

{kind=link}
Overview
On this information, we’ll:
- Perceive the Blueprint of any trendy advice system
- Dive into an in depth evaluation of every stage inside the blueprint
- Focus on infrastructure challenges related to every stage
- Cowl particular circumstances inside the phases of the advice system blueprint
- Get launched to some storage issues for advice methods
- And at last, finish with what the long run holds for the advice methods
Introduction
In a latest insightful discuss at Index convention, Nikhil, an skilled within the area with a decade-long journey in machine studying and infrastructure, shared his priceless experiences and insights into advice methods. From his early days at Quora to main tasks at Fb and his present enterprise at Fennel (a real-time function retailer for ML), Nikhil has traversed the evolving panorama of machine studying engineering and machine studying infrastructure particularly within the context of advice methods. This weblog put up distills his decade of expertise right into a complete learn, providing an in depth overview of the complexities and improvements at each stage of constructing a real-world recommender system.
Suggestion Programs at a excessive stage
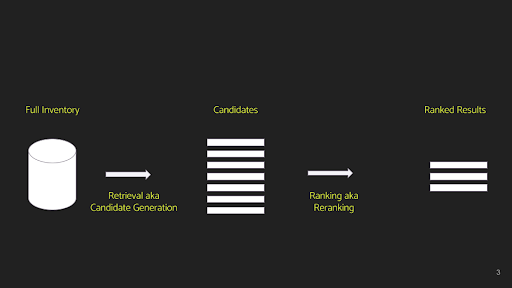
At an especially excessive stage, a typical recommender system begins easy and may be compartmentalized as follows:
Be aware: All slide content material and associated supplies are credited to Nikhil Garg from Fennel.
Stage 1: Retrieval or candidate era – The concept of this stage is that we sometimes go from thousands and thousands and even trillions (on the big-tech scale) to tons of or a few thousand candidates.
Stage 2: Rating – We rank these candidates utilizing some heuristic to select the highest 10 to 50 objects.
Be aware: The need for a candidate era step earlier than rating arises as a result of it is impractical to run a scoring perform, even a non-machine-learning one, on thousands and thousands of things.
Suggestion System – A normal blueprint
Drawing from his intensive expertise working with a wide range of advice methods in quite a few contexts, Nikhil posits that every one kinds may be broadly categorized into the above two predominant phases. In his skilled opinion, he additional delineates a recommender system into an 8-step course of, as follows:
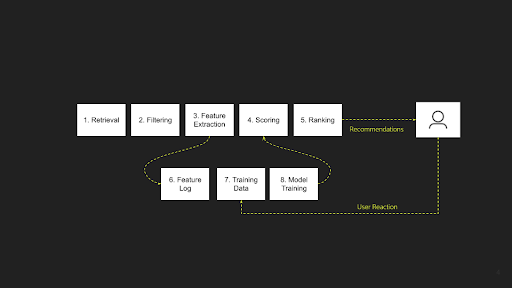
The retrieval or candidate era stage is expanded into two steps: Retrieval and Filtering. The method of rating the candidates is additional developed into three distinct steps: Characteristic Extraction, Scoring, and Rating. Moreover, there’s an offline part that underpins these phases, encompassing Characteristic Logging, Coaching Information Era, and Mannequin Coaching.
Let’s now delve into every stage, discussing them one after the other to know their features and the standard challenges related to every:
Step 1: Retrieval
Overview: The first goal of this stage is to introduce a top quality stock into the combo. The main focus is on recall — making certain that the pool features a broad vary of doubtless related objects. Whereas some non-relevant or ‘junk’ content material may additionally be included, the important thing objective is to keep away from excluding any related candidates.
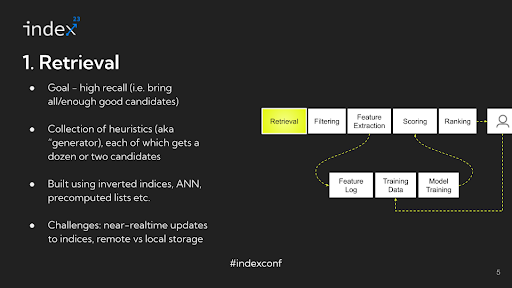
Detailed Evaluation: The important thing problem on this stage lies in narrowing down an enormous stock, doubtlessly comprising one million objects, to only a couple of thousand, all whereas making certain that recall is preserved. This job may appear daunting at first, but it surely’s surprisingly manageable, particularly in its primary type. As an illustration, think about a easy method the place you look at the content material a person has interacted with, establish the authors of that content material, after which choose the highest 5 items from every writer. This technique is an instance of a heuristic designed to generate a set of doubtless related candidates. Sometimes, a recommender system will make use of dozens of such mills, starting from simple heuristics to extra subtle ones that contain machine studying fashions. Every generator sometimes yields a small group of candidates, a couple of dozen or so, and barely exceeds a pair dozen. By aggregating these candidates and forming a union or assortment, every generator contributes a definite sort of stock or content material taste. Combining a wide range of these mills permits for capturing a various vary of content material sorts within the stock, thus addressing the problem successfully.
