

{kind=link}
Giant Language Fashions (LLMs) have the potential to automate and cut back the workloads of many varieties, together with these of cybersecurity analysts and incident responders. However generic LLMs lack the domain-specific information to deal with these duties properly. Whereas they could have been constructed with coaching information that included some cybersecurity-related sources, that’s usually inadequate for taking over extra specialised duties that require extra updated and, in some instances, proprietary information to carry out properly—information not out there to the LLMs once they had been skilled.
There are a number of current options for tuning “inventory” (unmodified) LLMs for particular sorts of duties. However sadly, these options had been inadequate for the sorts of functions of LLMs that Sophos X-Ops is trying to implement. For that motive, SophosAI has assembled a framework that makes use of DeepSpeed, a library developed by Microsoft that can be utilized to coach and tune the inference of a mannequin with (in principle) trillions of parameters by scaling up the compute energy and variety of graphics processing models (GPUs) used throughout coaching. The framework is open supply licensed and will be present in our GitHub repository.
Whereas lots of the elements of the framework should not novel and leverage current open-source libraries, SophosAI has synthesized a number of of the important thing elements for ease of use. And we proceed to work on bettering the efficiency of the framework.
The (insufficient) alternate options
There are a number of current approaches to adapting inventory LLMs to domain-specific information. Every of them has its personal benefits and limitations.
| Strategy | Strategies utilized | Limitations |
| Retrieval Augmented Technology |
|
|
| Continued Coaching |
|
|
| Parameter Environment friendly Nice-tuning |
|
|
To be absolutely efficient, a website skilled LLM requires pre-training of all its parameters to be taught the proprietary information of an organization. That enterprise will be useful resource intensive and time consuming—which is why we turned to DeepSpeed for our coaching framework, which we applied in Python. The model of the framework that we’re releasing as open supply will be run within the Amazon Net Companies SageMaker machine studying service, however it could possibly be tailored to different environments.
Coaching frameworks (together with DeepSpeed) will let you scale up massive mannequin coaching duties by means of parallelism. There are three most important sorts of parallelism: information, tensor, and pipeline.
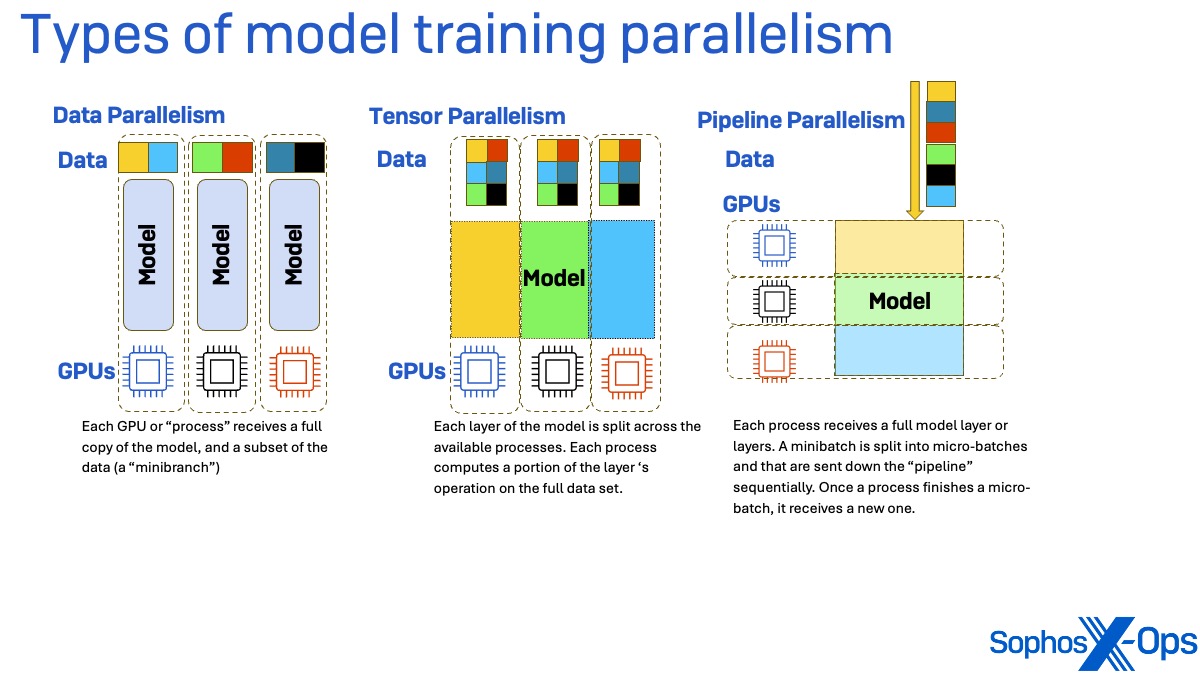
In information parallelism, every course of engaged on the coaching job (basically every graphics processor unit, or GPU) receives a replica of the total mannequin’s weights however solely a subset of the information, referred to as a minibatch. After the ahead go by means of the information (to calculate loss , or the quantity of inaccuracy within the parameters of the mannequin getting used for coaching) and the backward go (to calculate the gradient of the loss) are accomplished, the ensuing gradients are synchronized.
