

{kind=link}
Rockset introduces a brand new structure that permits separate digital cases to isolate streaming ingestion from queries and one software from one other. Compute-compute separation within the cloud presents new efficiencies for real-time analytics at scale with shared real-time information, zero compute competition, quick scale up or down, and limitless concurrency scaling.
The Downside of Compute Rivalry
Actual-time analytics, together with personalization engines, logistics monitoring functions and anomaly detection functions, are difficult to scale effectively. Knowledge functions always compete for a similar pool of compute assets to assist high-volume streaming writes, low latency queries, and excessive concurrency workloads. In consequence, compute competition ensues, inflicting a number of issues for purchasers and prospects:
- Consumer-facing analytics in my SaaS software can solely replace each half-hour for the reason that underlying database turns into unstable at any time when I attempt to course of streaming information constantly.
- When my e-commerce website runs promotions, the huge quantity of writes impacts the efficiency of my personalization engine as a result of my database can not isolate writes from reads.
- We began operating a single logistics monitoring software on the database cluster. Nonetheless, once we added a real-time ETA and automatic routing software, the extra workloads degraded the cluster efficiency. As a workaround, I’ve added replicas for isolation, however the extra compute and storage value is pricey.
- The utilization of my gaming software has skyrocketed within the final 12 months. Sadly, because the variety of customers and concurrent queries on my software will increase, I’ve been pressured to double the dimensions of my cluster as there isn’t any manner so as to add extra assets incrementally.
With all of the above eventualities, organizations should both overprovision assets, create replicas for isolation or revert to batching.
Advantages of Compute-Compute Separation
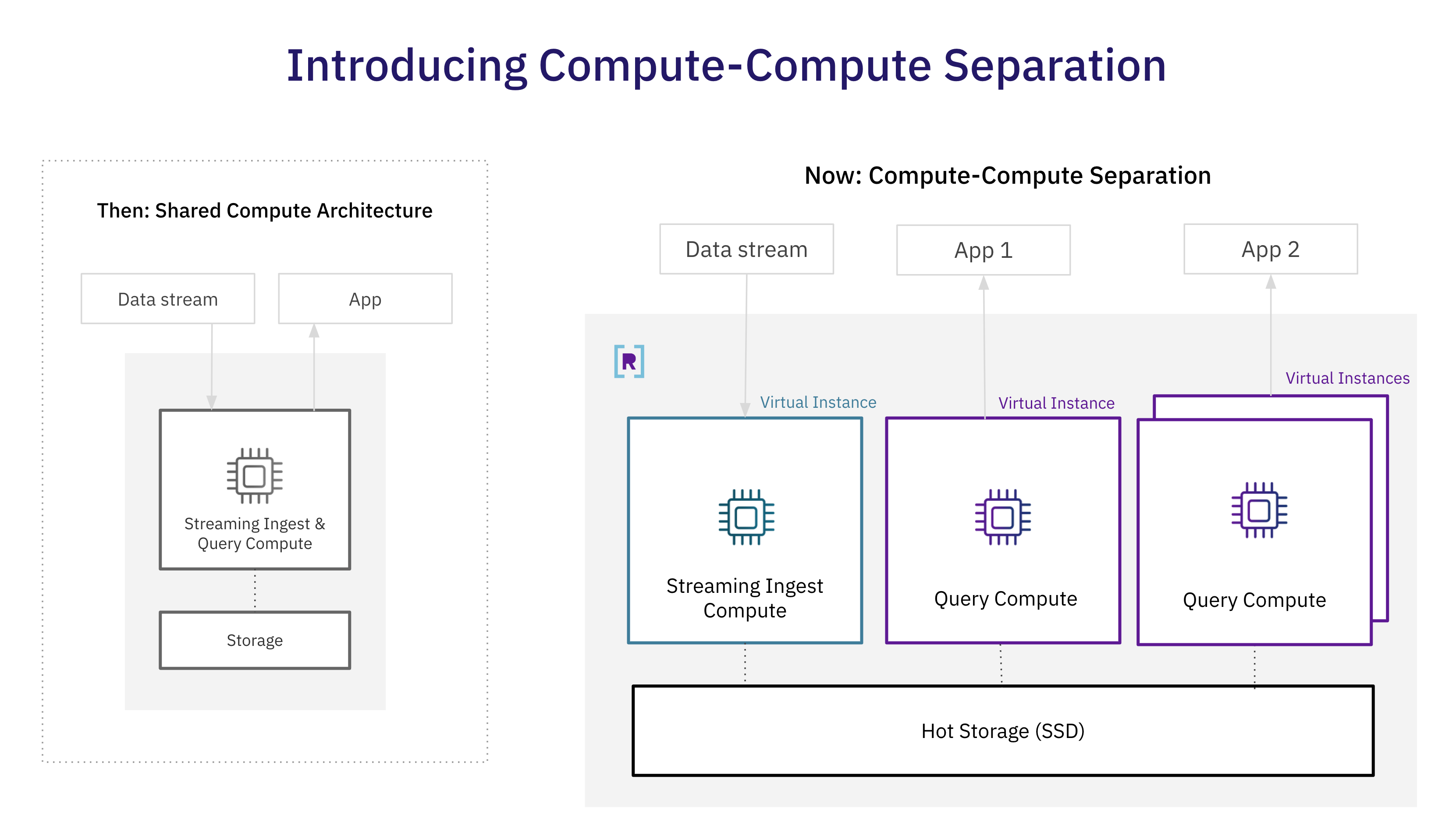
On this new structure, digital cases include the compute and reminiscence wanted for streaming ingest and queries. Builders can spin up or down digital cases primarily based on the efficiency necessities of their streaming ingest or question workloads. As well as, Rockset gives quick information entry by way of the usage of extra performant sizzling storage, whereas cloud storage is used for sturdiness. Rockset’s skill to take advantage of the cloud makes full isolation of compute assets attainable.
