

{kind=link}
There are two main issues with distributed knowledge techniques. The second is out-of-order messages, the primary is duplicate messages, the third is off-by-one errors, and the primary is duplicate messages.
This joke impressed Rockset to confront the information duplication subject via a course of we name deduplication.
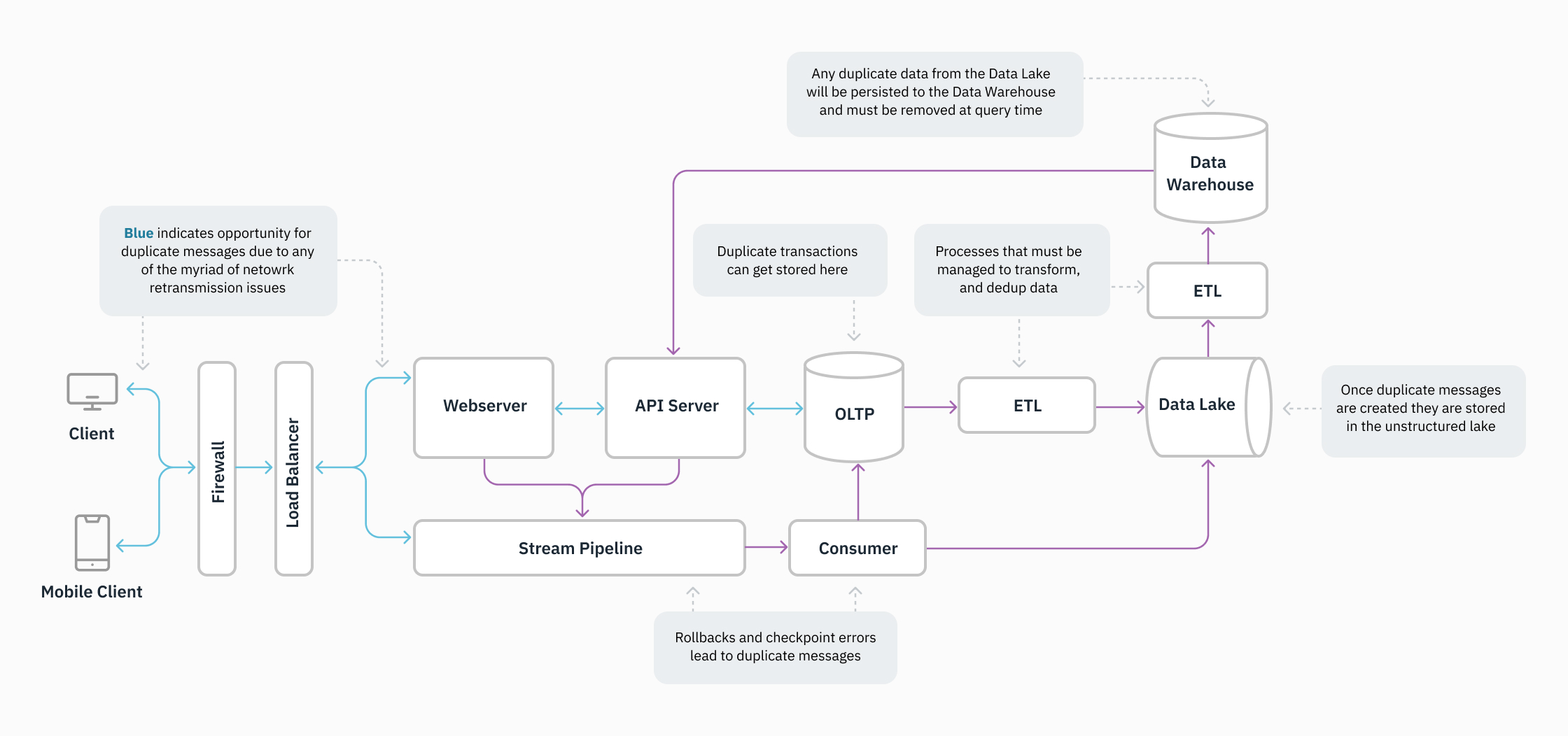
As knowledge techniques grow to be extra complicated and the variety of techniques in a stack will increase, knowledge deduplication turns into more difficult. That is as a result of duplication can happen in a mess of the way. This weblog put up discusses knowledge duplication, the way it plagues groups adopting real-time analytics, and the deduplication options Rockset supplies to resolve the duplication subject. Every time one other distributed knowledge system is added to the stack, organizations grow to be weary of the operational tax on their engineering staff.
Rockset addresses the problem of information duplication in a easy manner, and helps to free groups of the complexities of deduplication, which incorporates untangling the place duplication is happening, organising and managing extract remodel load (ETL) jobs, and trying to unravel duplication at a question time.
The Duplication Downside
In distributed techniques, messages are handed forwards and backwards between many employees, and it’s frequent for messages to be generated two or extra occasions. A system might create a replica message as a result of:
- A affirmation was not despatched.
- The message was replicated earlier than it was despatched.
- The message affirmation comes after a timeout.
- Messages are delivered out of order and have to be resent.