In Tensor parallelism, every layer of the mannequin getting used for coaching is break up throughout the out there processes. Every course of computes a portion of the layer ‘s operation utilizing the total coaching information set. The partial outputs from every of those layers are synchronized throughout processes to create a single output matrix.
Pipeline parallelism splits up the mannequin in another way. As an alternative of parallelizing by splitting layers of the mannequin, every layer of the mannequin receives its personal course of. The minibatches of information are divided into micro-batches and which might be despatched down the “pipeline” sequentially. As soon as a course of finishes a micro-batch, it receives a brand new one. This methodology might expertise “bubbles” the place a course of is idling, ready for the output of processes internet hosting earlier mannequin layers.
These three parallelism methods can be mixed in a number of methods—and are, within the DeepSpeed coaching library.
Doing it with DeepSpeed
DeepSpeed performs sharded information parallelism. Each mannequin layer is break up such that every course of will get a slice, and every course of is given a separate mini batch as enter. Through the ahead go, every course of shares its slice of the layer with the opposite processes. On the finish of this communication, every course of now has a replica of the total mannequin layer.
Every course of computes the layer output for its mini batch. After the method finishes computation for the given layer and its mini batch, the method discards the elements of the layer it was not initially holding.
The backwards go by means of the coaching information is completed in a similar way. As with information parallelism, the gradients are amassed on the finish of the backwards go and synchronized throughout processes.
Coaching processes are extra constrained of their efficiency by reminiscence than processing energy—and bringing on extra GPUs with further reminiscence to deal with a batch that’s too massive for the GPU’s personal reminiscence may cause important efficiency price due to the communication pace between GPUs, in addition to the price of utilizing extra processors than would in any other case be required to run the method. One of many key components of the DeepSpeed library is its Zero Redundancy Optimizer (ZeRO), a set of reminiscence utilization methods that may effectively parallelize very massive language mannequin coaching. ZeRO can cut back the reminiscence consumption of every GPU by partitioning the mannequin states (optimizers, gradients, and parameters) throughout parallelized information processes as a substitute of duplicating them throughout every course of.
The trick is discovering the correct mixture of coaching approaches and optimizations on your computational finances. There are three selectable ranges of partitioning in ZeRO:
- ZeRO Stage 1 shards the optimizer state throughout.
- Stage 2 shards the optimizer + the gradients.
- Stage 3 shards the optimizer + the gradients + the mannequin weights.
Every stage has its personal relative advantages. ZeRO Stage 1 might be sooner, for instance, however would require extra reminiscence than Stage 2 or 3. There are two separate inference approaches inside the DeepSpeed toolkit:
- DeepSpeed Inference: inference engine with optimizations comparable to kernel injection; this has decrease latency however requires extra reminiscence.
- ZeRO Inference: permits for offloading parameters into CPU or NVMe reminiscence throughout inference; this has larger latency however consumes much less GPU reminiscence.
Our Contributions
The Sophos AI group has put collectively a toolkit primarily based on DeepSpeed that helps take a number of the ache out of using it. Whereas the elements of the toolkit itself should not novel, what’s new is the comfort of getting a number of key elements synthesized for ease of use.
On the time of its creation, this software repository was the primary to mix coaching and each DeepSpeed inference sorts (DeepSpeed Inference and ZeRO Inference) into one configurable script. It was additionally the primary repository to create a customized container for working the most recent DeepSpeed model on Amazon Net Service’s SageMaker. And it was the primary repository to carry out distributed script primarily based DeepSpeed inference that was not run as an endpoint on SageMaker. The coaching strategies presently supported embody continued pre-training, supervised fine-tuning, and at last desire optimization.
The repository and its documentation will be discovered right here on Sophos’ GitHub.