

{kind=link}
new_my_likes
Mix the brand new and previous information:
deduped_my_likes
And, lastly, save the up to date information by overwriting the previous file:
rio::export(deduped_my_likes, 'my_likes.parquet')
Step 4. View and search your information the standard means
I prefer to create a model of this information particularly to make use of in a searchable desk. It features a hyperlink on the finish of every submit’s textual content to the unique submit on Bluesky, letting me simply view any photos, replies, mother and father, or threads that aren’t in a submit’s plain textual content. I additionally take away some columns I don’t want within the desk.
my_likes_for_table
mutate(
Submit = str_glue("{Submit} >>"),
ExternalURL = ifelse(!is.na(ExternalURL), str_glue("{substr(ExternalURL, 1, 25)}..."), "")
) |>
choose(Submit, Title, CreatedAt, ExternalURL)
Right here’s one method to create a searchable HTML desk of that information, utilizing the DT bundle:
DT::datatable(my_likes_for_table, rownames = FALSE, filter="high", escape = FALSE, choices = checklist(pageLength = 25, autoWidth = TRUE, filter = "high", lengthMenu = c(25, 50, 75, 100), searchHighlight = TRUE,
search = checklist(regex = TRUE)
)
)
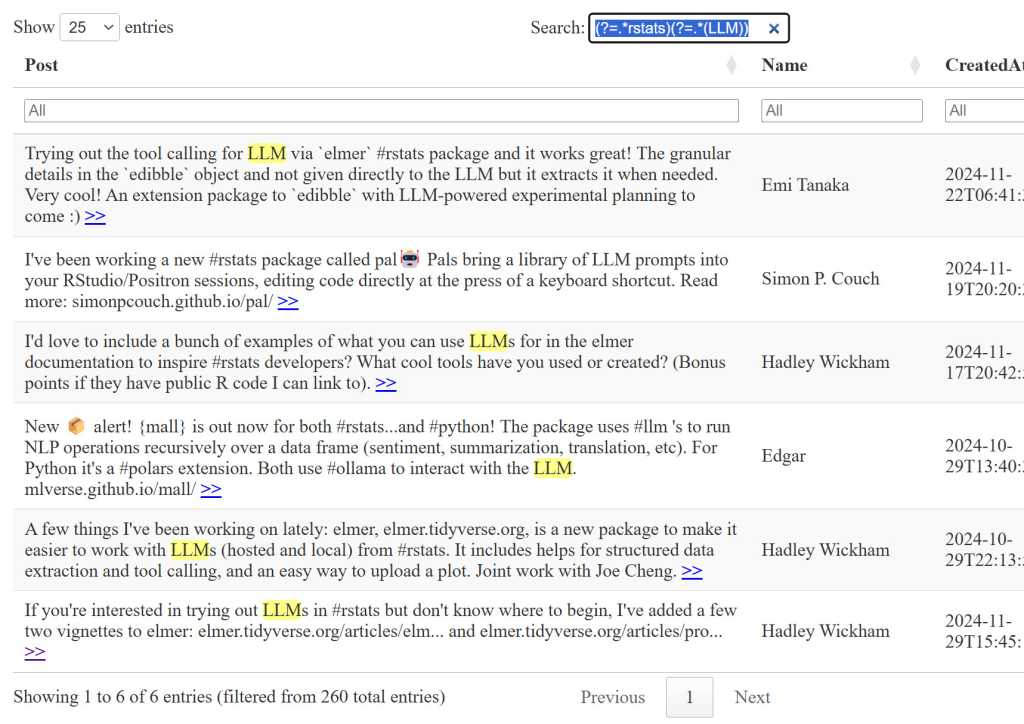
This desk has a table-wide search field on the high proper and search filters for every column, so I can seek for two phrases in my desk, such because the #rstats hashtag in the principle search bar after which any submit the place the textual content accommodates LLM (the desk’s search isn’t case delicate) within the Submit column filter bar. Or, as a result of I enabled common expression looking out with the search = checklist(regex = TRUE) choice, I may use a single regexp lookahead sample (?=.rstats)(?=.(LLM)) within the search field.
