

{kind=link}
As enterprises construct agent methods to ship top quality AI apps, we proceed to ship optimizations to ship greatest general cost-efficiency for our clients. We’re excited to announce the provision of the Meta Llama 3.3 mannequin on the Databricks Information Intelligence Platform, and vital updates to Mosaic AI’s Mannequin Serving pricing and effectivity. These updates collectively will cut back your inference prices by as much as 80%, making it considerably less expensive than earlier than for enterprises constructing AI brokers or doing batch LLM processing.
- 80% Value Financial savings: Obtain vital price financial savings with the brand new Llama 3.3 mannequin and lowered pricing.
- Sooner Inference Speeds: Get 40% quicker responses and lowered batch processing time, enabling higher buyer experiences and quicker insights.
- Entry to the brand new Meta Llama 3.3 mannequin: leverage the newest from Meta to attain better high quality and efficiency.
Construct Enterprise AI Brokers with Mosaic AI and Llama 3.3
We’re proud to accomplice with Meta to deliver Llama 3.3 70B to Databricks. This mannequin rivals the bigger Llama 3.1 405B in instruction-following, math, multilingual, and coding duties whereas providing a cost-efficient answer for domain-specific chatbots, clever brokers, and large-scale doc processing.
Whereas Llama 3.3 units a brand new benchmark for open basis fashions, constructing production-ready AI brokers requires greater than only a highly effective mannequin. Databricks Mosaic AI is probably the most complete platform for deploying and managing Llama fashions, with a strong suite of instruments to construct safe, scalable, and dependable AI agent methods that may motive over your enterprise information.
- Entry Llama with a Unified API: Simply entry Llama and different main basis fashions, together with OpenAI and Anthropic, by a single interface. Experiment, examine, and swap fashions effortlessly for max flexibility.
- Safe and Monitor Visitors with AI Gateway: Monitor utilization and request/response utilizing Mosaic AI Gateway whereas implementing security insurance policies like PII detection and dangerous content material filtering for safe, compliant interactions.
- Construct Sooner Actual-Time Brokers: Create high-quality real-time brokers with 40% quicker inference speeds, function-calling capabilities and help for guide or automated agent analysis.
- Course of Batch Workflows at Scale: Simply apply LLMs to giant datasets immediately in your ruled information utilizing a easy SQL interface, with 40% quicker processing speeds and fault tolerance.
- Customise Fashions to Get Excessive High quality: Nice-tune Llama with proprietary information to construct domain-specific, high-quality options.
- Scale with Confidence: Develop deployments with SLA-backed serving, safe configurations, and compliance-ready options designed to auto-scale together with your enterprise’s evolving calls for.
Making GenAI Extra Reasonably priced with New Pricing:
We’re rolling out proprietary effectivity enhancements throughout our inference stack, enabling us to scale back costs and make GenAI much more accessible to everybody. Right here’s a better have a look at the brand new pricing modifications:
Pay-per-Token Serving Worth Cuts:
- Llama 3.1 405B mannequin: 50% discount in enter token worth, 33% discount in output token worth.
- Llama 3.1 70B mannequin: 50% discount for each enter and output tokens.
Provisioned Throughput Worth Cuts:
- Llama 3.1 405B: 44% price discount per token processed.
- Llama 3.3 70B and Llama 3.1 70B: 49% discount in {dollars} per whole tokens processed.
Decreasing Whole Value of Deployment by 80%
With the extra environment friendly and high-quality Llama 3.3 70B mannequin, mixed with the pricing reductions, now you can obtain as much as an 80% discount in your whole TCO.
