

{kind=link}
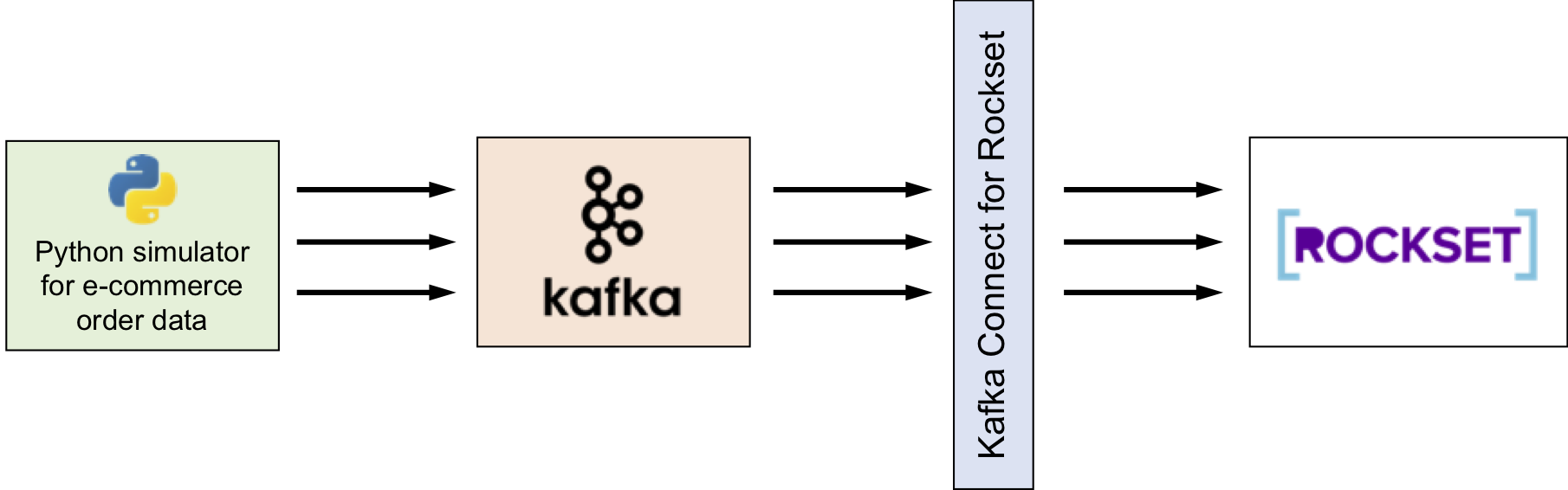
This publish presents a how-to information to real-time analytics utilizing SQL on streaming knowledge with Apache Kafka and Rockset, utilizing the Rockset Kafka Connector, a Kafka Join Sink.
Kafka is often utilized by many organizations to deal with their real-time knowledge streams. We’ll present how Rockset integrates with Kafka to ingest and index our fast-moving occasion knowledge, enabling us to construct operational apps and dwell dashboards on high of Rockset. We’ll use a simulated occasion stream of orders on an e-commerce web site for this instance.
Organising Your Surroundings
We’ll present all of the steps you will want to attach Kafka and Rockset, and run some easy advert hoc queries and visualizations.
Kafka Cluster
If you have already got a Kafka cluster prepared and knowledge flowing by means of it, then you’ll be able to skip this portion of the information. In any other case, arrange a Kafka cluster and confirm it’s operating. A Kafka quickstart tutorial will be discovered right here. A single-node Kafka cluster is enough for the instance on this weblog, though it’s your decision a multi-node cluster for additional work with Kafka and Rockset.
Python
All of the code used on this weblog is out there below kafka-rockset-integration within the Rockset recipes repository. The Python code supplied will simulate e-commerce order occasions and write them to Kafka. The next steps will information you in downloading the code and organising the Python atmosphere.
git clone git@github.com:rockset/recipes.git
cd recipes/kafka-rockset-integration/
Create and activate Python digital atmosphere rockset-kafka-demo and set up all of the Python dependencies.
python3 -m virtualenv rockset-kafka-demo
supply rockset-kafka-demo/bin/activate
pip set up -r necessities.txt
Open config.py in your favourite editor and replace the next configuration parameters. You will want to enter your Rockset API key.
