

{kind=link}
Have you ever ever discovered your self observing a product’s components checklist, googling unfamiliar chemical names to determine what they imply? It’s a typical battle – deciphering advanced product info on the spot will be overwhelming and time-consuming. Conventional strategies, like looking for every ingredient individually, typically result in fragmented and complicated outcomes. However what if there was a better, sooner solution to analyze product components and get clear, actionable insights immediately? On this article, we’ll stroll you thru constructing a Product Components Analyzer utilizing Gemini 2.0, Phidata, and Tavily Internet Search. Let’s dive in and make sense of these ingredient lists as soon as and for all!
Studying Targets
- Design a Multimodal AI Agent structure utilizing Phidata and Gemini 2.0 for vision-language duties.
- Combine Tavily Internet Search into agent workflows for higher context and data retrieval.
- Construct a Product Ingredient Analyzer Agent that mixes picture processing and net seek for detailed product insights.
- Find out how system prompts and directions information agent conduct in multimodal duties.
- Develop a Streamlit UI for real-time picture evaluation, diet particulars, and health-based options.
This text was revealed as part of the Knowledge Science Blogathon.
What are Multimodal Techniques?
Multimodal techniques course of and perceive a number of varieties of enter information—like textual content, photos, audio, and video—concurrently. Imaginative and prescient-language fashions, comparable to Gemini 2.0 Flash, GPT-4o, Claude Sonnet 3.5, and Pixtral-12B, excel at understanding relationships between these modalities, extracting significant insights from advanced inputs.
On this context, we give attention to vision-language fashions that analyze photos and generate textual insights. These techniques mix laptop imaginative and prescient and pure language processing to interpret visible info based mostly on consumer prompts.
Multimodal Actual-world Use Instances
Multimodal techniques are reworking industries:
- Finance: Customers can take screenshots of unfamiliar phrases in on-line kinds and get instantaneous explanations.
- E-commerce: Customers can {photograph} product labels to obtain detailed ingredient evaluation and well being insights.
- Schooling: College students can seize textbook diagrams and obtain simplified explanations.
- Healthcare: Sufferers can scan medical experiences or prescription labels for simplified explanations of phrases and dosage directions.
Why Multimodal Agent?
The shift from single-mode AI to multimodal brokers marks a significant leap in how we work together with AI techniques. Right here’s what makes multimodal brokers so efficient:
- They course of each visible and textual info concurrently, delivering extra correct and context-aware responses.
- They simplify advanced info, making it accessible to customers who might battle with technical phrases or detailed content material.
- As a substitute of manually looking for particular person parts, customers can add a picture and obtain complete evaluation in a single step.
- By combining instruments like net search and picture evaluation, they supply extra full and dependable insights.
Constructing Product Ingredient Analyzer Agent
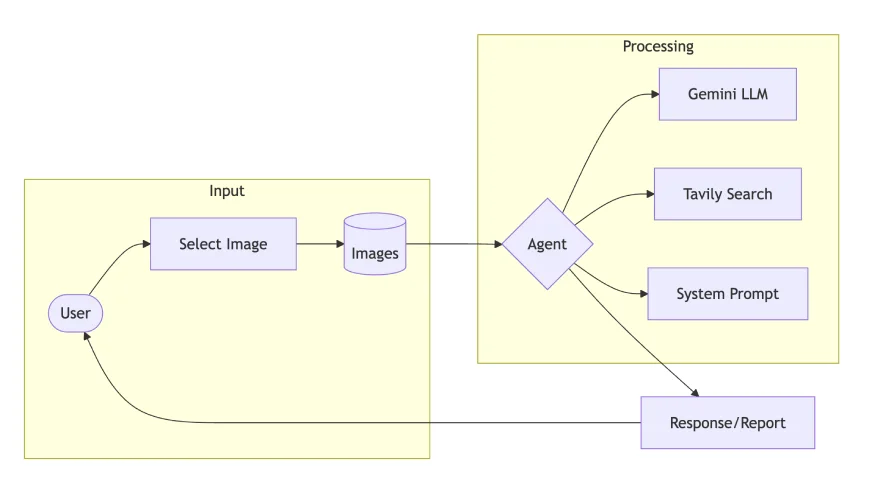
Let’s break down the implementation of a Product Ingredient Evaluation Agent:
Step 1: Setup Dependencies
- Gemini 2.0 Flash: Handles multimodal processing with enhanced imaginative and prescient capabilities
- Tavily Search: Supplies net search integration for extra context
- Phidata: Orchestrates the Agent system and manages workflows
- Streamlit: To develop the prototype into Internet-based purposes.