IDG
Generative AI chatbots like ChatGPT and Claude will be fairly good at writing advanced common expressions. And with matching textual content highlights turned on within the desk, will probably be straightforward so that you can see whether or not the regexp is doing what you need.
Question your Bluesky likes with an LLM
The best free means to make use of generative AI to question these posts is by importing the info file to a service of your selection. I’ve had good outcomes with Google’s NotebookLM, which is free and exhibits you the supply textual content for its solutions. NotebookLM has a beneficiant file restrict of 500,000 phrases or 200MB per supply, and Google says it gained’t prepare its giant language fashions (LLMs) in your information.
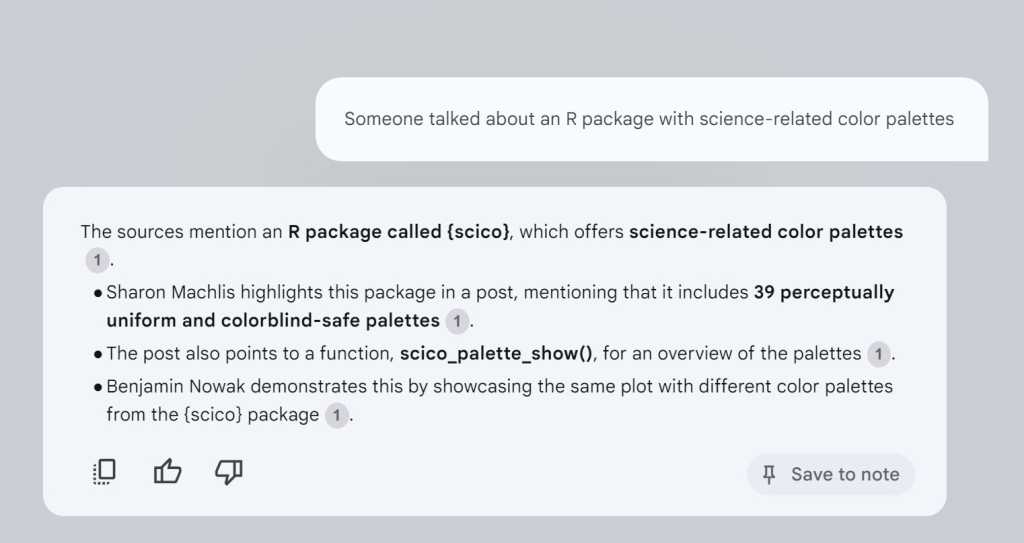
The question “Somebody talked about an R bundle with science-related colour palettes” pulled up the precise submit I used to be considering of — one which I had preferred after which re-posted with my very own feedback. And I didn’t have to offer NotebookLLM my very own prompts or directions to inform it that I needed to 1) use solely that doc for solutions, and a couple of) see the supply textual content it used to generate its response. All I needed to do was ask my query.
IDG
I formatted the info to be a bit extra helpful and fewer wasteful by limiting CreatedAt to dates with out occasions, retaining the submit URL as a separate column (as a substitute of a clickable hyperlink with added HTML), and deleting the exterior URLs column. I saved that slimmer model as a .txt and never .csv file, since NotebookLM doesn’t deal with .csv extentions.
my_likes_for_ai
mutate(CreatedAt = substr(CreatedAt, 1, 10)) |>
choose(Submit, Title, CreatedAt, URL)
rio::export(my_likes_for_ai, "my_likes_for_ai.txt")
After importing your likes file to NotebookLM, you may ask questions instantly as soon as the file is processed.

IDG
In the event you actually needed to question the doc inside R as a substitute of utilizing an exterior service, one choice is the Elmer Assistant, a challenge on GitHub. It needs to be pretty simple to switch its immediate and supply information in your wants. Nevertheless, I haven’t had nice luck working this domestically, regardless that I’ve a reasonably sturdy Home windows PC.