# Kafka Configuration
KAFKA_TOPIC = 'orders'
KAFKA_BOOTSTRAP_SERVER = ['localhost:9092']
# Rockset Configuration
ROCKSET_API_KEY = '' # Create API Key - https://console.rockset.com/handle/apikeys
ROCKSET_API_SERVER = 'https://api.rs2.usw2.rockset.com'
Making a Assortment in Rockset
We’ll use the rock CLI instrument to handle and question our knowledge in Rockset.
Putting in the rock CLI instrument has already been carried out in as a part of the pip set up -r necessities.txt step above. Alternatively, you’ll be able to set up the rock CLI instrument with the pip3 set up rockset command.
Configure the rock CLI shopper together with your Rockset API key.
rock configure --api_key <YOUR-API-KEY>
Create a Rockset assortment named orders.
rock create assortment orders
--event-time-field=InvoiceDate
--event-time-format=seconds_since_epoch
The --event-time-field=InvoiceDate choice instructs Rockset to deal with a doc’s InvoiceDate as its _event_time, a particular area used to deal with time-series knowledge effectively.
Learn extra about particular fields in Rockset and dealing with occasion knowledge. Customers working with occasion knowledge in Rockset can set time-based retention insurance policies on their knowledge.
Connecting Rockset to Kafka
Kafka Join, an open-source element of Apache Kafka, is a framework for connecting Kafka with exterior programs similar to databases, key-value shops, search indexes, and file programs. Rockset supplies Kafka Join for Rockset, a Kafka Join Sink that helps load knowledge from Kafka right into a Rockset assortment.
Kafka Join for Rockset will be run in standalone or distributed mode. For the scope of this weblog, the next steps clarify learn how to arrange Kafka Join for Rockset in standalone mode.
Construct
Clone the repo
git clone https://github.com/rockset/kafka-connect-rockset.git
cd kafka-connect-rockset
Construct a maven artifact
mvn bundle
This can construct the jar within the /goal listing. Its title might be kafka-connect-rockset-[VERSION]-SNAPSHOT-jar-with-dependencies.jar.
Open the file ./config/connect-standalone.properties, which accommodates the configuration required for Kafka Join. Replace the next configuration values.
bootstrap.servers=localhost:9092
plugin.path=/path/to/kafka-connect-rockset-[VERSION]-SNAPSHOT-jar-with-dependencies.jar
Open the file ./config/connect-rockset-sink.properties to configure Rockset-specific properties.
subjects – That is the checklist of comma-separated Kafka subjects that needs to be watched by this Rockset Kafka Connector
subjects=orders
rockset.assortment – The Rockset connector will write knowledge into this assortment
rockset.assortment=orders
rockset.apikey – Use the API Key of your Rockset account
Run
Begin Kafka Rockset Join and preserve the terminal open to observe progress.
$KAFKA_HOME/bin/connect-standalone.sh ./config/connect-standalone.properties ./config/connect-rockset-sink.properties
Seek advice from the documentation to arrange Kafka Join for Rockset in distributed mode and for different configuration data.
Ingesting Information from Kafka into Rockset
Ensure all of the elements (Kafka cluster, Kafka Join for Rockset) are up and operating.
Confirm Zookeeper is up.
jps -l | grep org.apache.zookeeper.server
[process_id] org.apache.zookeeper.server.quorum.QuorumPeerMain
Confirm Kafka is up.
jps -l | grep kafka.Kafka
[process_id] kafka.Kafka
Confirm Kafka Join for Rockset is up.
curl localhost:8083/connectors
["rockset-sink"]
Begin writing new knowledge into Kafka. write_data_into_kafka.py will generate 1 to 300 orders each second throughout a number of e-commerce clients and international locations. (We borrowed the product set from this e-commerce knowledge set and randomly generate orders for this instance from this set.)
python write_data_into_kafka.py
Writing information into Kafka. Kafka Server - localhost:9092, Subject - orders
100 information are written
200 information are written
300 information are written
400 information are written
500 information are written
600 information are written
...
