

{kind=link}
Retrieval-Augmented Technology (RAG) is an method to constructing AI programs that mixes a language mannequin with an exterior information supply. In easy phrases, the AI first searches for related paperwork (like articles or webpages) associated to a person’s question, after which makes use of these paperwork to generate a extra correct reply. This technique has been celebrated for serving to massive language fashions (LLMs) keep factual and scale back hallucinations by grounding their responses in actual information.
Intuitively, one may suppose that the extra paperwork an AI retrieves, the higher knowledgeable its reply will likely be. Nonetheless, latest analysis suggests a shocking twist: in terms of feeding info to an AI, typically much less is extra.
Fewer Paperwork, Higher Solutions
A new research by researchers on the Hebrew College of Jerusalem explored how the quantity of paperwork given to a RAG system impacts its efficiency. Crucially, they stored the whole quantity of textual content fixed – that means if fewer paperwork had been supplied, these paperwork had been barely expanded to fill the identical size as many paperwork would. This manner, any efficiency variations could possibly be attributed to the amount of paperwork quite than merely having a shorter enter.
The researchers used a question-answering dataset (MuSiQue) with trivia questions, every initially paired with 20 Wikipedia paragraphs (only some of which really comprise the reply, with the remainder being distractors). By trimming the variety of paperwork from 20 down to simply the two–4 actually related ones – and padding these with a bit of additional context to take care of a constant size – they created eventualities the place the AI had fewer items of fabric to think about, however nonetheless roughly the identical whole phrases to learn.
The outcomes had been putting. Usually, the AI fashions answered extra precisely once they got fewer paperwork quite than the complete set. Efficiency improved considerably – in some cases by as much as 10% in accuracy (F1 rating) when the system used solely the handful of supporting paperwork as an alternative of a big assortment. This counterintuitive increase was noticed throughout a number of completely different open-source language fashions, together with variants of Meta’s Llama and others, indicating that the phenomenon is just not tied to a single AI mannequin.
One mannequin (Qwen-2) was a notable exception that dealt with a number of paperwork and not using a drop in rating, however nearly all of the examined fashions carried out higher with fewer paperwork general. In different phrases, including extra reference materials past the important thing related items really harm their efficiency extra typically than it helped.
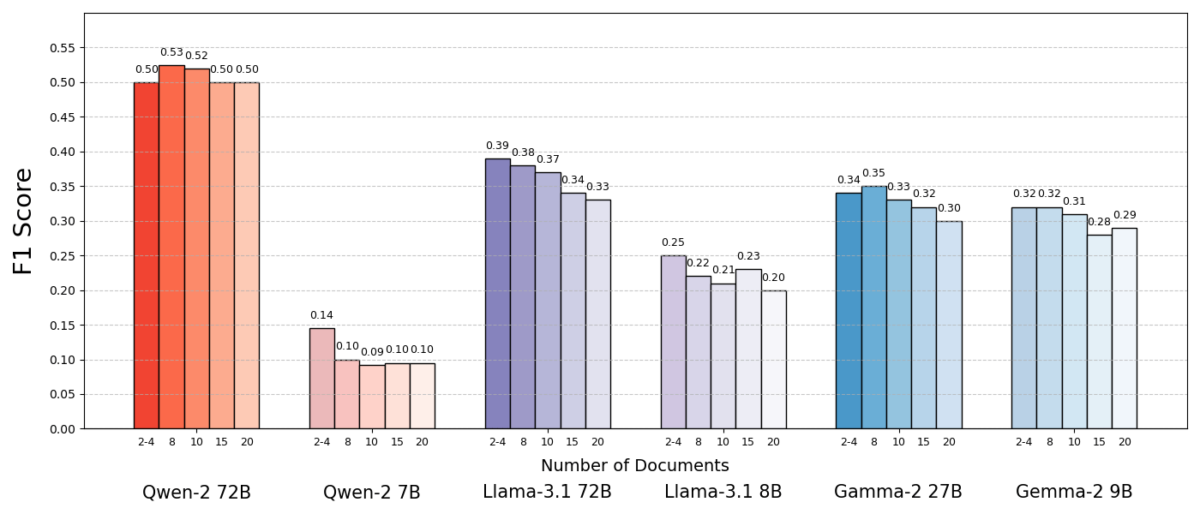
Supply: Levy et al.
Why is that this such a shock? Sometimes, RAG programs are designed underneath the idea that retrieving a broader swath of knowledge can solely assist the AI – in spite of everything, if the reply isn’t within the first few paperwork, it is likely to be within the tenth or twentieth.
This research flips that script, demonstrating that indiscriminately piling on further paperwork can backfire. Even when the whole textual content size was held fixed, the mere presence of many alternative paperwork (every with their very own context and quirks) made the question-answering job more difficult for the AI. It seems that past a sure level, every further doc launched extra noise than sign, complicated the mannequin and impairing its skill to extract the right reply.