!pip set up phidata google-generativeai tavily-python streamlit pillowStep 2: API Setup and Configuration
On this step, we’ll arrange the surroundings variables and collect the required API credentials to run this use case.
from phi.agent import Agent
from phi.mannequin.google import Gemini # wants a api key
from phi.instruments.tavily import TavilyTools # additionally wants a api key
import os
TAVILY_API_KEY = "<replace-your-api-key>"
GOOGLE_API_KEY = "<replace-your-api-key>"
os.environ['TAVILY_API_KEY'] = TAVILY_API_KEY
os.environ['GOOGLE_API_KEY'] = GOOGLE_API_KEYStep 3: System immediate and Directions
To get higher responses from language fashions, it’s good to write higher prompts. This includes clearly defining the function and offering detailed directions within the system immediate for the LLM.
Let’s outline the function and duties of an Agent with experience in ingredient evaluation and diet. The directions ought to information the Agent to systematically analyze meals merchandise, assess components, contemplate dietary restrictions, and consider well being implications.
SYSTEM_PROMPT = """
You might be an skilled Meals Product Analyst specialised in ingredient evaluation and diet science.
Your function is to research product components, present well being insights, and establish potential considerations by combining ingredient evaluation with scientific analysis.
You make the most of your dietary information and analysis works to supply evidence-based insights, making advanced ingredient info accessible and actionable for customers.
Return your response in Markdown format.
"""
INSTRUCTIONS = """
* Learn ingredient checklist from product picture
* Keep in mind the consumer might not be educated concerning the product, break it down in easy phrases like explaining to 10 yr child
* Determine synthetic components and preservatives
* Examine in opposition to main dietary restrictions (vegan, halal, kosher). Embody this in response.
* Charge dietary worth on scale of 1-5
* Spotlight key well being implications or considerations
* Recommend more healthy options if wanted
* Present transient evidence-based suggestions
* Use Search software for getting context
"""Step 4: Outline the Agent Object
The Agent, constructed utilizing Phidata, is configured to course of markdown formatting and function based mostly on the system immediate and directions outlined earlier. The reasoning mannequin used on this instance is Gemini 2.0 Flash, recognized for its superior capacity to know photos and movies in comparison with different fashions.
For software integration, we’ll use Tavily Search, a complicated net search engine that gives related context straight in response to consumer queries, avoiding pointless descriptions, URLs, and irrelevant parameters.
agent = Agent(
mannequin = Gemini(id="gemini-2.0-flash-exp"),
instruments = [TavilyTools()],
markdown=True,
system_prompt = SYSTEM_PROMPT,
directions = INSTRUCTIONS
)Step 5: Multimodal – Understanding the Picture
With the Agent parts now in place, the subsequent step is to supply consumer enter. This may be achieved in two methods: both by passing the picture path or the URL, together with a consumer immediate specifying what info must be extracted from the offered picture.