Lengthy output forward
The JSON knowledge for an instance order containing two totally different merchandise is proven under.
{
"InvoiceNo": 14,
"InvoiceDate": 1547523082,
"CustomerID": 10140,
"Nation": "India",
"StockCode": 3009,
"Description": "HAND WARMER RED POLKA DOT",
"Amount": 6,
"UnitPrice": 1.85
}
{
"InvoiceNo": 14,
"InvoiceDate": 1547523082,
"CustomerID": 10140,
"Nation": "India",
"StockCode": 3008,
"Description": "HAND WARMER UNION JACK",
"Amount": 2,
"UnitPrice": 1.85
}
In your terminal the place Kafka Join for Rockset is operating, observe that the Rockset sink is energetic and paperwork are being ingested into your Rockset assortment.
[2019-01-08 17:33:44,801] INFO Added doc: {"Invoi... (rockset.RocksetClientWrapper:37)
[2019-01-08 17:33:44,802] INFO Added doc: {"Invoi... (rockset.RocksetClientWrapper:37)
[2019-01-08 17:33:44,838] INFO Added doc: {"Invoi... (rockset.RocksetClientWrapper:37)
...
Lengthy output forward
Operating SQL Queries in Rockset
The orders assortment is prepared for querying as quickly as knowledge ingestion is began. We’ll present some frequent queries you’ll be able to run on the e-commerce knowledge.
Open a SQL command line.
rock sql
Let’s strive a easy question.
SELECT *
FROM orders
LIMIT 10;
It’s best to see the output of the above question in a tabular format. You’ll discover the particular fields _id and _event_time within the output, as talked about earlier within the weblog.
Let’s dig into the info and get some insights. Word that the outcomes you get might be totally different from these, as a result of the order knowledge is generated randomly and repeatedly.
Highest Promoting Merchandise
Question
SELECT Description, SUM(Amount) as QuantitiesSold
FROM "orders"
GROUP BY Description
ORDER By QuantitiesSold DESC
LIMIT 5;
Output
+------------------------------------+------------------+
| Description | QuantitiesSold |
|------------------------------------+------------------|
| ASSORTED COLOUR BIRD ORNAMENT | 87786 |
| WHITE METAL LANTERN | 65821 |
| WHITE HANGING HEART T-LIGHT HOLDER | 65319 |
| CREAM CUPID HEARTS COAT HANGER | 43978 |
| RED WOOLLY HOTTIE WHITE HEART. | 43260 |
+------------------------------------+------------------+
Time: 0.423s
Variety of Orders by Nation
Question
SELECT Nation, COUNT(DISTINCT InvoiceNo) as TotalOrders
FROM "orders"
GROUP BY Nation
ORDER By TotalOrders DESC;
Output
+----------------+---------------+
| Nation | TotalOrders |
|----------------+---------------|
| United States | 4762 |
| India | 3304 |
| China | 3242 |
| United Kingdom | 1610 |
| Canada | 1524 |
+----------------+---------------+
Time: 0.395s
Minute-By-Minute Gross sales
We’ve used very acquainted SQL constructs like mixture features, GROUP BY, and ORDER BY up until now. Let’s strive subqueries written utilizing the WITH clause to indicate whole gross sales noticed each minute.
