re not supposed to be recalculated by a lot of particular person analysts. That’s reassuring, though the truth that skilled safety professionals made, in some instances not less than, fairly completely different assessments might be a trigger for concern. It’s not clear whether or not that was a consequence of ambiguity in CVSS definitions, or an absence of CVSS scoring expertise among the many research’s individuals, or a wider problem regarding divergent understanding of safety ideas, or some or all the above. Additional analysis might be wanted on this level, and on the extent to which this problem nonetheless applies in 2024, and to CVSS v4.
Hurt
CVSS v3.1’s influence metrics are restricted to these related to conventional vulnerabilities in conventional environments: the acquainted CIA triad. What v3.1 doesn’t consider are newer developments in safety, the place assaults in opposition to programs, gadgets, and infrastructure could cause important bodily hurt to individuals and property.
Nonetheless, v4 does tackle this problem. It features a devoted Security metric, with the next doable values:
- Not Outlined
- Current
- Negligible
With the latter two values, the framework makes use of the IEC 61508 normal definitions of “negligible” (minor accidents at worst), “marginal” (main accidents to a number of individuals), “crucial” (lack of a single life), or “catastrophic” (a number of lack of life). The Security metric may also be utilized to the modified Base metrics throughout the Environmental Metric Group, for the Subsequent System Affect set.
Context is the whole lot
CVSS does its greatest to maintain the whole lot so simple as doable, which might generally imply decreasing complexity. Take v4’s Assault Complexity, for instance; the one two doable values are Low and Excessive.
Low: “The attacker should take no measurable motion to take advantage of the vulnerability. The assault requires no target-specific circumvention to take advantage of the vulnerability. An attacker can count on repeatable success in opposition to the weak system.”
Excessive: “The profitable assault is determined by the evasion or circumvention of security-enhancing methods in place that may in any other case hinder the assault […].”
Some menace actors, vulnerability analysts, and distributors would probably disagree with the view {that a} vulnerability is both of ‘low’ or ‘excessive’ complexity. Nonetheless, members of the FIRST Particular Curiosity Group (SIG) declare that this has been addressed in v4 with the brand new Assault Necessities metric, which provides some granularity to the combo by capturing whether or not exploitation requires sure circumstances.
Consumer Interplay is one other instance. Whereas the doable values for this metric are extra granular in v4 than v3.1 (which has solely None or Required), the excellence between Passive (restricted and involuntary interplay) and Energetic (particular and aware interplay) arguably fails to replicate the wide selection of social engineering which happens in the true world, to not point out the complexity added by safety controls. As an example, persuading a consumer to open a doc (or simply view it within the Preview Pane) is typically simpler than persuading them to open a doc, then disable Protected View, then ignore a safety warning.
In equity, CVSS should stroll a line between being overly granular (i.e., together with so many doable values and variables that it will take an inordinate period of time to calculate scores) and overly simplistic. Making the CVSS mannequin extra granular would complicate what’s supposed to be a fast, sensible, one-size-fits-all information to severity. That being stated, it’s nonetheless the case that vital nuance could also be missed – and the vulnerability panorama is, by nature, usually a nuanced one.
A number of the definitions in each the v3.1 and v4 specs can also be complicated to some customers. As an example, take into account the next, which is supplied as a doable situation beneath the Assault Vector (Native) definition:
“the attacker exploits the vulnerability by accessing the goal system regionally (e.g., keyboard, console), or by terminal emulation (e.g., SSH)” [emphasis added; in the v3.1 specification, this reads “or remotely (e.g., SSH)”]
Word that using SSH right here seems to be distinct from accessing a number on a neighborhood community through SSH, as per the Adjoining definition:
“This could imply an assault have to be launched from the identical shared proximity (e.g., Bluetooth, NFC, or IEEE 802.11) or logical (e.g., native IP subnet) community, or from inside a safe or in any other case restricted administrative area…” [emphasis added]
Whereas the specification does make a distinction between a weak element being “certain to the community stack” (Community) or not (Native), this might be counterintuitive or complicated to some customers, both when calculating CVSS scores or making an attempt to interpret a vector string. That’s to not say these definitions are incorrect, solely that they is likely to be opaque and unintuitive to some customers.
Lastly, Howland gives a real-world case research of, of their view, CVSS scores not taking context into consideration. CVE-2014-3566 (the POODLE vulnerability) has a CVSS v3 rating of three.4 (Low). However it affected nearly one million web sites on the time of disclosure, prompted a big quantity of alarm, and impacted completely different organizations in numerous methods – which, Howland argues, CVSS doesn’t consider. There’s additionally a separate context-related query – out of scope for this collection – on whether or not media protection and hype a few vulnerability disproportionately affect prioritization. Conversely, some researchers have argued that vulnerability rankings will be overly excessive as a result of they don’t all the time take context into consideration, when the real-world danger is definitely comparatively low.