Compute-compute separation presents the next benefits:
- Isolation of streaming ingestion and queries
- A number of functions on shared real-time information
- Limitless concurrency scaling
Isolation of Streaming Ingestion and Queries
In first-generation database architectures, together with Elasticsearch and Druid, clusters include the compute and reminiscence for each streaming ingestion and queries, inflicting compute competition. Elasticsearch tried to deal with compute competition by creating devoted ingest nodes to remodel and enrich the doc, however this occurs earlier than indexing, which nonetheless happens on information nodes alongside queries. Indexing and compaction are compute-intensive, and placing these workloads on each information node negatively impacts question efficiency.
In distinction, Rockset allows a number of digital cases for compute isolation. Rockset locations compute-intensive ingest operations, together with indexing and dealing with updates, on the streaming ingest digital occasion after which makes use of a RocksDB CDC log to ship the updates, inserts, and deletes to question digital cases. In consequence, Rockset is now the one real-time analytics database to isolate streaming ingest from question compute while not having to create replicas.
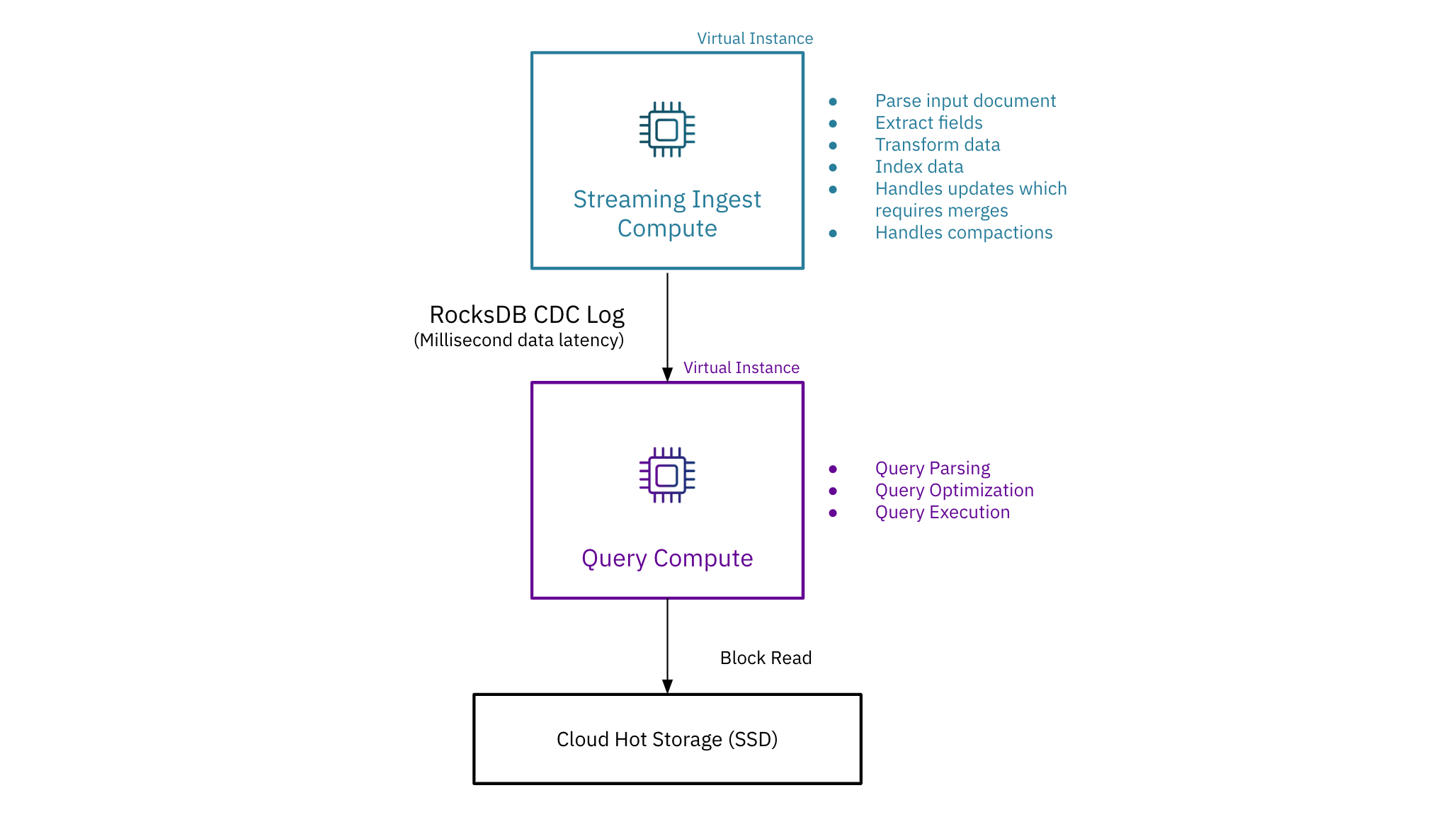
A number of Purposes on Shared Actual-Time Knowledge
Till this level, the separation of storage and compute relied on cloud object storage which is economical however can not meet the pace calls for of real-time analytics. Now, customers can run a number of functions on information that’s seconds outdated, the place every software is remoted and sized primarily based on its efficiency necessities. Creating separate digital cases, every sized for the applying wants, eliminates compute competition and the necessity to overprovision compute assets to satisfy efficiency. Moreover, shared real-time information reduces the price of sizzling storage considerably, as just one copy of the information is required.