Question
WITH X AS (
SELECT InvoiceNo, FORMAT_TIMESTAMP('%H:%M', DATETIME(_event_time)) as Minute, SUM(UnitPrice) as OrderValue
FROM "orders"
GROUP BY InvoiceNo, _event_time
)
SELECT Minute, CEIL(SUM(OrderValue)) as TotalSale
FROM X
GROUP BY Minute
ORDER BY Minute;
Output
+------------------+-------------+
| Minute | TotalSale |
|------------------+-------------|
| 2019-01-08 11:52 | 40261.0 |
| 2019-01-08 11:53 | 66759.0 |
| 2019-01-08 11:54 | 72043.0 |
| 2019-01-08 11:55 | 56221.0 |
+------------------+-------------+
Time: 0.451s
You’ll be able to simply carry out different advert hoc SQL queries on the info at any time. The write_data_into_kafka.py script will preserve streaming the orders knowledge repeatedly. You’ll be able to stream as a lot as you need to get extra knowledge written into Rockset assortment.
Becoming a member of Kafka Occasion Information with CSV Information in S3
For instance that now we have buyer knowledge from one other supply that we need to be a part of with our orders knowledge for evaluation. With Rockset, we will simply ingest knowledge from a variety of knowledge sources and mix it with our Kafka stream utilizing SQL.
The kafka-rockset-integration listing accommodates a clients.csv file containing the CustomerID and AcquisitionSource of every buyer. We’ll retailer this knowledge on how clients had been acquired in Amazon S3 and create a Rockset assortment from it.
head clients.csv
CustomerID,AcquisitionSource
10000,Show
10001,AffiliateReferral
10002,OrganicSearch
10003,OrganicSearch
10004,Show
10005,SocialMedia
10006,OrganicSearch
10007,SocialMedia
10008,AffiliateReferral
Add the clients.csv file to S3 following these directions for organising an S3 bucket. Out of your S3 supply, create a Rockset assortment named clients, primarily based on clients.csv.
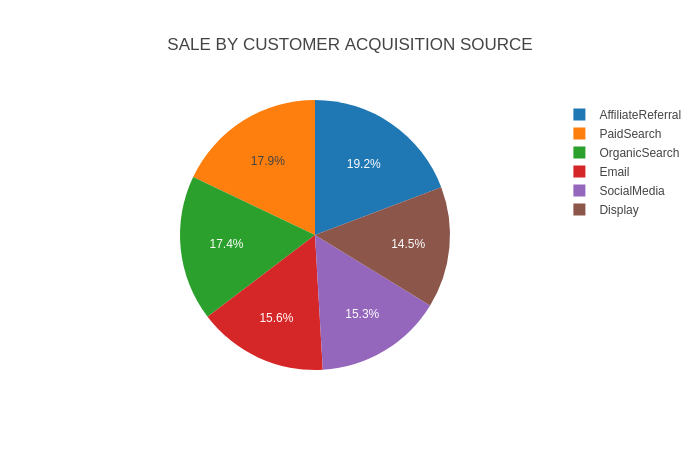
Gross sales by Buyer Acquisition Supply
Be a part of the real-time orders knowledge coming from Kafka with buyer acquisition knowledge to find out the full gross sales by buyer acquisition supply. The next question demonstrates an interior be a part of on the CustomerID area between the orders assortment, from Kafka, and the clients assortment, from S3.
Question
SELECT C.AcquisitionSource, CEIL(SUM(O.UnitPrice)) as TotalSale
FROM clients AS C JOIN orders as O on O.CustomerID = Forged(C.CustomerID AS integer)
GROUP BY C.AcquisitionSource
ORDER BY TotalSale DESC
Output
+---------------------+-------------+
| AcquisitionSource | TotalSale |
|---------------------+-------------|
| AffiliateReferral | 45779.0 |
| PaidSearch | 42668.0 |
| OrganicSearch | 41467.0 |
| Electronic mail | 37040.0 |
| SocialMedia | 36509.0 |
| Show | 34516.0 |
+---------------------+-------------+
Visualize
Now that we’ve run some SQL queries on the order knowledge in Rockset, let’s prolong our instance. The supplied code features a visualize.py script, which interprets Rockset question outcomes into graphical widgets. The script makes use of the Sprint library to plot the outcomes graphically. (It’s doable to make use of knowledge visualization instruments like Tableau, Apache Superset, Redash, and Grafana as effectively.)
