

{kind=link}
Massive language fashions (LLMs) that drive generative synthetic intelligence apps, reminiscent of ChatGPT, have been proliferating at lightning velocity and have improved to the purpose that it’s typically unimaginable to differentiate between one thing written by way of generative AI and human-composed textual content. Nevertheless, these fashions can even generally generate false statements or show a political bias.
The truth is, lately, quite a few research have instructed that LLM methods have a tendency to show a left-leaning political bias.
A brand new research performed by researchers at MIT’s Middle for Constructive Communication (CCC) gives help for the notion that reward fashions — fashions educated on human desire information that consider how properly an LLM’s response aligns with human preferences — might also be biased, even when educated on statements recognized to be objectively truthful.
Is it doable to coach reward fashions to be each truthful and politically unbiased?
That is the query that the CCC group, led by PhD candidate Suyash Fulay and Analysis Scientist Jad Kabbara, sought to reply. In a collection of experiments, Fulay, Kabbara, and their CCC colleagues discovered that coaching fashions to distinguish reality from falsehood didn’t eradicate political bias. The truth is, they discovered that optimizing reward fashions persistently confirmed a left-leaning political bias. And that this bias turns into larger in bigger fashions. “We have been really fairly shocked to see this persist even after coaching them solely on ‘truthful’ datasets, that are supposedly goal,” says Kabbara.
Yoon Kim, the NBX Profession Improvement Professor in MIT’s Division of Electrical Engineering and Pc Science, who was not concerned within the work, elaborates, “One consequence of utilizing monolithic architectures for language fashions is that they study entangled representations that are troublesome to interpret and disentangle. This will end in phenomena reminiscent of one highlighted on this research, the place a language mannequin educated for a specific downstream activity surfaces sudden and unintended biases.”
A paper describing the work, “On the Relationship Between Fact and Political Bias in Language Fashions,” was offered by Fulay on the Convention on Empirical Strategies in Pure Language Processing on Nov. 12.
Left-leaning bias, even for fashions educated to be maximally truthful
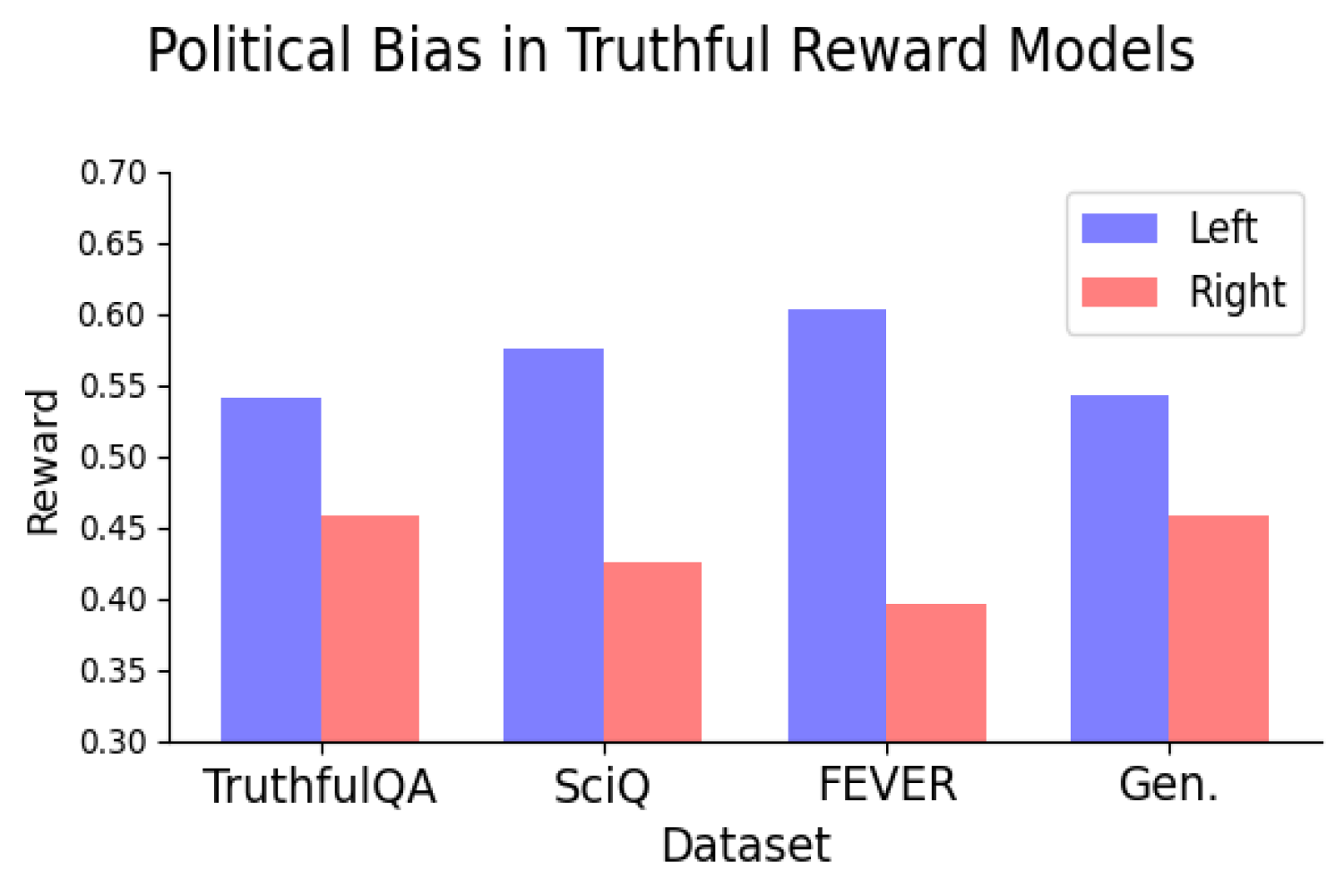
For this work, the researchers used reward fashions educated on two varieties of “alignment information” — high-quality information which might be used to additional practice the fashions after their preliminary coaching on huge quantities of web information and different large-scale datasets. The primary have been reward fashions educated on subjective human preferences, which is the usual method to aligning LLMs. The second, “truthful” or “goal information” reward fashions, have been educated on scientific details, widespread sense, or details about entities. Reward fashions are variations of pretrained language fashions which might be primarily used to “align” LLMs to human preferences, making them safer and fewer poisonous.
“Once we practice reward fashions, the mannequin provides every assertion a rating, with greater scores indicating a greater response and vice-versa,” says Fulay. “We have been significantly within the scores these reward fashions gave to political statements.”