Replace your likes by scheduling the script to run mechanically
To be able to be helpful, you’ll have to hold the underlying “posts I’ve preferred” information updated. I run my script manually on my native machine periodically after I’m energetic on Bluesky, however you may also schedule the script to run mechanically daily or as soon as per week. Listed below are three choices:
- Run a script domestically. In the event you’re not too nervous about your script all the time working on a precise schedule, instruments akin to taskscheduleR for Home windows or cronR for Mac or Linux can assist you run your R scripts mechanically.
- Use GitHub Actions. Johannes Gruber, the writer of the atrrr bundle, describes how he makes use of free GitHub Actions to run his R Bloggers Bluesky bot. His directions will be modified for different R scripts.
- Run a script on a cloud server. Or you may use an occasion on a public cloud akin to Digital Ocean plus a cron job.
It’s your decision a model of your Bluesky likes information that doesn’t embody each submit you’ve preferred. Typically you might click on like simply to acknowledge you noticed a submit, or to encourage the writer that persons are studying, or since you discovered the submit amusing however in any other case don’t anticipate you’ll need to discover it once more.
Nevertheless, a warning: It could get onerous to manually mark bookmarks in a spreadsheet in the event you like numerous posts, and it’s worthwhile to be dedicated to maintain it updated. There’s nothing fallacious with looking out by your whole database of likes as a substitute of curating a subset with “bookmarks.”
That mentioned, right here’s a model of the method I’ve been utilizing. For the preliminary setup, I recommend utilizing an Excel or .csv file.
Step 1. Import your likes right into a spreadsheet and add columns
I’ll begin by importing the my_likes.parquet file and including empty Bookmark and Notes columns, after which saving that to a brand new file.
my_likes
mutate(Notes = as.character(""), .earlier than = 1) |>
mutate(Bookmark = as.character(""), .after = Bookmark)
rio::export(likes_w_bookmarks, "likes_w_bookmarks.xlsx")
After some experimenting, I opted to have a Bookmark column as characters, the place I can add simply “T” or “F” in a spreadsheet, and never a logical TRUE or FALSE column. With characters, I don’t have to fret whether or not R’s Boolean fields will translate correctly if I determine to make use of this information outdoors of R. The Notes column lets me add textual content to elucidate why I’d need to discover one thing once more.
Subsequent is the handbook a part of the method: marking which likes you need to hold as bookmarks. Opening this in a spreadsheet is handy as a result of you may click on and drag F or T down a number of cells at a time. In case you have numerous likes already, this can be tedious! You would determine to mark all of them “F” for now and begin bookmarking manually going ahead, which can be much less onerous.
Save the file manually again to likes_w_bookmarks.xlsx.
Step 2. Maintain your spreadsheet in sync along with your likes
After that preliminary setup, you’ll need to hold the spreadsheet in sync with the info because it will get up to date. Right here’s one method to implement that.
After updating the brand new deduped_my_likes likes file, create a bookmark examine lookup, after which be part of that along with your deduped likes file.
bookmark_check
choose(URL, Bookmark, Notes)
my_likes_w_bookmarks
relocate(Bookmark, Notes)
Now you might have a file with the brand new likes information joined along with your current bookmarks information, with entries on the high having no Bookmark or Notes entries but. Save that to your spreadsheet file.
rio::export(my_likes_w_bookmarks, "likes_w_bookmarks.xlsx")
A substitute for this considerably handbook and intensive course of could possibly be utilizing dplyr::filter() in your deduped likes information body to take away gadgets you gained’t need once more, akin to posts mentioning a favourite sports activities workforce or posts on sure dates when you centered on a subject you don’t have to revisit.
Subsequent steps
Wish to search your individual posts as properly? You may pull them through the Bluesky API in an identical workflow utilizing atrrr’s get_skeets_authored_by() perform. When you begin down this street, you’ll see there’s much more you are able to do. And also you’ll probably have firm amongst R customers.