Method: 1 Utilizing Picture Path

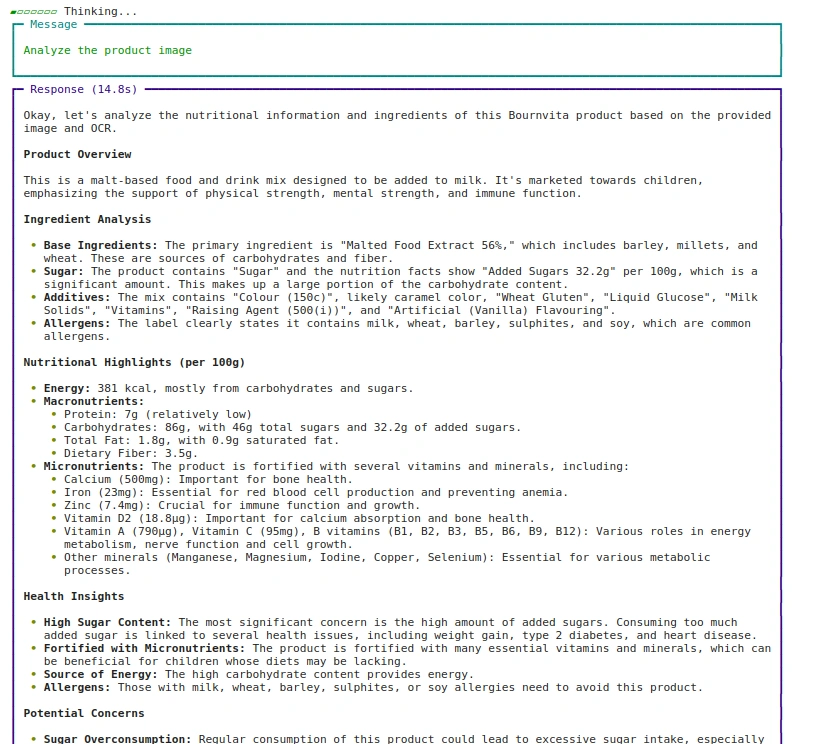
agent.print_response(
"Analyze the product picture",
photos = ["images/bournvita.jpg"],
stream=True
)Output:
Method: 2 Utilizing URL
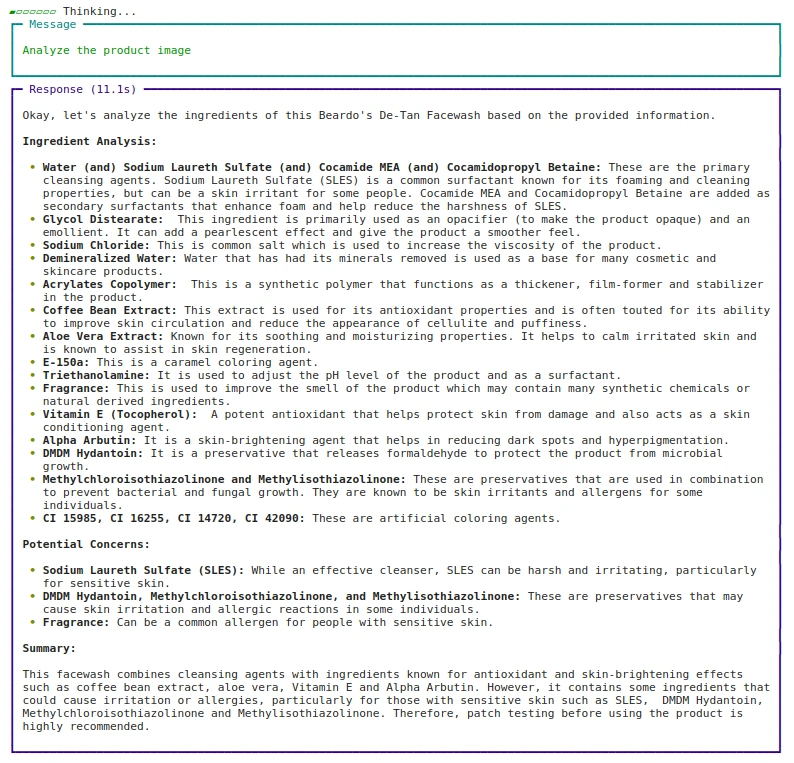
agent.print_response(
"Analyze the product picture",
photos = ["https://beardo.in/cdn/shop/products/9_2ba7ece4-0372-4a34-8040-5dc40c89f103.jpg?v=1703589764&width=1946"],
stream=True
)Output:
Step 6: Develop the Internet App utilizing Streamlit
Now that we all know easy methods to execute the Multimodal Agent, let’s construct the UI half utilizing Streamlit.
