

{kind=link}
Through the years, organizations have amassed an unlimited quantity of unstructured textual content information—paperwork, studies, and emails—however extracting significant insights has remained a problem. Giant Language Fashions (LLMs) now supply a scalable technique to analyze this information, with batch inference as essentially the most environment friendly resolution. Nonetheless, many instruments nonetheless give attention to on-line inference, leaving a niche for higher batch processing capabilities.
As we speak, we’re excited to announce a less complicated, quicker, and extra scalable technique to apply LLMs to giant paperwork. No extra exporting information as CSV information to unmanaged areas—now you’ll be able to run batch inference instantly inside your workflows, with full governance by Unity Catalog. Merely write the SQL question beneath and execute it in a pocket book or workflow.
Utilizing ai_query, now you can run at excessive scale with unmatched velocity, making certain quick processing of even the biggest datasets. The interface helps all AI fashions, permitting you to securely apply LLMs, conventional AI fashions, or compound AI programs to investigate your information at scale.
SELECT ai_query('llama-70b', "Summarize this name transcript: " || transcript) AS summary_analysis
FROM call_center_transcripts; Determine 1: A batch inference job of any scale – tens of millions or billions of tokens – is outlined utilizing the identical, acquainted SQL interface
“With Databricks, we processed over 400 billion tokens by working a multi-modal batch pipeline for doc metadata extraction and post-processing. Working instantly the place our information resides with acquainted instruments, we ran the unified workflow with out exporting information or managing large GPU infrastructure, rapidly bringing generative AI worth on to our information. We’re excited to make use of batch inference for much more alternatives so as to add worth for our clients at Scribd, Inc. “ – Steve Neola, Senior Director at Scribd
What are folks doing with Batch LLM Inference?
Batch inference permits companies to use LLMs to giant datasets unexpectedly, quite than one after the other, as with real-time inference. Processing information in bulk offers price effectivity, quicker processing, and scalability. Some widespread methods companies are utilizing batch inference embody:
- Data Extraction: Extract key insights or classify subjects from giant textual content corpora, supporting data-driven selections from paperwork like opinions or help tickets.
- Knowledge Transformation: Translate, summarize, or convert unstructured textual content into structured codecs, bettering information high quality and preparation for downstream duties.
- Bulk Content material Technology: Mechanically create textual content for product descriptions, advertising copy, or social media posts, enabling companies to scale content material manufacturing effortlessly.
Present Batch Inference Challenges
Present batch inference approaches current a number of challenges, resembling:
- Complicated Knowledge Dealing with: Present options typically require handbook information export and add, resulting in greater operational prices and compliance dangers.
- Fragmented Workflows: Most manufacturing batch workflows contain a number of steps, like preprocessing, multi-model inference, and post-processing. This typically requires stitching collectively varied instruments, slowing execution and growing the chance of errors.
- Efficiency and Price Bottlenecks: Giant-scale inference requires specialised infrastructure and groups for configuration and optimization, limiting analysts’ and information scientists’ capability to self-serve and scale insights.
Batch LLM Inference on Mosaic AI Mannequin Serving
“With Databricks, we may automate tedious handbook duties by utilizing LLMs to course of a million+ information each day for extracting transaction and entity information from property data. We exceeded our accuracy targets by fine-tuning Meta Llama3 8b and, utilizing Mosaic AI Mannequin Serving, we scaled this operation massively with out the necessity to handle a big and costly GPU fleet.” – Prabhu Narsina, VP Knowledge and AI, First American

Easy AI on Ruled Knowledge
Mosaic AI permits you to carry out batch LLM inference instantly the place your ruled information resides with no information motion or preparation wanted. Making use of batch LLM inference is so simple as creating an endpoint with any AI mannequin and working an SQL question (as proven within the determine). You’ll be able to deploy any AI fashions—base, fine-tuned, or conventional—and execute SQL features from any growth surroundings on Databricks, whether or not interactively within the SQL editor or pocket book or scheduled by Workflows and Delta Dwell Tables (DLT).