Limitless Concurrency
Clients can dimension the digital occasion for the specified question efficiency after which scale out compute for greater concurrency workloads. In different techniques that use replicas for concurrency scaling, every duplicate must individually course of the incoming information from the stream which is compute-intensive. This additionally provides load on the information supply because it must assist a number of replicas. Rockset processes the streaming information as soon as after which scales out, leaving compute assets for question execution.
How Compute-Compute Separation Works
Let’s stroll by way of how compute-compute separation works utilizing streaming information from the Twitter firehose to serve a number of functions:
- an software that includes essentially the most tweeted inventory ticker symbols
- an software that includes essentially the most tweeted hashtags
Right here’s what the structure will seem like:
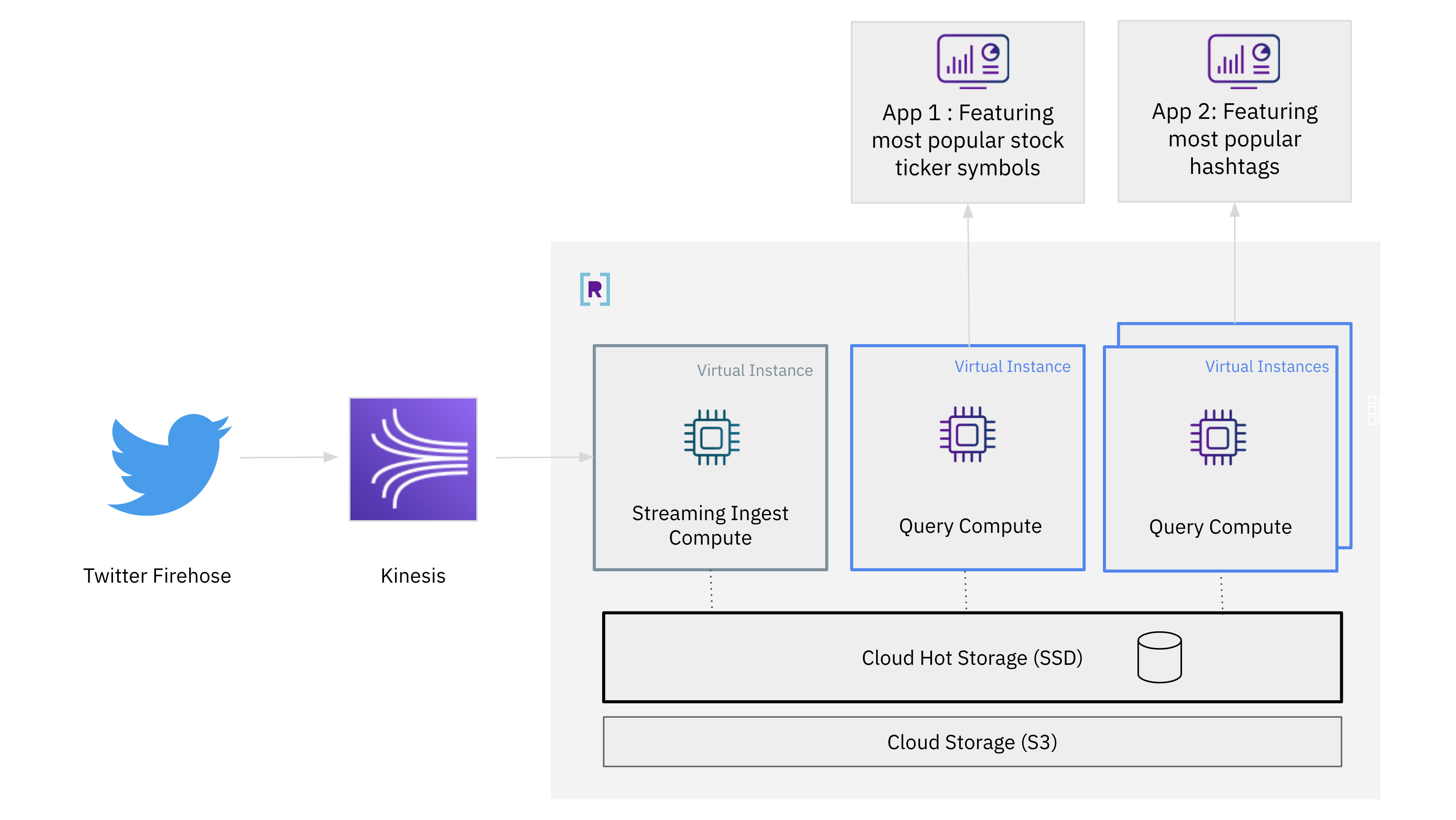
- We’ll stream information from the Twitter Firehose into Rockset utilizing the occasion streaming platform Amazon Kinesis
- We’ll then create a group from the Twitter information. The default digital occasion might be devoted to streaming ingestion on this instance.
- We’ll then create an extra digital occasion for question processing. This digital occasion will discover essentially the most tweeted inventory ticker symbols on Twitter.
- Repeating the identical course of, we will create one other digital occasion for question processing. This digital occasion will discover the most well-liked hashtags on Twitter.
- We’ll scale out to a number of digital cases to deal with high-concurrency workloads.
Step 1: Create a Assortment that Syncs Twitter Knowledge from the Kinesis Stream
In preparation for the walk-through of compute-compute separation, I arrange an integration to Amazon Kinesis utilizing AWS Cross-Account IAM roles and AWS Entry Keys. Then, I used the mixing to create a group, twitter_kinesis_30day, that syncs Twitter information from the Kinesis stream.