The message could be acquired a number of occasions with the identical info by the point it arrives at a database administration system. Due to this fact, your system should make sure that duplicate data aren’t created. Duplicate data could be expensive and take up reminiscence unnecessarily. These duplicated messages have to be consolidated right into a single message.
Deduplication Options
Earlier than Rockset, there have been three basic deduplication strategies:
- Cease duplication earlier than it occurs.
- Cease duplication throughout ETL jobs.
- Cease duplication at question time.
Deduplication Historical past
Kafka was one of many first techniques to create an answer for duplication. Kafka ensures {that a} message is delivered as soon as and solely as soon as. Nevertheless, if the issue happens upstream from Kafka, their system will see these messages as non-duplicates and ship the duplicate messages with completely different timestamps. Due to this fact, precisely as soon as semantics don’t at all times resolve duplication points and may negatively affect downstream workloads.
Cease Duplication Earlier than it Occurs
Some platforms try and cease duplication earlier than it occurs. This appears perfect, however this methodology requires tough and expensive work to determine the situation and causes of the duplication.
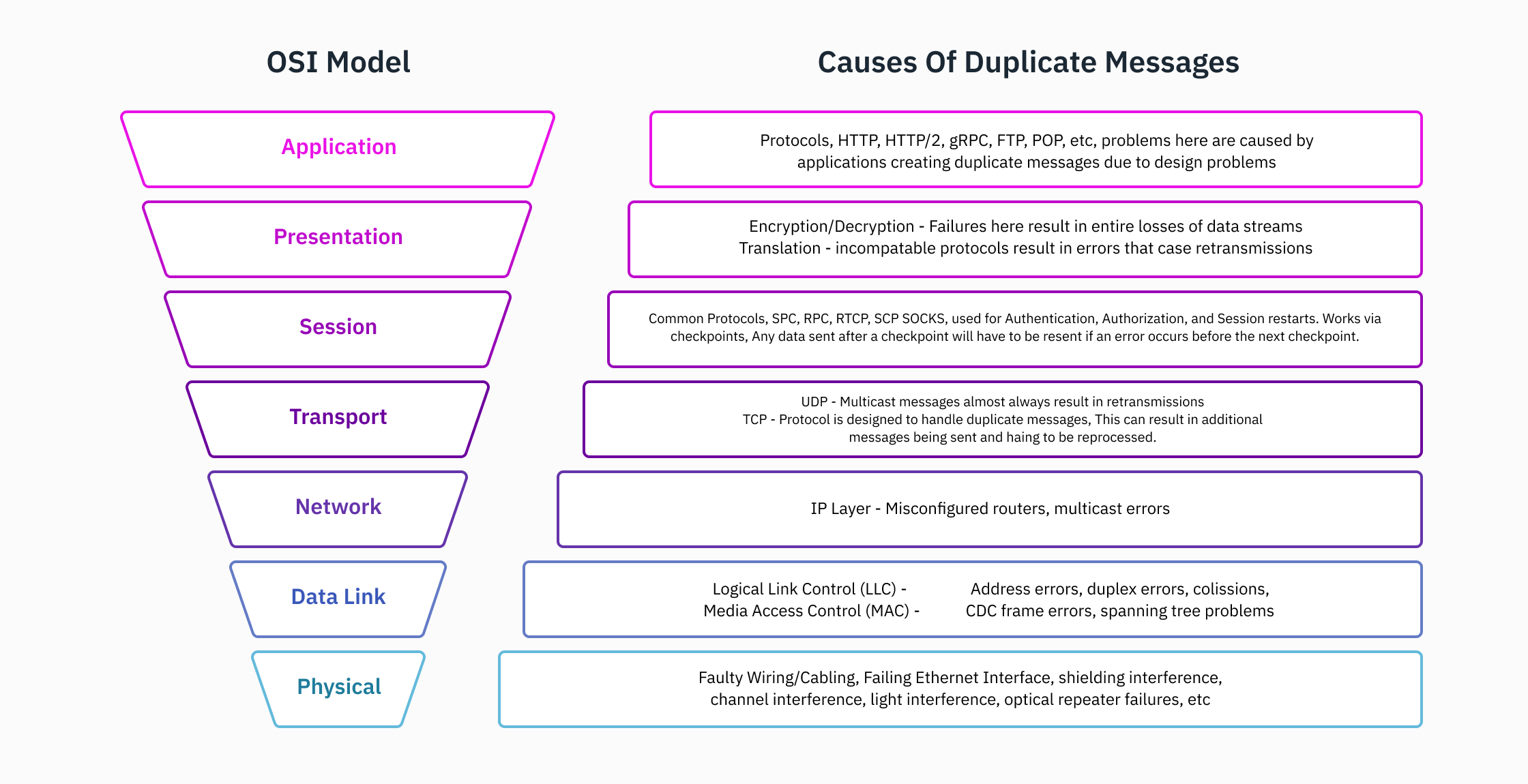
Duplication is usually brought on by any of the next:
- A swap or router.
- A failing client or employee.
- An issue with gRPC connections.
- An excessive amount of site visitors.
- A window dimension that’s too small for packets.