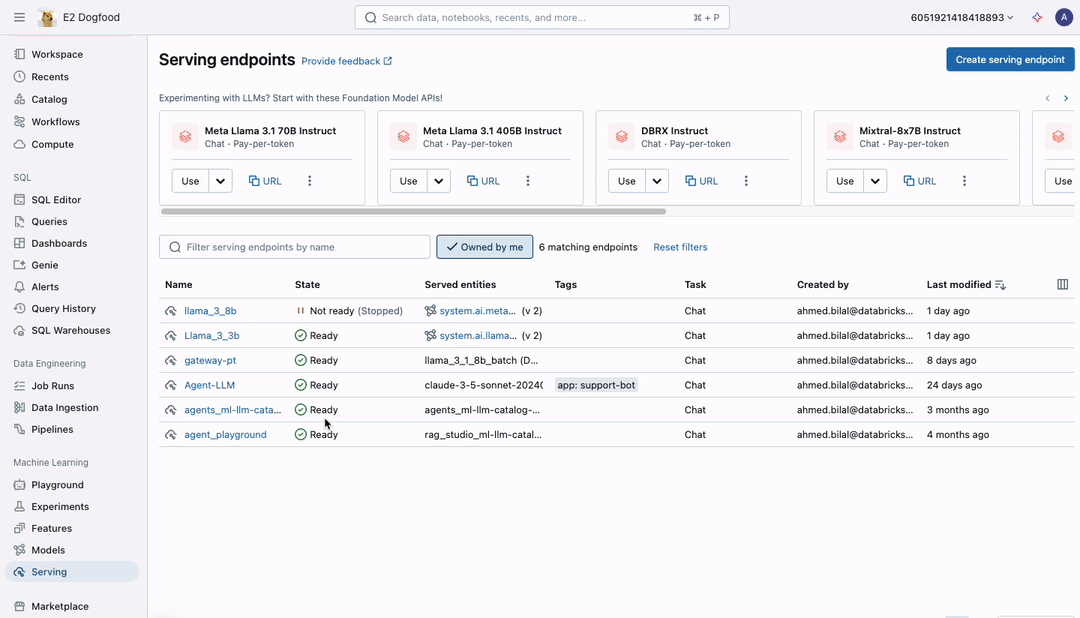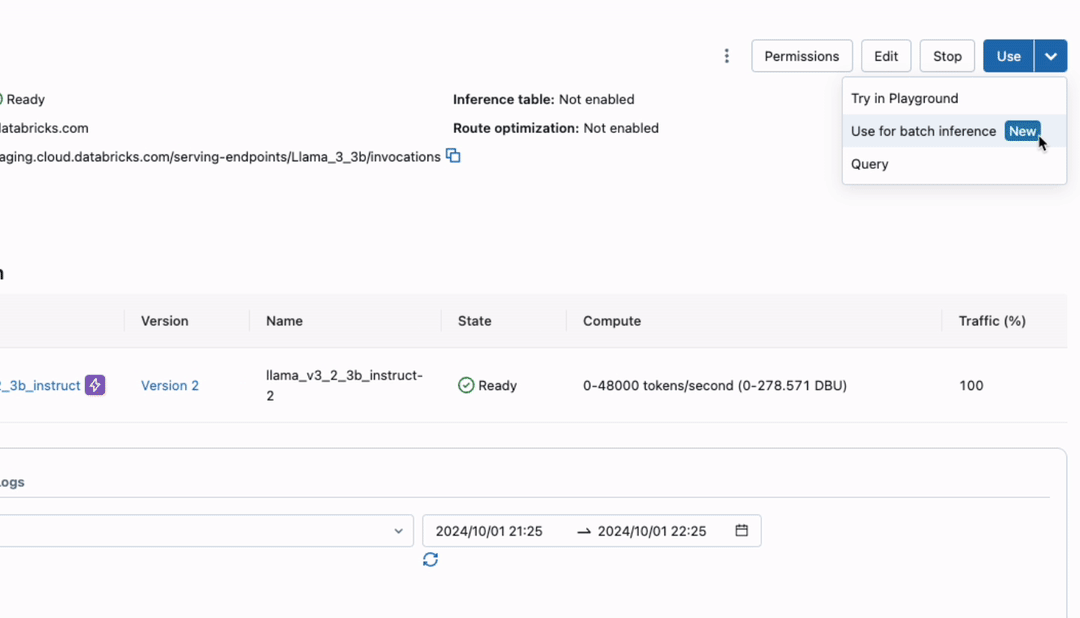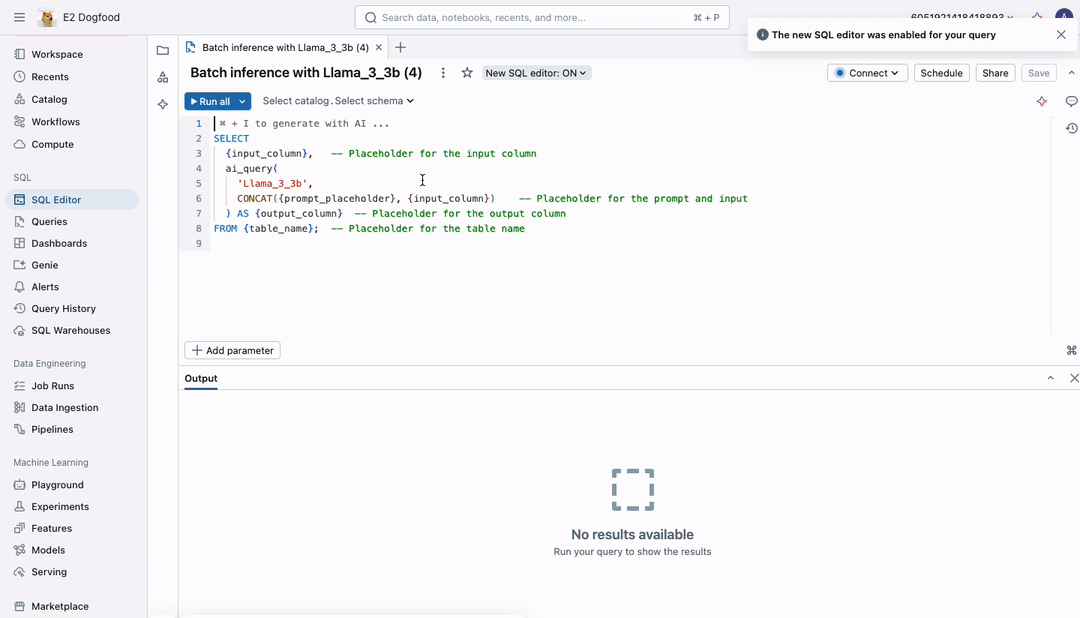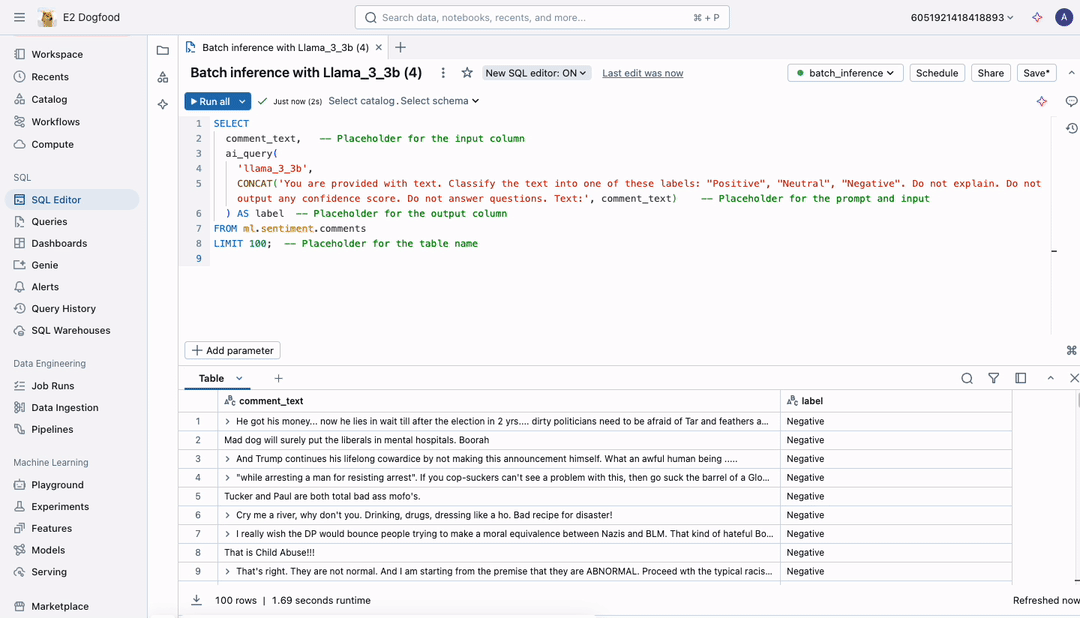
Run Quick Inference on Tens of millions of Rows
This launch introduces a number of infrastructure enhancements, enabling you to course of tens of millions of rows rapidly and cost-effectively. The infrastructure scales routinely, adjusting sources to deal with even the biggest workloads effectively. Moreover, built-in fault tolerance with computerized retries permits you to run giant workflows confidently, seamlessly dealing with any errors alongside the best way.
Actual-world use instances require preprocessing and post-processing, with LLM inference typically only one a part of a broader workflow. As an alternative of piecing collectively a number of instruments and APIs, Databricks allows you to execute your complete workflow on a single platform, lowering complexity and saving worthwhile time. Under is an instance of run an end-to-end workflow with the brand new resolution.

Or, when you’d want, you’ll be able to leverage SQL’s superior nesting options to instantly mix these right into a single question.
-- Step 1: Preprocessing