Why Much less Can Be Extra in RAG
This “much less is extra” end result is sensible as soon as we think about how AI language fashions course of info. When an AI is given solely essentially the most related paperwork, the context it sees is targeted and freed from distractions, very similar to a pupil who has been handed simply the fitting pages to check.
Within the research, fashions carried out considerably higher when given solely the supporting paperwork, with irrelevant materials eliminated. The remaining context was not solely shorter but in addition cleaner – it contained details that straight pointed to the reply and nothing else. With fewer paperwork to juggle, the mannequin might dedicate its full consideration to the pertinent info, making it much less more likely to get sidetracked or confused.
Then again, when many paperwork had been retrieved, the AI needed to sift by a mixture of related and irrelevant content material. Usually these further paperwork had been “comparable however unrelated” – they could share a subject or key phrases with the question however not really comprise the reply. Such content material can mislead the mannequin. The AI may waste effort attempting to attach dots throughout paperwork that don’t really result in an accurate reply, or worse, it’d merge info from a number of sources incorrectly. This will increase the chance of hallucinations – cases the place the AI generates a solution that sounds believable however is just not grounded in any single supply.
In essence, feeding too many paperwork to the mannequin can dilute the helpful info and introduce conflicting particulars, making it tougher for the AI to resolve what’s true.
Curiously, the researchers discovered that if the additional paperwork had been clearly irrelevant (for instance, random unrelated textual content), the fashions had been higher at ignoring them. The actual bother comes from distracting information that appears related: when all of the retrieved texts are on comparable matters, the AI assumes it ought to use all of them, and it could battle to inform which particulars are literally necessary. This aligns with the research’s commentary that random distractors precipitated much less confusion than lifelike distractors within the enter. The AI can filter out blatant nonsense, however subtly off-topic info is a slick lure – it sneaks in underneath the guise of relevance and derails the reply. By lowering the variety of paperwork to solely the actually vital ones, we keep away from setting these traps within the first place.
There’s additionally a sensible profit: retrieving and processing fewer paperwork lowers the computational overhead for a RAG system. Each doc that will get pulled in must be analyzed (embedded, learn, and attended to by the mannequin), which makes use of time and computing sources. Eliminating superfluous paperwork makes the system extra environment friendly – it could actually discover solutions quicker and at decrease value. In eventualities the place accuracy improved by specializing in fewer sources, we get a win-win: higher solutions and a leaner, extra environment friendly course of.

Supply: Levy et al.
Rethinking RAG: Future Instructions
This new proof that high quality typically beats amount in retrieval has necessary implications for the way forward for AI programs that depend on exterior information. It means that designers of RAG programs ought to prioritize good filtering and rating of paperwork over sheer quantity. As an alternative of fetching 100 potential passages and hoping the reply is buried in there someplace, it could be wiser to fetch solely the highest few extremely related ones.
The research’s authors emphasize the necessity for retrieval strategies to “strike a stability between relevance and variety” within the info they provide to a mannequin. In different phrases, we need to present sufficient protection of the subject to reply the query, however not a lot that the core details are drowned in a sea of extraneous textual content.
Transferring ahead, researchers are more likely to discover strategies that assist AI fashions deal with a number of paperwork extra gracefully. One method is to develop higher retriever programs or re-rankers that may establish which paperwork actually add worth and which of them solely introduce battle. One other angle is enhancing the language fashions themselves: if one mannequin (like Qwen-2) managed to deal with many paperwork with out shedding accuracy, analyzing the way it was skilled or structured might provide clues for making different fashions extra sturdy. Maybe future massive language fashions will incorporate mechanisms to acknowledge when two sources are saying the identical factor (or contradicting one another) and focus accordingly. The aim could be to allow fashions to make the most of a wealthy number of sources with out falling prey to confusion – successfully getting the perfect of each worlds (breadth of knowledge and readability of focus).
It’s additionally price noting that as AI programs achieve bigger context home windows (the power to learn extra textual content directly), merely dumping extra information into the immediate isn’t a silver bullet. Greater context doesn’t routinely imply higher comprehension. This research exhibits that even when an AI can technically learn 50 pages at a time, giving it 50 pages of mixed-quality info could not yield a very good end result. The mannequin nonetheless advantages from having curated, related content material to work with, quite than an indiscriminate dump. The truth is, clever retrieval could change into much more essential within the period of large context home windows – to make sure the additional capability is used for priceless information quite than noise.
The findings from “Extra Paperwork, Similar Size” (the aptly titled paper) encourage a re-examination of our assumptions in AI analysis. Typically, feeding an AI all the information we now have is just not as efficient as we expect. By specializing in essentially the most related items of knowledge, we not solely enhance the accuracy of AI-generated solutions but in addition make the programs extra environment friendly and simpler to belief. It’s a counterintuitive lesson, however one with thrilling ramifications: future RAG programs is likely to be each smarter and leaner by rigorously selecting fewer, higher paperwork to retrieve.