import streamlit as st
from PIL import Picture
from io import BytesIO
from tempfile import NamedTemporaryFile
st.title("🔍 Product Ingredient Analyzer")To optimize efficiency, outline the Agent inference underneath a cached perform. The cache decorator helps enhance effectivity by reusing the Agent occasion.
Since we’re utilizing Streamlit, which refreshes all the web page after every occasion loop or widget set off, including st.cache_resource ensures the perform just isn’t refreshed and saves it within the cache.
@st.cache_resource
def get_agent():
return Agent(
mannequin=Gemini(id="gemini-2.0-flash-exp"),
system_prompt=SYSTEM_PROMPT,
directions=INSTRUCTIONS,
instruments=[TavilyTools(api_key=os.getenv("TAVILY_API_KEY"))],
markdown=True,
)When a brand new picture path is offered by the consumer, the analyze_image perform runs and executes the Agent object outlined in get_agent. For real-time seize and the choice to add photos, the uploaded file must be saved quickly for processing.
The picture is saved in a short lived file, and as soon as the execution is accomplished, the non permanent file is deleted to unencumber sources. This may be achieved utilizing the NamedTemporaryFile perform from the tempfile library.
def analyze_image(image_path):
agent = get_agent()
with st.spinner('Analyzing picture...'):
response = agent.run(
"Analyze the given picture",
photos=[image_path],
)
st.markdown(response.content material)
def save_uploaded_file(uploaded_file):
with NamedTemporaryFile(dir=".", suffix='.jpg', delete=False) as f:
f.write(uploaded_file.getbuffer())
return f.identifyFor a greater consumer interface, when a consumer selects a picture, it’s more likely to have various resolutions and sizes. To keep up a constant format and correctly show the picture, we will resize the uploaded or captured picture to make sure it matches clearly on the display.
The LANCZOS resampling algorithm offers high-quality resizing, notably helpful for product photos the place textual content readability is essential for ingredient evaluation.
MAX_IMAGE_WIDTH = 300
def resize_image_for_display(image_file):
img = Picture.open(image_file)
aspect_ratio = img.peak / img.width
new_height = int(MAX_IMAGE_WIDTH * aspect_ratio)
img = img.resize((MAX_IMAGE_WIDTH, new_height), Picture.Resampling.LANCZOS)
buf = BytesIO()
img.save(buf, format="PNG")
return buf.getvalue()Step 7: UI Options for Streamlit
The interface is split into three navigation tabs the place the consumer can decide his selection of pursuits:
- Tab-1: Instance Merchandise that customers can choose to check the app
- Tab-2: Add an Picture of your selection if it’s already saved.
- Tab-3: Seize or Take a reside picture and analyze the product.
We repeat the identical logical stream for all the three tabs:
- First, select the picture of your selection and resize it to show on the Streamlit UI utilizing st.picture.
- Second, save that picture in a short lived listing to course of it to the Agent object.
- Third, analyze the picture the place the Agent execution will happen utilizing Gemini 2.0 LLM and Tavily Search software.
State administration is dealt with via Streamlit’s session state, monitoring chosen examples and evaluation standing.