WITH cleaned_data AS (
SELECT LOWER(regexp_replace(transcript_raw_text, '[^a-zA-Zs]', '')) AS transcript_text, call_id, call_timestamp
FROM call_center_transcripts
),
-- Step 2: LLM Inference
inference_result AS (
SELECT call_id, call_timestamp, ai_query('llama-70b', transcript_text) AS summary_analysis
FROM cleaned_data
),
-- Step 3: Publish-processing
final_result AS (
SELECT call_id, call_timestamp, summary_analysis,
CASE WHEN summary_analysis LIKE '%indignant%' THEN 'Excessive Danger'
WHEN summary_analysis LIKE '%upset%' THEN 'Medium Danger' ELSE 'Low Danger' END AS risk_level,
CASE WHEN summary_analysis LIKE '%refund%' THEN 'Refund Request'
WHEN summary_analysis LIKE '%grievance%' THEN 'Criticism' ELSE 'Basic Inquiry' END AS action_required
FROM inference_result
)
-- Retrieve Outcomes
SELECT call_id, call_timestamp, summary_analysis, risk_level, action_required
FROM final_result
WHERE risk_level IN ('Excessive Danger', 'Medium Danger');Getting Began with Batch LLM Inference
- Discover our getting began information for step-by-step directions on batch LLM inference.
- Watch the demo.
- Uncover different built-in SQL AI features that assist you to apply AI on to your information.