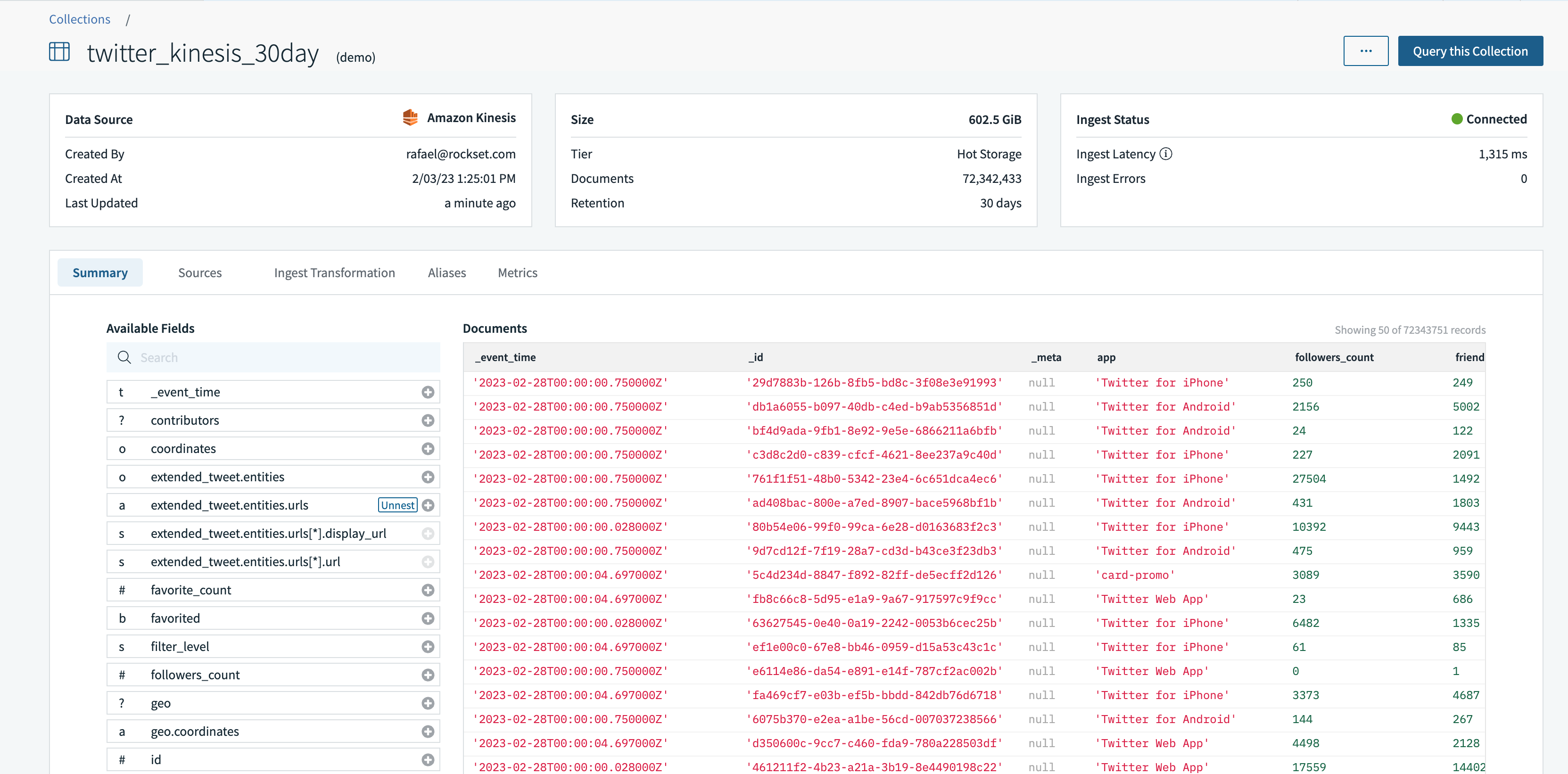
At assortment creation time, I can even create ingest transformations together with utilizing SQL rollups to constantly combination information. On this instance, I used ingest transformations to forged a date as a timestamp, parse a area and extract nested fields.