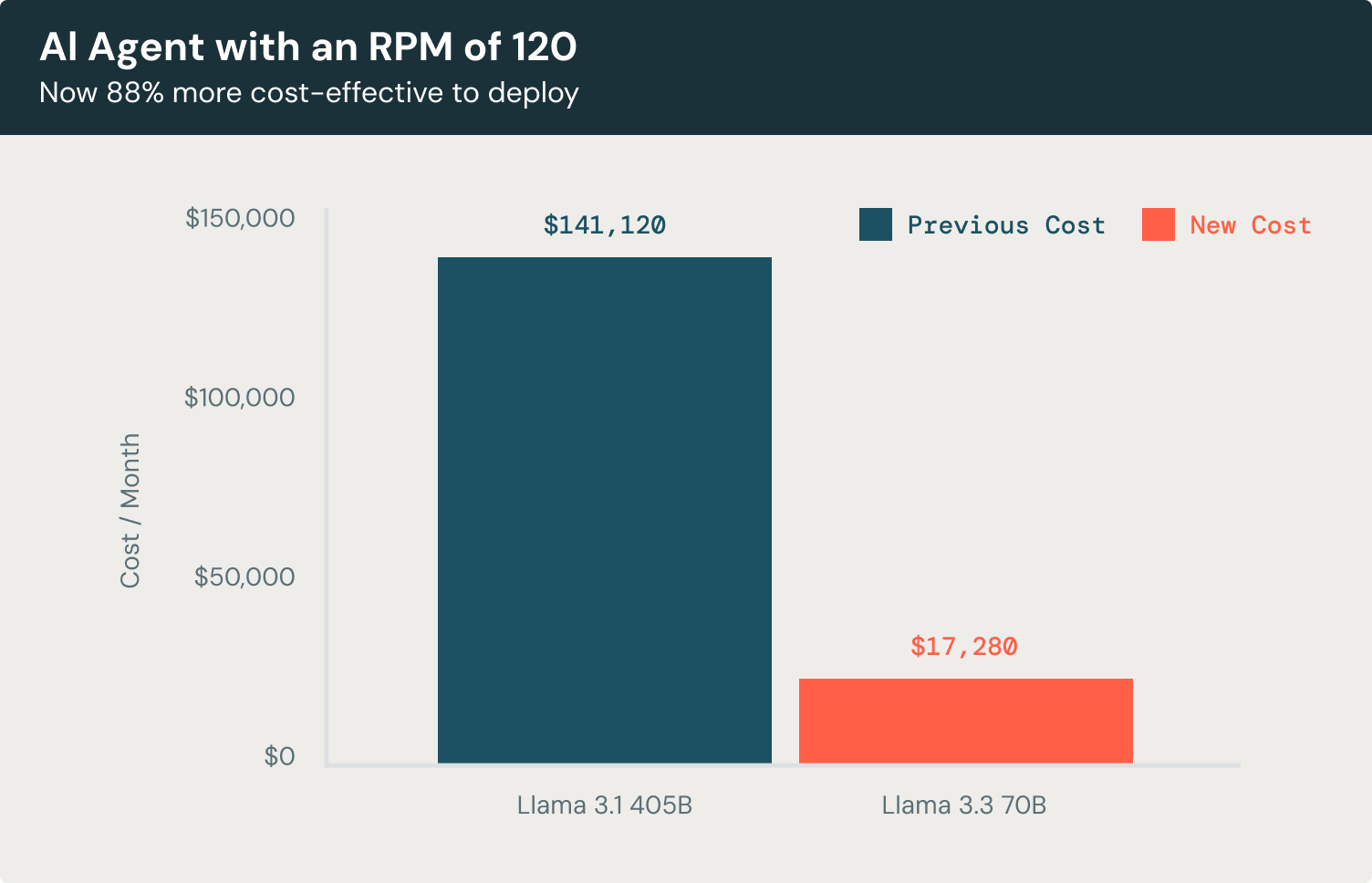
Let’s have a look at a concrete instance. Suppose you’re constructing a customer support chatbot agent designed to deal with 120 requests per minute (RPM). This chatbot processes a mean of three,500 enter tokens and generates 300 output tokens per interplay, creating contextually wealthy responses for customers.
Utilizing Llama 3.3 70B, the month-to-month price of operating this chatbot, focusing solely on LLM utilization, could be 88% decrease price in comparison with Llama 3.1 405B and 72% more cost effective in comparison with main proprietary fashions.