def foremost():
if 'selected_example' not in st.session_state:
st.session_state.selected_example = None
if 'analyze_clicked' not in st.session_state:
st.session_state.analyze_clicked = False
tab_examples, tab_upload, tab_camera = st.tabs([
"📚 Example Products",
"📤 Upload Image",
"📸 Take Photo"
])
with tab_examples:
example_images = {
"🥤 Power Drink": "photos/bournvita.jpg",
"🥔 Potato Chips": "photos/lays.jpg",
"🧴 Shampoo": "photos/shampoo.jpg"
}
cols = st.columns(3)
for idx, (identify, path) in enumerate(example_images.objects()):
with cols[idx]:
if st.button(identify, use_container_width=True):
st.session_state.selected_example = path
st.session_state.analyze_clicked = False
with tab_upload:
uploaded_file = st.file_uploader(
"Add product picture",
sort=["jpg", "jpeg", "png"],
assist="Add a transparent picture of the product's ingredient checklist"
)
if uploaded_file:
resized_image = resize_image_for_display(uploaded_file)
st.picture(resized_image, caption="Uploaded Picture", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Uploaded Picture", key="analyze_upload"):
temp_path = save_uploaded_file(uploaded_file)
analyze_image(temp_path)
os.unlink(temp_path)
with tab_camera:
camera_photo = st.camera_input("Take an image of the product")
if camera_photo:
resized_image = resize_image_for_display(camera_photo)
st.picture(resized_image, caption="Captured Photograph", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Captured Photograph", key="analyze_camera"):
temp_path = save_uploaded_file(camera_photo)
analyze_image(temp_path)
os.unlink(temp_path)
if st.session_state.selected_example:
st.divider()
st.subheader("Chosen Product")
resized_image = resize_image_for_display(st.session_state.selected_example)
st.picture(resized_image, caption="Chosen Instance", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Instance", key="analyze_example") and never st.session_state.analyze_clicked:
st.session_state.analyze_clicked = True
analyze_image(st.session_state.selected_example)Vital Hyperlinks
- Yow will discover the complete code right here.
- Change the “<replace-with-api-key>” placeholder together with your keys.
- For tab_examples, it’s good to have a folder picture. And save the pictures over there. Right here is the GitHub URL with photos listing right here.
- If you’re inquisitive about utilizing the use case, right here is the deployed App right here.
Conclusion
Multimodal AI brokers characterize a larger leap ahead in how we will work together with and perceive advanced info in our day by day lives. By combining imaginative and prescient processing, pure language understanding, and net search capabilities, these techniques, just like the Product Ingredient Analyzer, can present instantaneous, complete evaluation of merchandise and their components, making knowledgeable decision-making extra accessible to everybody.
Key Takeaways
- Multimodal AI brokers enhance how we perceive product info. They mix textual content and picture evaluation.
- With Phidata, an open-source framework, we will construct and handle agent techniques. These techniques use fashions like GPT-4o and Gemini 2.0.
- Brokers use instruments like imaginative and prescient processing and net search. This makes their evaluation extra full and correct. LLMs have restricted information, so brokers use instruments to deal with advanced duties higher.
- Streamlit makes it simple to construct net apps for LLM-based instruments. Examples embrace RAG and multimodal brokers.
- Good system prompts and directions information the agent. This ensures helpful and correct responses.
Regularly Requested Questions
A. LLaVA (Massive Language and Imaginative and prescient Assistant), Pixtral-12B by Mistral.AI, Multimodal-GPT by OpenFlamingo, NVILA by Nvidia, and Qwen mannequin are a number of open supply or weights multimodal imaginative and prescient language fashions that course of textual content and pictures for duties like visible query answering.
A. Sure, Llama 3 is multimodal, and in addition Llama 3.2 Imaginative and prescient fashions (11B and 90B parameters) course of each textual content and pictures, enabling duties like picture captioning and visible reasoning.
A. A Multimodal Massive Language Mannequin (LLM) processes and generates information throughout numerous modalities, comparable to textual content, photos, and audio. In distinction, a Multimodal Agent makes use of such fashions to work together with its surroundings, carry out duties, and make selections based mostly on multimodal inputs, typically integrating extra instruments and techniques to execute advanced actions.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.
Knowledge Scientist at AI Planet || YouTube- AIWithTarun || Google Developer Professional in ML || Gained 5 AI hackathons || Co-organizer of TensorFlow Person Group Bangalore || Pie & AI Ambassador at DeepLearningAI