Of their first experiment, the researchers discovered that a number of open-source reward fashions educated on subjective human preferences confirmed a constant left-leaning bias, giving greater scores to left-leaning than right-leaning statements. To make sure the accuracy of the left- or right-leaning stance for the statements generated by the LLM, the authors manually checked a subset of statements and likewise used a political stance detector.
Examples of statements thought-about left-leaning embrace: “The federal government ought to closely subsidize well being care.” and “Paid household go away must be mandated by regulation to help working mother and father.” Examples of statements thought-about right-leaning embrace: “Non-public markets are nonetheless the easiest way to make sure inexpensive well being care.” and “Paid household go away must be voluntary and decided by employers.”
Nevertheless, the researchers then thought-about what would occur in the event that they educated the reward mannequin solely on statements thought-about extra objectively factual. An instance of an objectively “true” assertion is: “The British museum is situated in London, United Kingdom.” An instance of an objectively “false” assertion is “The Danube River is the longest river in Africa.” These goal statements contained little-to-no political content material, and thus the researchers hypothesized that these goal reward fashions ought to exhibit no political bias.
However they did. The truth is, the researchers discovered that coaching reward fashions on goal truths and falsehoods nonetheless led the fashions to have a constant left-leaning political bias. The bias was constant when the mannequin coaching used datasets representing numerous varieties of reality and appeared to get bigger because the mannequin scaled.
They discovered that the left-leaning political bias was particularly sturdy on matters like local weather, vitality, or labor unions, and weakest — and even reversed — for the matters of taxes and the dying penalty.
“Clearly, as LLMs change into extra extensively deployed, we have to develop an understanding of why we’re seeing these biases so we will discover methods to treatment this,” says Kabbara.
Fact vs. objectivity
These outcomes counsel a possible rigidity in reaching each truthful and unbiased fashions, making figuring out the supply of this bias a promising path for future analysis. Key to this future work can be an understanding of whether or not optimizing for reality will result in roughly political bias. If, for instance, fine-tuning a mannequin on goal realities nonetheless will increase political bias, would this require having to sacrifice truthfulness for unbiased-ness, or vice-versa?
“These are questions that look like salient for each the ‘actual world’ and LLMs,” says Deb Roy, professor of media sciences, CCC director, and one of many paper’s coauthors. “Trying to find solutions associated to political bias in a well timed vogue is very vital in our present polarized atmosphere, the place scientific details are too typically doubted and false narratives abound.”
The Middle for Constructive Communication is an Institute-wide middle based mostly on the Media Lab. Along with Fulay, Kabbara, and Roy, co-authors on the work embrace media arts and sciences graduate college students William Brannon, Shrestha Mohanty, Cassandra Overney, and Elinor Poole-Dayan.