Observe: Take into account this isn’t an exhaustive checklist.
This deduplication strategy requires in-depth information of the system community, in addition to the {hardware} and framework(s). It is rather uncommon, even for a full-stack developer, to know the intricacies of all of the layers of the OSI mannequin and its implementation at an organization. The information storage, entry to knowledge pipelines, knowledge transformation, and utility internals in a corporation of any substantial dimension are all past the scope of a single particular person. In consequence, there are specialised job titles in organizations. The power to troubleshoot and determine all places for duplicated messages requires in-depth information that’s merely unreasonable for a person to have, or perhaps a cross-functional staff. Though the price and experience necessities are very excessive, this strategy gives the best reward.
Cease Duplication Throughout ETL Jobs
Stream-processing ETL jobs is one other deduplication methodology. ETL jobs include extra overhead to handle, require extra computing prices, are potential failure factors with added complexity, and introduce latency to a system probably needing excessive throughput. This entails deduplication throughout knowledge stream consumption. The consumption retailers would possibly embody making a compacted matter and/or introducing an ETL job with a typical batch processing device (e.g., Fivetran, Airflow, and Matillian).
To ensure that deduplication to be efficient utilizing the stream-processing ETL jobs methodology, it’s essential to make sure the ETL jobs run all through your system. Since knowledge duplication can apply wherever in a distributed system, making certain architectures deduplicate all over the place messages are handed is paramount.
Stream processors can have an lively processing window (open for a particular time) the place duplicate messages could be detected and compacted, and out-of-order messages could be reordered. Messages could be duplicated if they’re acquired exterior the processing window. Moreover, these stream processors have to be maintained and may take appreciable compute sources and operational overhead.
Observe: Messages acquired exterior of the lively processing window could be duplicated. We don’t advocate fixing deduplication points utilizing this methodology alone.
Cease Duplication at Question Time
One other deduplication methodology is to try to unravel it at question time. Nevertheless, this will increase the complexity of your question, which is dangerous as a result of question errors could possibly be generated.
For instance, in case your answer tracks messages utilizing timestamps, and the duplicate messages are delayed by one second (as an alternative of fifty milliseconds), the timestamp on the duplicate messages won’t match your question syntax inflicting an error to be thrown.
How Rockset Solves Duplication
Rockset solves the duplication downside via distinctive SQL-based transformations at ingest time.
Rockset is a Mutable Database
Rockset is a mutable database and permits for duplicate messages to be merged at ingest time. This technique frees groups from the various cumbersome deduplication choices lined earlier.
Every doc has a novel identifier referred to as _id that acts like a major key. Customers can specify this identifier at ingest time (e.g. throughout updates) utilizing SQL-based transformations. When a brand new doc arrives with the identical _id, the duplicate message merges into the present report. This gives customers a easy answer to the duplication downside.
If you convey knowledge into Rockset, you’ll be able to construct your personal complicated _id key utilizing SQL transformations that:
- Establish a single key.
- Establish a composite key.
- Extract knowledge from a number of keys.
Rockset is totally mutable with out an lively window. So long as you specify messages with _id or determine _id throughout the doc you might be updating or inserting, incoming duplicate messages can be deduplicated and merged collectively right into a single doc.
Rockset Permits Knowledge Mobility
Different analytics databases retailer knowledge in fastened knowledge constructions, which require compaction, resharding and rebalancing. Any time there’s a change to current knowledge, a serious overhaul of the storage construction is required. Many knowledge techniques have lively home windows to keep away from overhauls to the storage construction. In consequence, if you happen to map _id to a report exterior the lively database, that report will fail. In distinction, Rockset customers have plenty of knowledge mobility and may replace any report in Rockset at any time.
A Buyer Win With Rockset
Whereas we have spoken concerning the operational challenges with knowledge deduplication in different techniques, there’s additionally a compute-spend factor. Trying deduplication at question time, or utilizing ETL jobs could be computationally costly for a lot of use instances.
Rockset can deal with knowledge modifications, and it helps inserts, updates and deletes that profit finish customers. Right here’s an nameless story of one of many customers that I’ve labored intently with on their real-time analytics use case.
Buyer Background
A buyer had an enormous quantity of information modifications that created duplicate entries inside their knowledge warehouse. Each database change resulted in a brand new report, though the client solely wished the present state of the information.
If the client wished to place this knowledge into a knowledge warehouse that can’t map _id, the client would’ve needed to cycle via the a number of occasions saved of their database. This contains working a base question adopted by extra occasion queries to get to the newest worth state. This course of is extraordinarily computationally costly and time consuming.
Rockset’s Answer
Rockset supplied a extra environment friendly deduplication answer to their downside. Rockset maps _id so solely the newest states of all data are saved, and all incoming occasions are deduplicated. Due to this fact the client solely wanted to question the newest state. Due to this performance, Rockset enabled this buyer to scale back each the compute required, in addition to the question processing time — effectively delivering sub-second queries.
Rockset is the real-time analytics database within the cloud for contemporary knowledge groups. Get quicker analytics on more energizing knowledge, at decrease prices, by exploiting indexing over brute-force scanning.