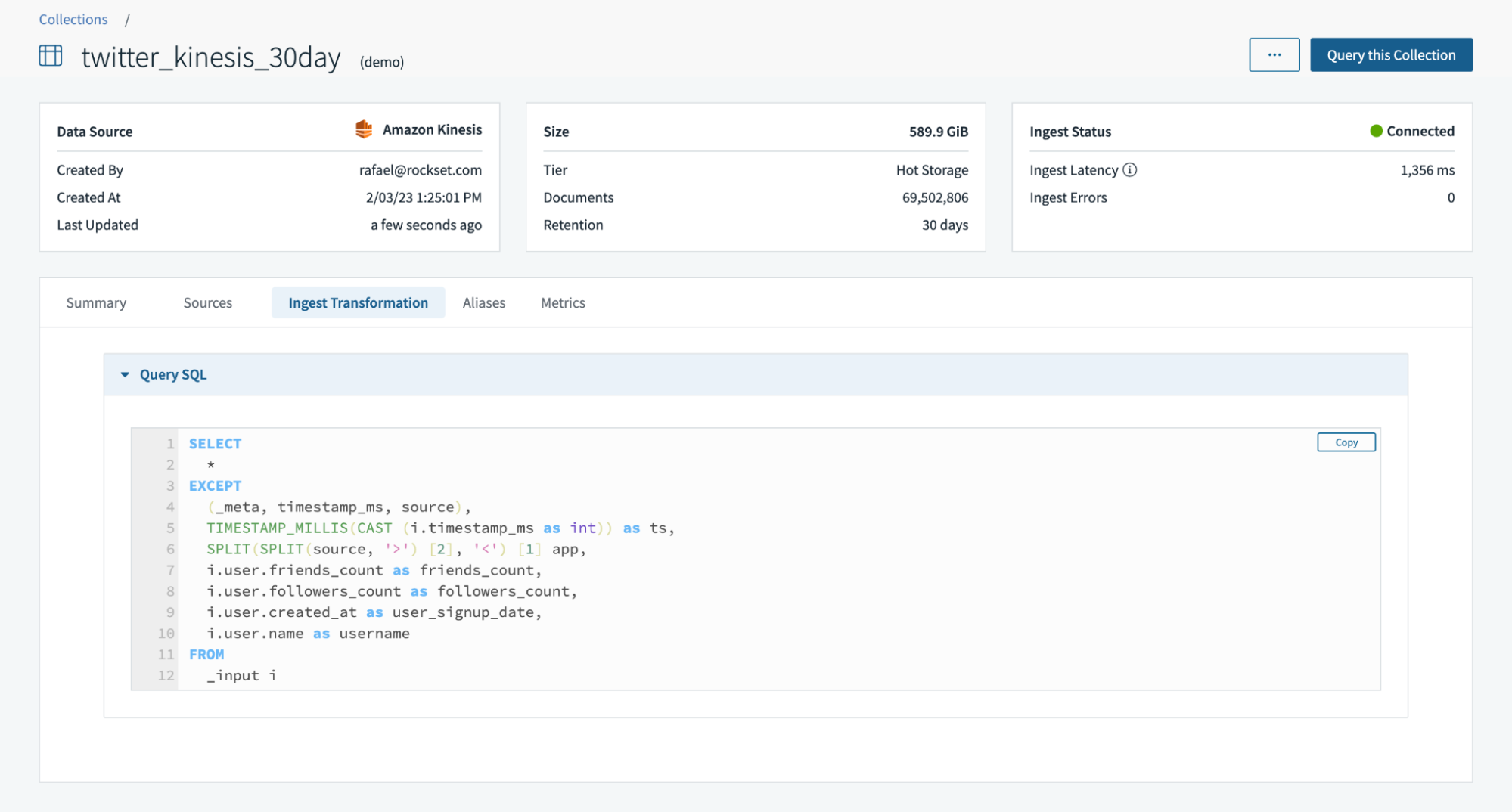
The default digital occasion is chargeable for streaming information ingestion and ingest transformations.
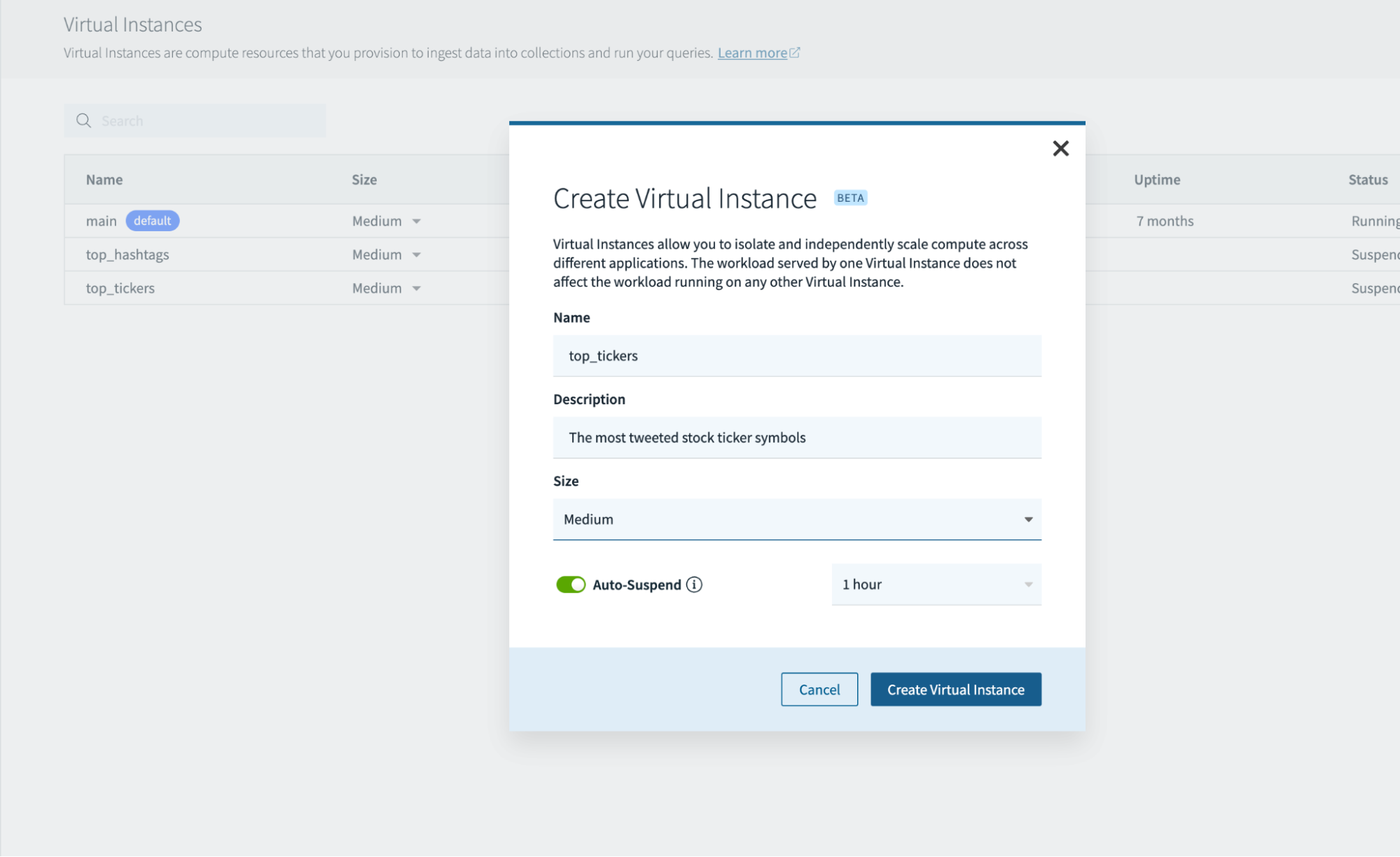
Step 2: Create A number of Digital Situations
Heading to the digital cases tab, I can now create and handle a number of digital cases, together with:
- altering the variety of assets in a digital occasion
- mounting or associating a digital occasion with a group
- setting the suspension coverage of a digital occasion to save lots of on compute assets
On this state of affairs, I wish to isolate streaming ingest compute and question compute. We’ll create secondary digital cases to serve queries that includes:
- essentially the most tweeted inventory ticker symbols
- essentially the most tweeted hashtags
The digital occasion is sized primarily based on the latency necessities of the applying. It will also be auto-suspended as a consequence of inactivity.