Now let’s check out a batch inference instance. For duties like doc classification or entity extraction throughout a 100K-record dataset, the Llama 3.3 70B mannequin presents outstanding effectivity in comparison with Llama 3.1 405B. Processing rows with 3500 enter tokens and producing 300 output tokens every, the mannequin achieves the identical high-quality outcomes whereas reducing prices by 88%, that’s 58% more cost effective than utilizing main proprietary fashions. This allows you to classify paperwork, extract key entities, and generate actionable insights at scale with out extreme operational bills.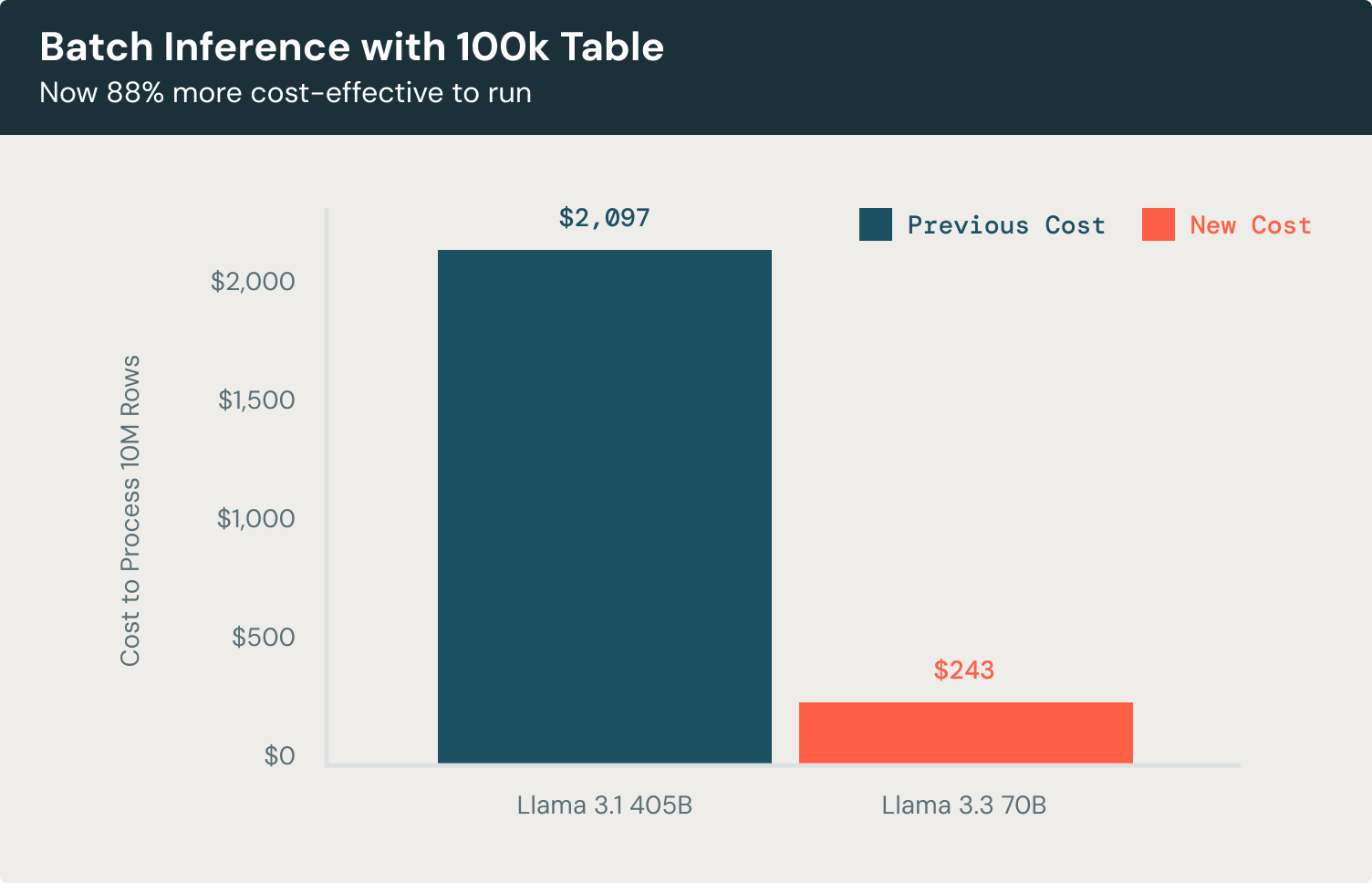
Get Began At the moment
Go to the AI Playground to rapidly strive Llama 3.3 immediately out of your workspace. For extra data, please check with the next assets: