

{kind=link}
Performing ad-hoc evaluation is a every day a part of life for many knowledge scientists and analysts on operations groups.
They’re typically held again by not having direct and speedy entry to their knowledge as a result of the information may not be in an information warehouse or it is likely to be saved throughout a number of techniques in several codecs.
This sometimes signifies that an information engineer might want to assist develop pipelines and tables that may be accessed to ensure that the analysts to do their work.
Nonetheless, even right here there may be nonetheless an issue.
Information engineers are often backed-up with the quantity of labor they should do and infrequently knowledge for ad-hoc evaluation may not be a precedence. This results in analysts and knowledge scientists both doing nothing or finagling their very own knowledge pipeline. This takes their time away from what they need to be centered on.
Even when knowledge engineers may assist develop pipelines, the time required for brand spanking new knowledge to get by way of the pipeline may forestall operations analysts from analyzing knowledge because it occurs.
This was, and actually continues to be a significant drawback in massive corporations.
Having access to knowledge.
Fortunately there are many nice instruments right now to repair this! To reveal we will probably be utilizing a free on-line knowledge set that comes from Citi Bike in New York Metropolis, in addition to S3, DynamoDB and Rockset, a real-time cloud knowledge retailer.

Citi Bike Information, S3 and DynamoDB
To arrange this knowledge we will probably be utilizing the CSV knowledge from Citi Bike journey knowledge in addition to the station knowledge that’s right here.
We will probably be loading these knowledge units into two totally different AWS providers. Particularly we will probably be utilizing DynamoDB and S3.
This can permit us to reveal the truth that generally it may be tough to research knowledge from each of those techniques in the identical question engine. As well as, the station knowledge for DynamoDB is saved in JSON format which works nicely with DynamoDB. That is additionally as a result of the station knowledge is nearer to stay and appears to replace each 30 seconds to 1 minute, whereas the CSV knowledge for the precise bike rides is up to date as soon as a month. We are going to see how we will deliver this near-real-time station knowledge into our evaluation with out constructing out sophisticated knowledge infrastructure.
Having these knowledge units in two totally different techniques may even reveal the place instruments can come in useful. Rockset, for instance, has the flexibility to simply be a part of throughout totally different knowledge sources akin to DynamoDB and S3.
As an information scientist or analysts, this will make it simpler to carry out ad-hoc evaluation while not having to have the information reworked and pulled into an information warehouse first.
That being mentioned, let’s begin wanting into this Citi Bike knowledge.
Loading Information With out a Information Pipeline
The journey knowledge is saved in a month-to-month file as a CSV, which suggests we have to pull in every file with a view to get the entire 12 months.
For many who are used to the everyday knowledge engineering course of, you would wish to arrange a pipeline that mechanically checks the S3 bucket for brand spanking new knowledge after which hundreds it into an information warehouse like Redshift.
The information would observe the same path to the one laid out under.
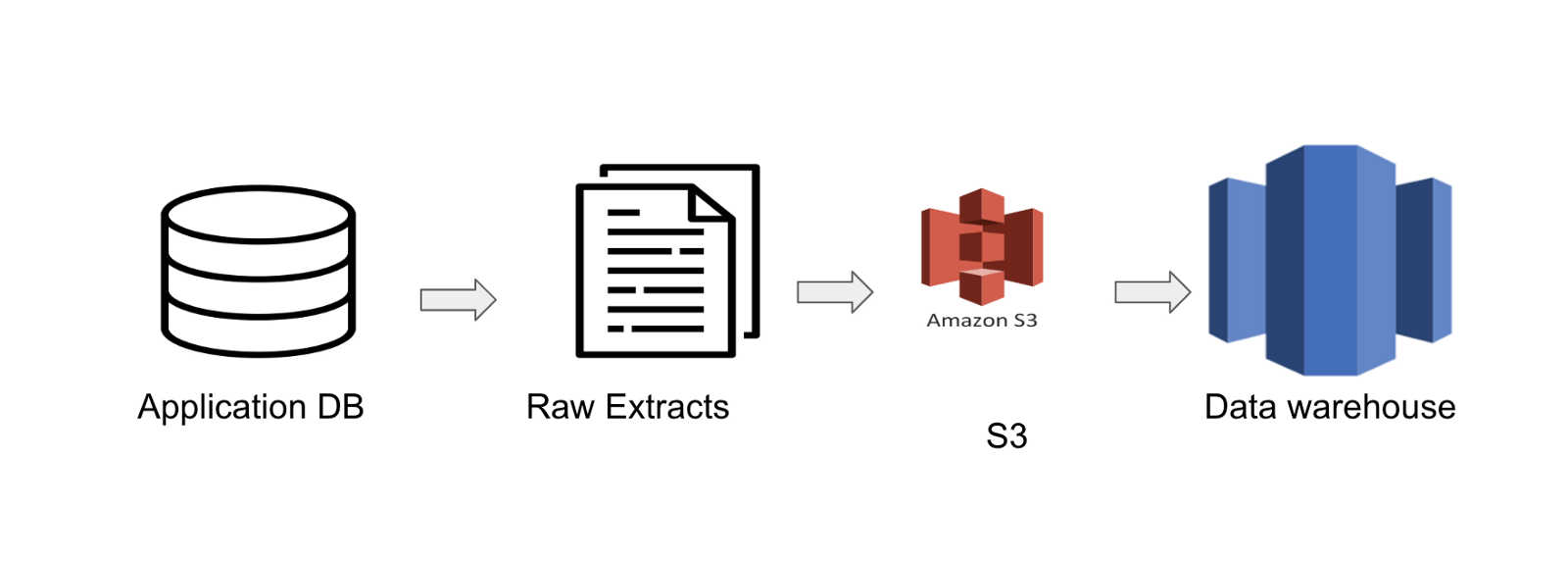
This implies you want an information engineer to arrange a pipeline.
Nonetheless, on this case I didn’t must arrange any type of knowledge warehouse. As a substitute, I simply loaded the recordsdata into S3 after which Rockset handled all of it as one desk.
Regardless that there are 3 totally different recordsdata, Rockset treats every folder as its personal desk. Type of much like another knowledge storage techniques that retailer their knowledge in “partitions” which might be simply primarily folders.
Not solely that, it didn’t freak out if you added a brand new column to the tip. As a substitute, it simply nulled out the rows that didn’t have mentioned column. That is nice as a result of it permits for brand spanking new columns to be added and not using a knowledge engineer needing to replace a pipeline.
Analyzing Citi Bike Information
Usually, a great way to start out is simply to easily plot knowledge out to ensure it considerably is smart (simply in case you might have dangerous knowledge).
We are going to begin with the CSVs saved in S3, and we’ll graph out utilization of the bikes month over month.
Trip Information Instance:

To start out off, we’ll simply graph the journey knowledge from September 2019 to November 2019. Beneath is all you will want for this question.
Embedded content material: https://gist.github.com/bAcheron/2a8613be13653d25126d69e512552716
One factor you’ll discover is that I case the datetime again to a string. It’s because Rockset shops datetime date extra like an object.
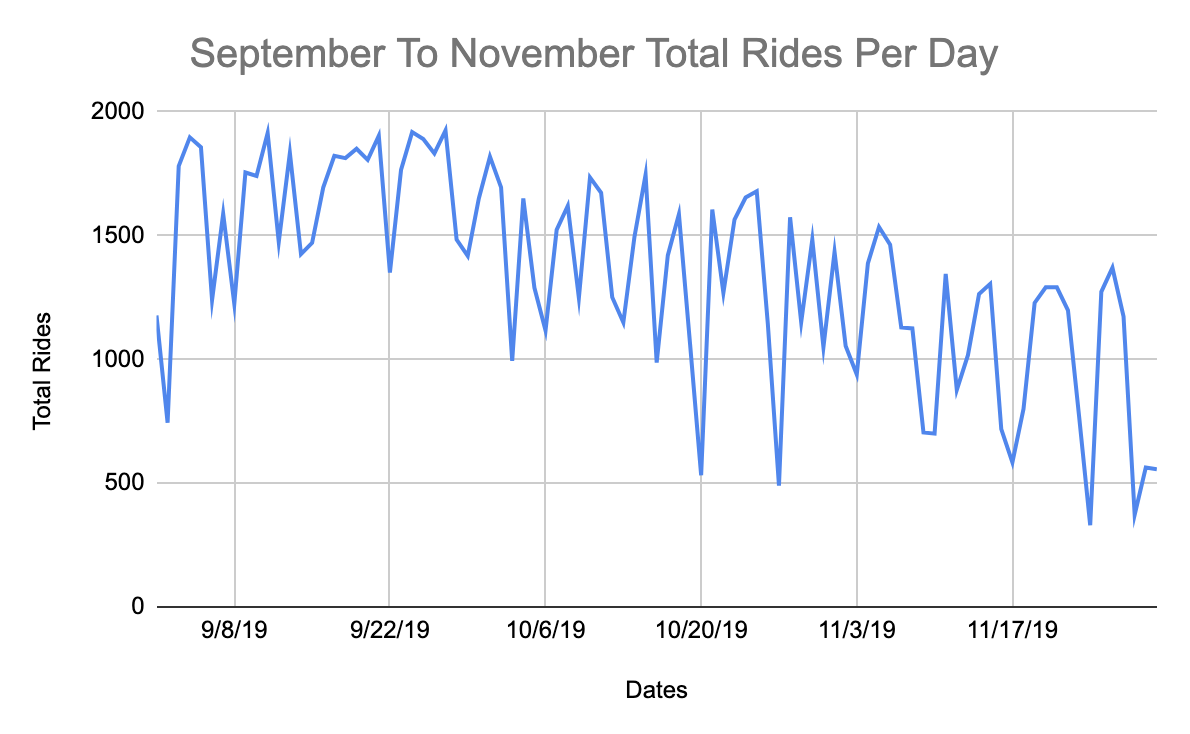
Taking that knowledge I plotted it and you may see cheap utilization patterns. If we actually wished to dig into this we might in all probability look into what was driving the dips to see if there was some type of sample however for now we’re simply attempting to see the final development.
Let’s say you wish to load extra historic knowledge as a result of this knowledge appears fairly constant.
Once more, no must load extra knowledge into an information warehouse. You’ll be able to simply add the information into S3 and it’ll mechanically be picked up.
You’ll be able to take a look at the graphs under, you will note the historical past wanting additional again.
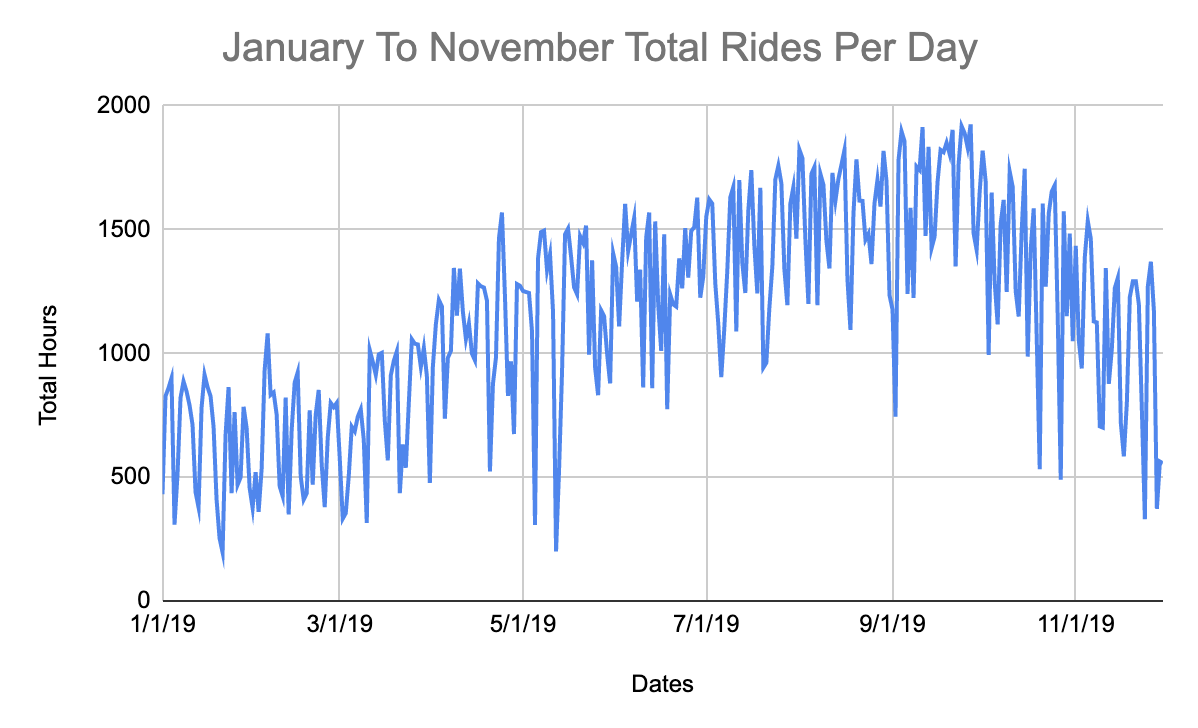
From the attitude of an analyst or knowledge scientist, that is nice as a result of I didn’t want an information engineer to create a pipeline to reply my query in regards to the knowledge development.
Trying on the chart above, we will see a development the place fewer individuals appear to journey bikes in winter, spring and fall however it picks up for summer time. This is smart as a result of I don’t foresee many individuals desirous to exit when it’s raining in NYC.
All in all, this knowledge passes the intestine test and so we’ll take a look at it from a number of extra views earlier than becoming a member of the information.
What’s the distribution of rides on an hourly foundation?
Our subsequent query is asking what’s the distribution of rides on an hourly foundation.
To reply this query, we have to extract the hour from the beginning time. This requires the EXTRACT operate in SQL. Utilizing that hour you’ll be able to then common it whatever the particular date. Our objective is to see the distribution of motorbike rides.
We aren’t going to undergo each step we took from a question perspective however you’ll be able to take a look at the question and the chart under.
Embedded content material: https://gist.github.com/bAcheron/d505989ce3e9bc756fcf58f8e760117b
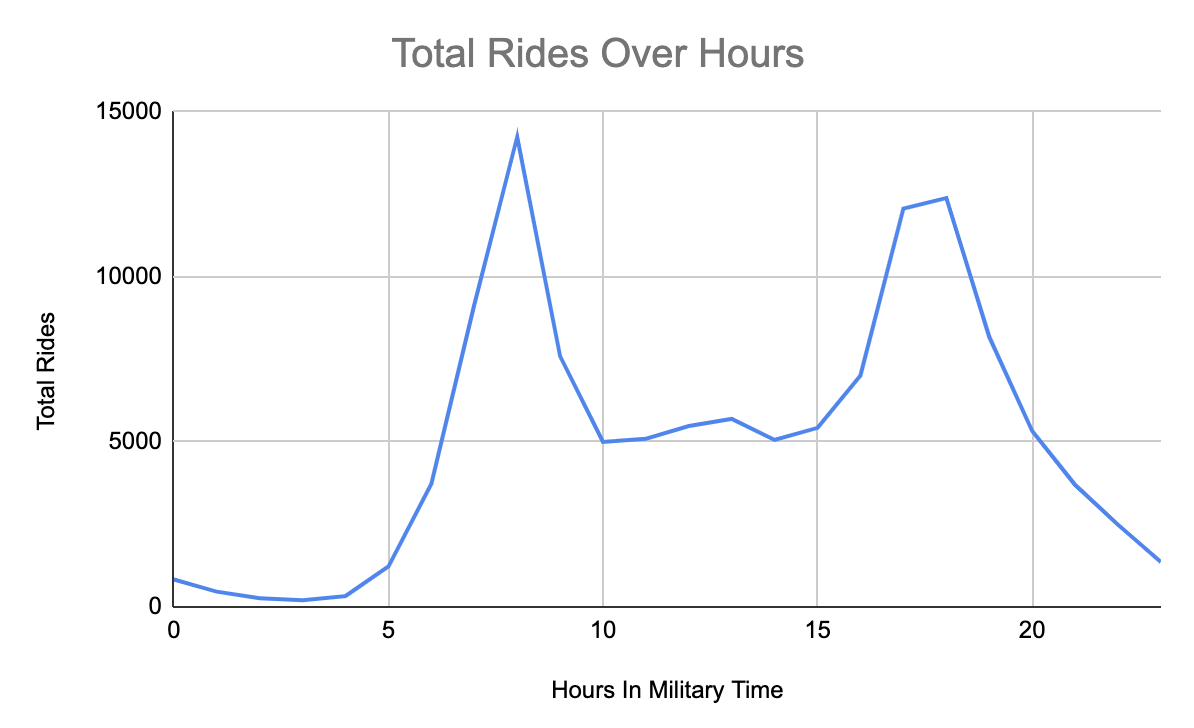
As you’ll be able to see there may be clearly a development of when individuals will journey bikes. Particularly there are surges within the morning after which once more at evening. This may be helpful on the subject of figuring out when it is likely to be a great time to do upkeep or when bike racks are more likely to run out.
However maybe there are different patterns underlying this particular distribution.
What time do totally different riders use bikes?
Persevering with on this thought, we additionally wished to see if there have been particular tendencies per rider sorts. This knowledge set has 2 rider sorts: 3-day buyer passes and annual subscriptions.
So we saved the hour extract and added within the journey sort discipline.
Trying under on the chart we will see that the development for hours appears to be pushed by the subscriber buyer sort.
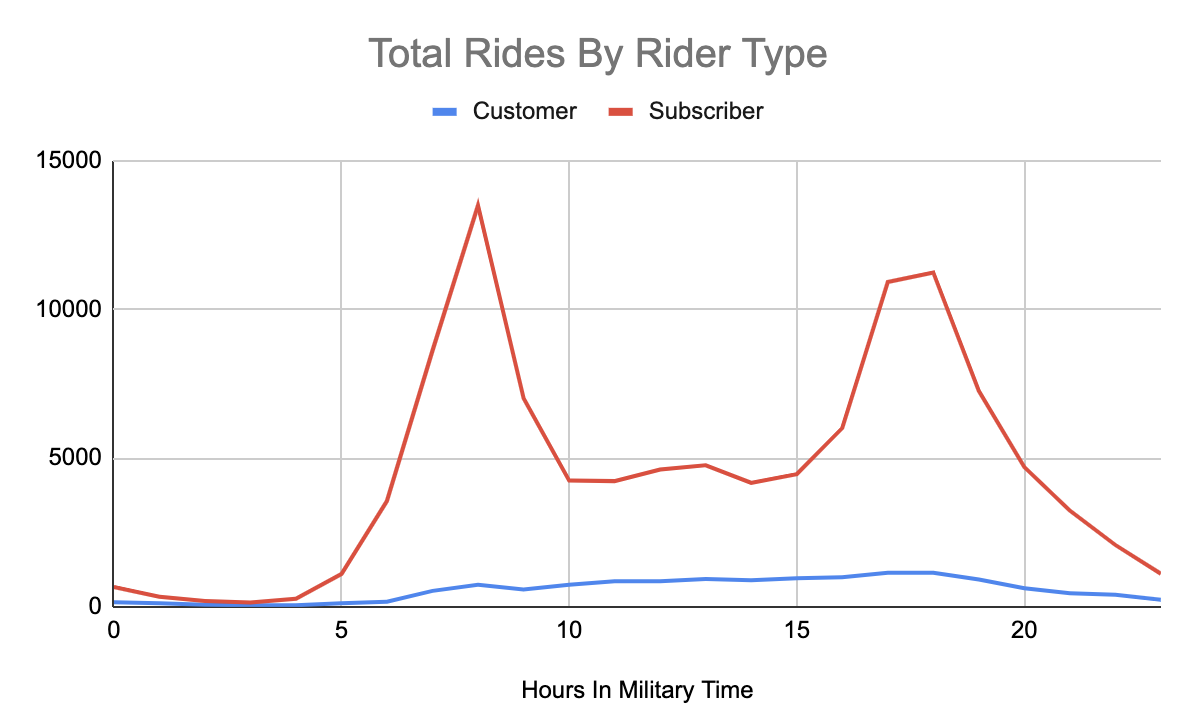
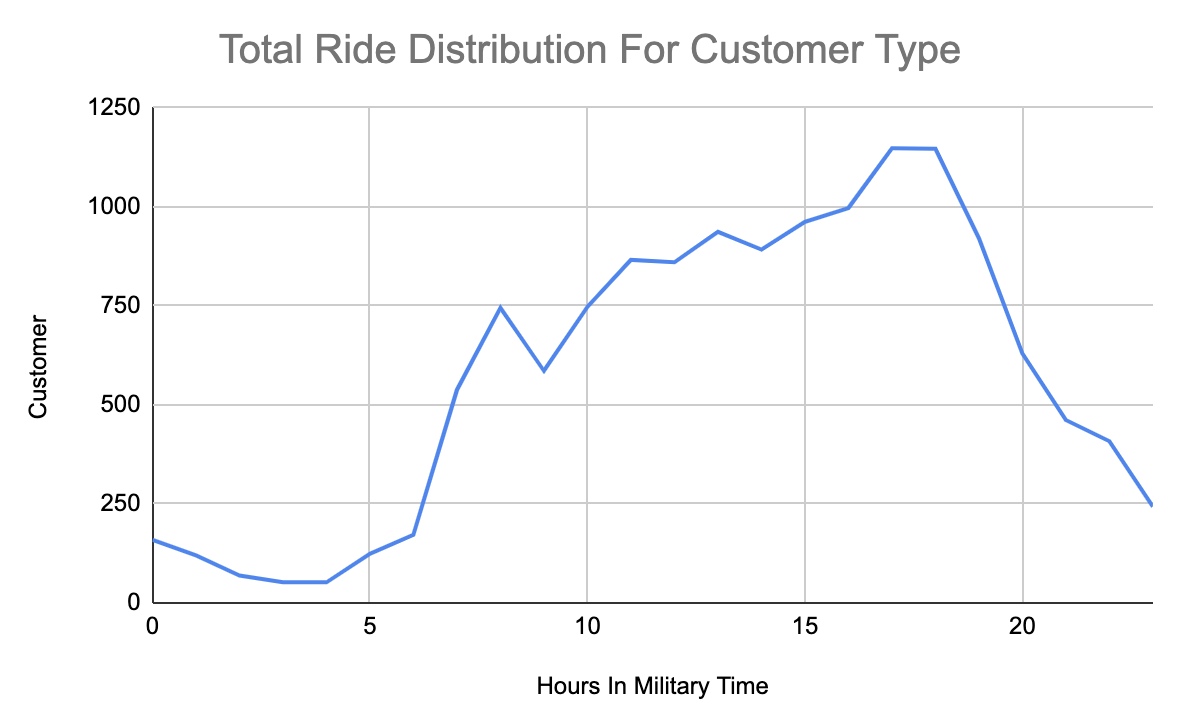
Nonetheless, if we look at the client rider sort we even have a really totally different rider sort. As a substitute of getting two major peaks there’s a gradual rising peak all through the day that peaks round 17:00 to 18:00 (5–6 PM).
It might be attention-grabbing to dig into the why right here. Is it as a result of individuals who buy a 3-day go are utilizing it final minute, or maybe they’re utilizing it from a selected space. Does this development look fixed day over day?
Becoming a member of Information Units Throughout S3 and DynamoDB
Lastly, let’s take part knowledge from DynamoDB to get updates in regards to the bike stations.

One cause we would wish to do that is to determine which stations have 0 bikes left often and now have a excessive quantity of site visitors. This might be limiting riders from having the ability to get a motorcycle as a result of after they go for a motorcycle it’s not there. This may negatively impression subscribers who would possibly anticipate a motorcycle to exist.
Beneath is a question that appears on the common rides per day per begin station. We additionally added in a quartile simply so we will look into the higher quartiles for common rides to see if there are any empty stations.
Embedded content material: https://gist.github.com/bAcheron/28b1c572aaa2da31e43044a743e7b1f3
We listed out the output under and as you’ll be able to see there are 2 stations presently empty which have excessive bike utilization compared to the opposite stations. We might suggest monitoring this over the course of some weeks to see if this can be a widespread incidence. If it was, then Citi Bike would possibly wish to take into account including extra stations or determining a method to reposition bikes to make sure prospects at all times have rides.
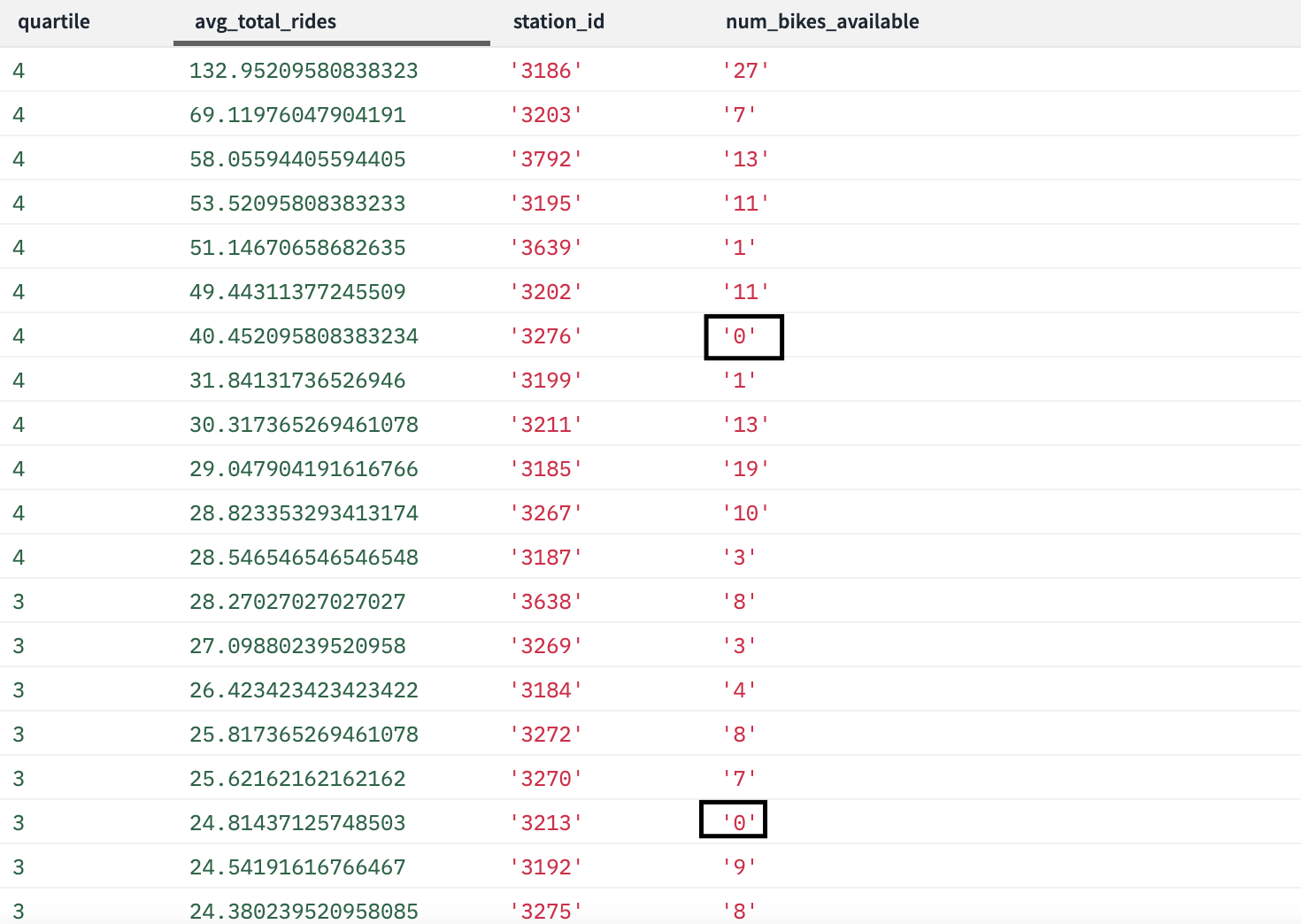
As operations analysts, having the ability to observe which excessive utilization stations are low on bikes stay can present the flexibility to raised coordinate groups that is likely to be serving to to redistribute bikes round city.
Rockset’s means to learn knowledge from an utility database akin to DynamoDB stay can present direct entry to the information with none type of knowledge warehouse. This avoids ready for a every day pipeline to populate knowledge. As a substitute, you’ll be able to simply learn this knowledge stay.
Dwell, Advert-Hoc Evaluation for Higher Operations
Whether or not you’re a knowledge scientist or knowledge analyst, the necessity to wait on knowledge engineers and software program builders to create knowledge pipelines can decelerate ad-hoc evaluation. Particularly as increasingly knowledge storage techniques are created it simply additional complicates the work of everybody who manages knowledge.
Thus, having the ability to simply entry, be a part of and analyze knowledge that isn’t in a conventional knowledge warehouse can show to be very useful and so they can lead fast insights just like the one about empty bike stations.
Ben has spent his profession centered on all types of knowledge. He has centered on creating algorithms to detect fraud, cut back affected person readmission and redesign insurance coverage supplier coverage to assist cut back the general price of healthcare. He has additionally helped develop analytics for advertising and marketing and IT operations with a view to optimize restricted assets akin to workers and price range. Ben privately consults on knowledge science and engineering issues. He has expertise each working hands-on with technical issues in addition to serving to management groups develop methods to maximise their knowledge.
Photograph by ZACHARY STAINES on Unsplash