Step 3: Mount Collections to Digital Situations
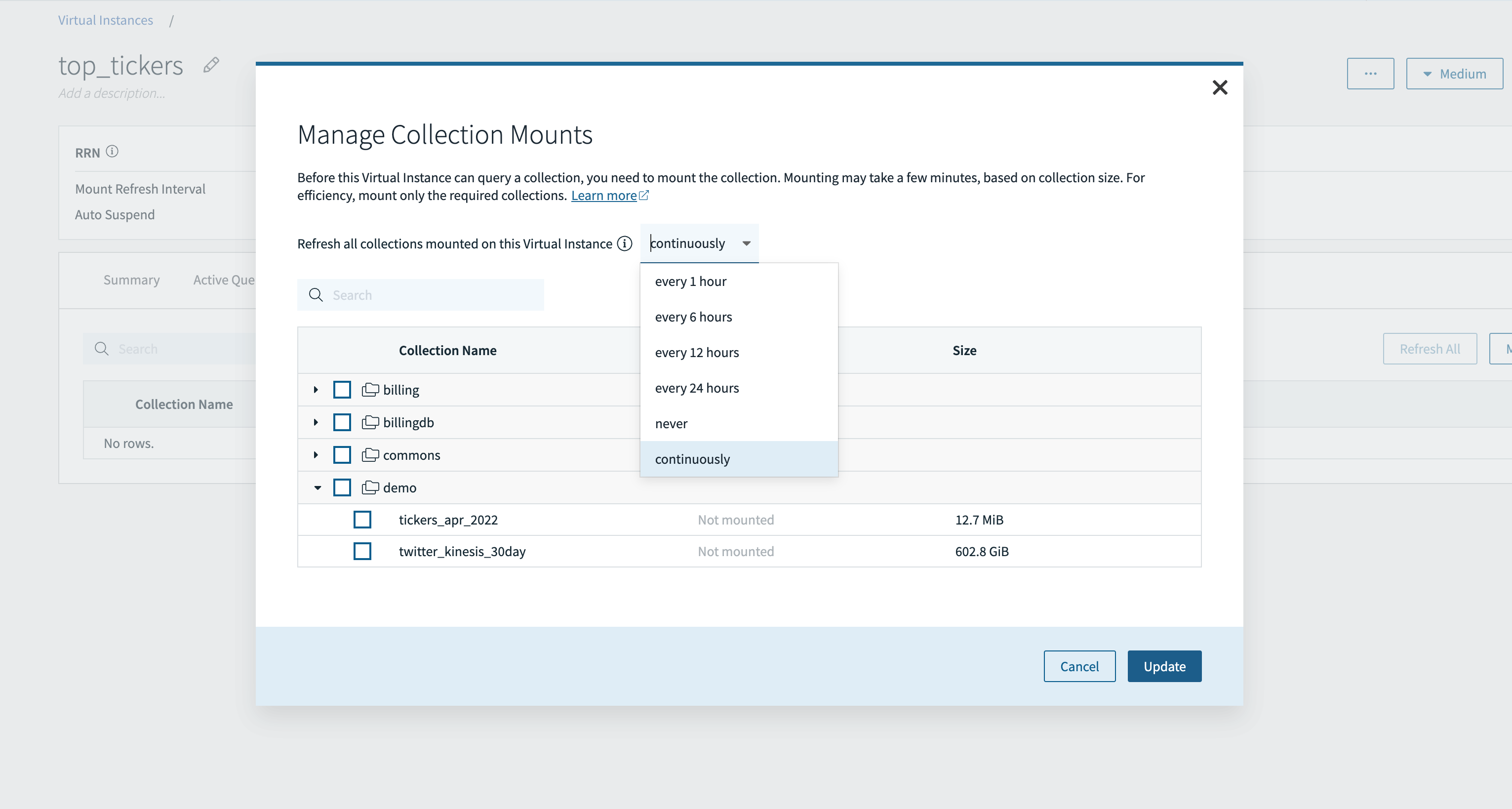
Earlier than I can question a group, I first must mount the gathering to the digital occasion.