Run visualize.py.
python visualize.py
Open a dashboard in your browser.
http://127.0.0.1:8050/
You’ll be able to see some dashboard widgets plotted utilizing Sprint over the Rockset knowledge.
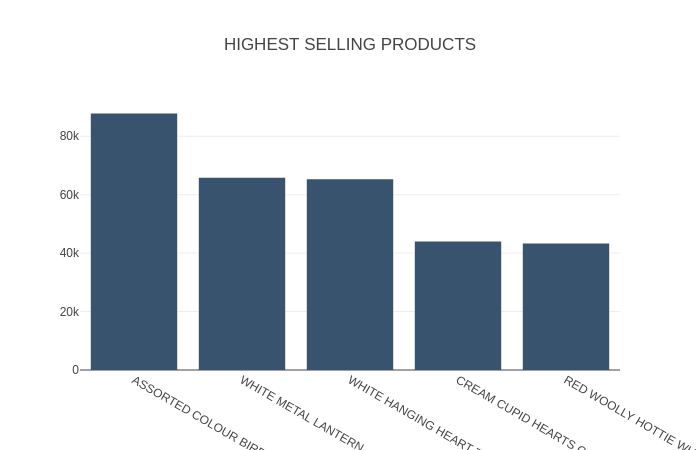
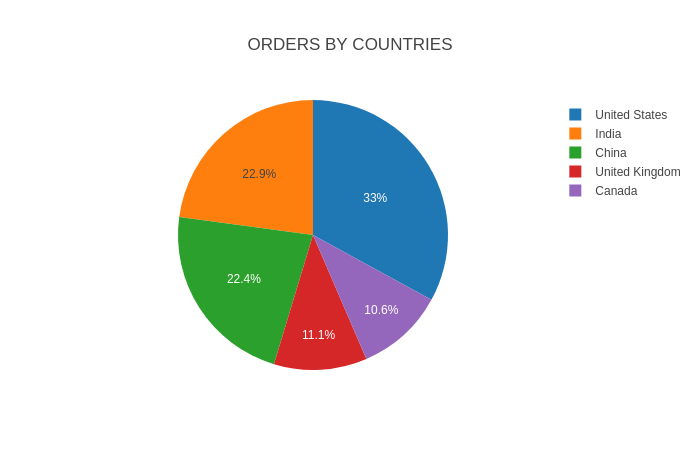
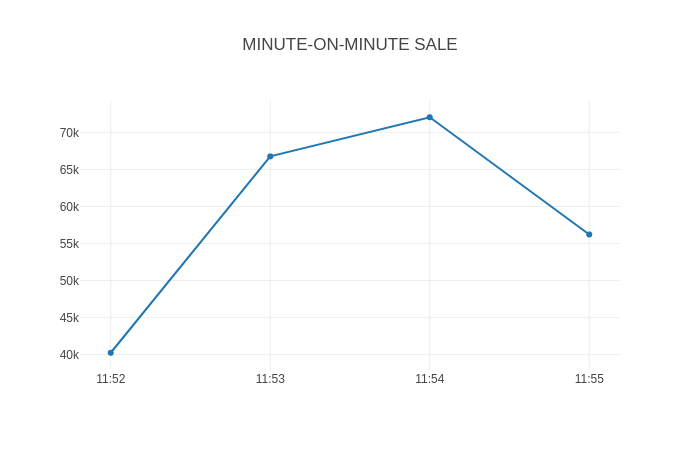
Conclusion
With Rockset, you’ll be able to construct apps with out writing advanced ETL pipelines. Rockset repeatedly syncs new knowledge because it lands in your knowledge sources with out the necessity for a set schema. The Kafka-Rockset integration outlined above means that you can construct operational apps and dwell dashboards rapidly and simply, utilizing SQL on real-time occasion knowledge streaming by means of Kafka.
Go to our Kafka options web page for extra data on constructing real-time dashboards and APIs on Kafka occasion streams.