‘We’re simply ordinally individuals…’
In v3.1, CVSS generally makes use of ordinal information as enter into equations. Ordinal information is information on a ranked scale, with no identified distance between objects (e.g., None, Low, Excessive), and, as researchers from Carnegie Mellon College level out, it doesn’t make sense so as to add or multiply ordinal information objects. If, for example, you’re finishing a survey the place the responses are on a Likert scale, it’s meaningless to multiply or add these responses. To present a non-CVSS instance, when you reply Pleased [4.0] to a query about your wage, and Considerably Pleased [2.5] to a query about your work-life stability, you’ll be able to’t multiply these collectively and conclude that the general survey consequence = 10.0 [‘Very happy with my job’].
The usage of ordinal information additionally implies that CVSS scores shouldn’t be averaged. If an athlete wins a gold medal in a single occasion, for instance, and a bronze medal in one other, it doesn’t make sense to say that on common they gained silver.
In v3.1, it’s additionally not clear how the metrics’ hardcoded numerical values had been chosen, which can be one of many causes for FIRST opting to eschew a system in v4. As a substitute, v4’s scoring system depends on grouping and rating doable combos of values, calculating a vector, and utilizing a lookup operate to assign a rating. So, as an alternative of a system, consultants chosen by FIRST have decided the severity of various combos of vectors throughout a session interval. On the face of it, this looks like an affordable strategy, because it negates the difficulty of a system altogether.
A black field?
Whereas the specification, equations, and definitions for v3.1 and v4 are publicly accessible, some researchers have argued that CVSS suffers from an absence of transparency. In v4, for instance, somewhat than plugging numbers right into a system, analysts can now search for a vector utilizing a predetermined record. Nonetheless, it’s not clear how these consultants had been chosen, how they in contrast “vectors representing every equivalence set,” or how the “professional comparability information” was used “to calculate the order of vectors from least extreme to most extreme.” To our data, this info has not been made public. As we’ll see in Half 2 of this collection, this problem will not be distinctive to CVSS.
As with something in safety, any outcomes produced by a system wherein the underlying mechanics are usually not totally identified or understood ought to be handled with a level of skepticism commensurate with the significance and nature of the aim for which they’re used – and with the extent of related danger if these outcomes ought to show to be mistaken or deceptive.
Capping it off
Lastly, it could be price questioning why CVSS scores are between 0 and 10 in any respect. The plain reply is that this can be a easy scale which is straightforward to know, but it surely’s additionally arbitrary, particularly because the inputs to the equations are qualitative and CVSS will not be a chance measure. In v3.1, the Minimal operate ensures that scores are capped at 10 (with out it, it’s doable for a Base rating to succeed in 10.73, not less than by our calculations) – and in v4, the vectoring mechanism caps scores at 10 by design, as a result of it’s the best ‘bin.’
However is there a most extent to which a vulnerability will be extreme? Are all vulnerabilities which rating 10.0 equally dangerous? Seemingly this selection was made for human readability – however is it at the price of an correct and life like illustration of severity?
A fast, if imperfect, thought experiment: Think about a scoring system that claims to measure the severity of organic viruses. The scores can let you know concerning the doable influence a virus might need on individuals, even perhaps one thing concerning the potential menace of the virus based mostly on a few of its traits (e.g., an airborne virus is more likely to be a extra widespread menace than a virus that may solely be transmitted through ingestion or bodily contact, albeit not essentially a extra extreme one).
After inputting details about the virus into an equation, the system generates a really easy-to-understand numerical rating between 0 and 10. Elements of the healthcare sector use these scores to prioritize their responses to viruses, and a number of the common public depend on them as an indicator of danger – despite the fact that that’s not what the system’s builders advise.
However what the scores can’t let you know is how a virus will influence you personally, based mostly in your age, well being, immune system effectivity, co-morbidities, immunity through earlier an infection, and so forth. They will’t let you know how probably you’re to get contaminated, or how lengthy it would take you to recuperate. They don’t take into account all the viruses’ properties (replication price and talent to mutate, for example, or geographic distribution of reservoirs and infections) or take wider context into consideration, reminiscent of whether or not there are vaccines or preventative measures accessible. Consequently, a number of the scores appear to make sense (HIV ranks greater than a typical rhinovirus, for instance), however others don’t (poliovirus scores extremely due to its doable impacts, regardless of being nearly eradicated in many of the world). And unbiased empirical analysis has proven that the system’s scores are usually not useful in predicting morbidity charges.
So, must you rely solely on this method for conducting private danger assessments – say, when deciding to attend a celebration, or go on vacation, or go to somebody in hospital? Ought to the medical group depend on it to prioritize medical analysis and epidemiological efforts?
Intuitively, most individuals would probably have some doubts; it’s clear that the system has some flaws. Nonetheless, it’s actually not redundant. It’s useful for categorization, and for highlighting doable threats based mostly on a virus’s intrinsic properties, as a result of its scores let you know one thing concerning the potential penalties of an infection. It’s helpful, for instance, to know that rabies is inherently extra extreme than chickenpox, even when you’re unlikely to contract rabies in your subsequent evening out. You might actually take this method’s scores into consideration when conducting a danger evaluation, together with different info. However you’d additionally need extra info.
And, in equity, FIRST makes this level in its FAQ doc for v4. In discussing different scoring programs, it notes that they “can be utilized in live performance to raised assess, predict, and make knowledgeable choices on vulnerability response precedence.” Within the subsequent article, we’ll focus on a few of these different programs.