On this instance, I’ll mount the Twitter kinesis assortment to the top_tickers digital occasion, so I can run queries to search out essentially the most tweeted about inventory ticker symbols. As well as, I can select a periodic or steady refresh relying on the information latency necessities of my software. The choice for steady refresh is at the moment out there in early entry.
Step 4: Run Queries Towards the Digital Occasion
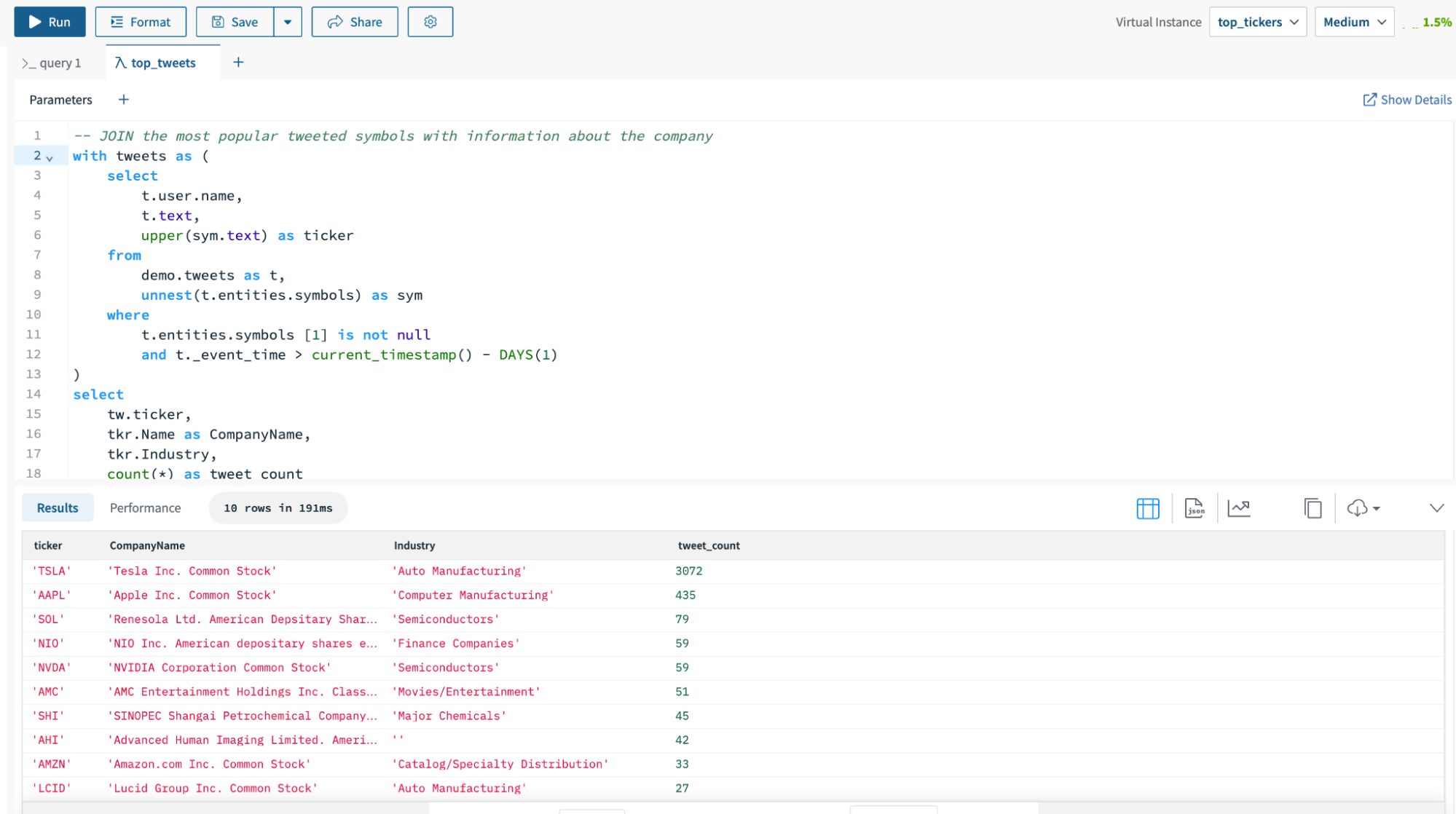
I’ll go to the question editor to run the SQL question towards the top_tickers digital occasion.
I created a SQL question to search out the inventory ticker symbols with essentially the most mentions on Twitter within the final 24 hours. Within the higher proper hand nook of the question editor, I chosen the digital occasion top_tickers to serve the question. You’ll be able to see that the question executed in 191 ms.
Step 5: Scale Out to Assist Excessive Concurrency Workloads
Let’s now scale out to assist excessive concurrency workloads. In JMeter, I simulated 20 queries per second and recorded a median latency of 1613 ms for the queries.
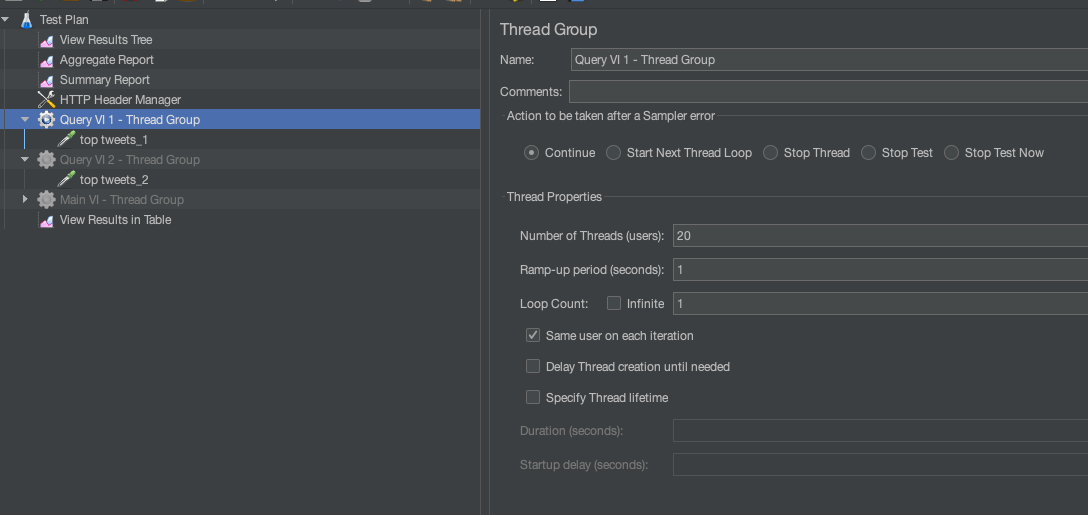
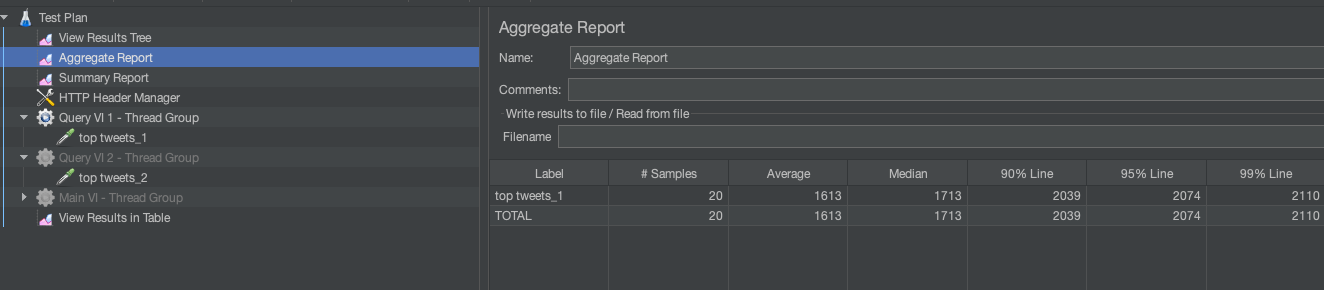
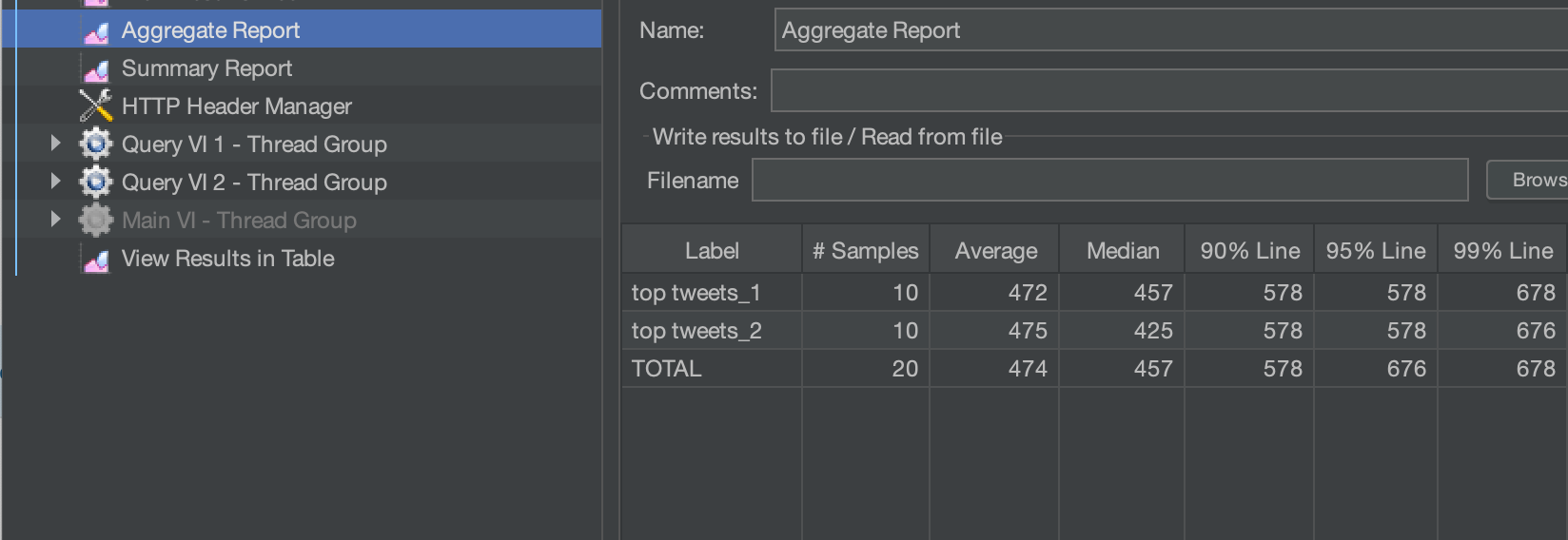
If my SLA for my software is underneath 1 second, I’ll wish to scale out compute. I can scale out immediately and you’ll see that including one other medium Digital Occasion took the latency down for 20 queries to a median of 457 ms.
Discover Compute-Compute Separation
We now have explored easy methods to create a number of digital cases for streaming ingest, low-latency queries, and a number of functions. With the discharge of compute-compute separation within the cloud, we’re excited to make real-time analytics extra environment friendly and accessible. Check out the public beta of compute-compute separation as we speak by beginning a free trial of Rockset.