Infrastructure Challenges: The spine of those methods regularly entails inverted indices. For instance, you may affiliate a selected writer ID with all of the content material they’ve created. Throughout a question, this interprets into extracting content material based mostly on specific writer IDs. Trendy methods usually lengthen this method by using nearest-neighbor lookups on embeddings. Moreover, some methods make the most of pre-computed lists, akin to these generated by information pipelines that establish the highest 100 hottest content material items globally, serving as one other type of candidate generator.
For machine studying engineers and information scientists, the method entails devising and implementing varied methods to extract pertinent stock utilizing numerous heuristics or machine studying fashions. These methods are then built-in into the infrastructure layer, forming the core of the retrieval course of.
A major problem right here is making certain close to real-time updates to those indices. Take Fb for example: when an writer releases new content material, it is crucial for the brand new Content material ID to promptly seem in related person lists, and concurrently, the viewer-author mapping course of must be up to date. Though advanced, attaining these real-time updates is important for the system’s accuracy and timeliness.
Main Infrastructure Evolution: The trade has seen important infrastructural modifications over the previous decade. About ten years in the past, Fb pioneered the usage of native storage for content material indexing in Newsfeed, a observe later adopted by Quora, LinkedIn, Pinterest, and others. On this mannequin, the content material was listed on the machines chargeable for rating, and queries had been sharded accordingly.
Nonetheless, with the development of community applied sciences, there’s been a shift again to distant storage. Content material indexing and information storage are more and more dealt with by distant machines, overseen by orchestrator machines that execute calls to those storage methods. This shift, occurring over latest years, highlights a big evolution in information storage and indexing approaches. Regardless of these developments, the trade continues to face challenges, notably round real-time indexing.
Step 2: Filtering
Overview: The filtering stage in advice methods goals to sift out invalid stock from the pool of potential candidates. This course of will not be targeted on personalization however moderately on excluding objects which can be inherently unsuitable for consideration.
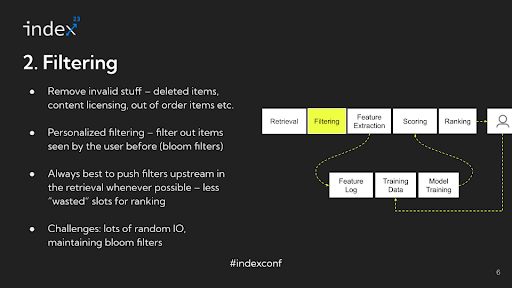
Detailed Evaluation: To higher perceive the filtering course of, think about particular examples throughout completely different platforms. In e-commerce, an out-of-stock merchandise shouldn’t be displayed. On social media platforms, any content material that has been deleted since its final indexing have to be faraway from the pool. For media streaming companies, movies missing licensing rights in sure areas needs to be excluded. Sometimes, this stage may contain making use of round 13 completely different filtering guidelines to every of the three,000 candidates, a course of that requires important I/O, usually random disk I/O, presenting a problem when it comes to environment friendly administration.
A key side of this course of is customized filtering, usually utilizing Bloom filters. For instance, on platforms like TikTok, customers usually are not proven movies they’ve already seen. This entails constantly updating Bloom filters with person interactions to filter out beforehand seen content material. As person interactions enhance, so does the complexity of managing these filters.
Infrastructure Challenges: The first infrastructure problem lies in managing the scale and effectivity of Bloom filters. They have to be stored in reminiscence for pace however can develop massive over time, posing dangers of information loss and administration difficulties. Regardless of these challenges, the filtering stage, notably after figuring out legitimate candidates and eradicating invalid ones, is usually seen as one of many extra manageable points of advice system processes.
Step 3: Characteristic extraction
After figuring out appropriate candidates and filtering out invalid stock, the subsequent important stage in a advice system is function extraction. This part entails an intensive understanding of all of the options and alerts that might be utilized for rating functions. These options and alerts are important in figuring out the prioritization and presentation of content material to the person inside the advice feed. This stage is essential in making certain that probably the most pertinent and appropriate content material is elevated in rating, thereby considerably enhancing the person’s expertise with the system.
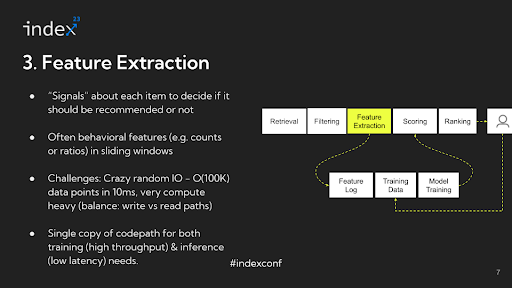
Detailed evaluation: Within the function extraction stage, the extracted options are sometimes behavioral, reflecting person interactions and preferences. A typical instance is the variety of occasions a person has seen, clicked on, or bought one thing, factoring in particular attributes such because the content material’s writer, subject, or class inside a sure timeframe.
As an illustration, a typical function may be the frequency of a person clicking on movies created by feminine publishers aged 18 to 24 over the previous 14 days. This function not solely captures the content material’s attributes, just like the age and gender of the writer, but in addition the person’s interactions inside an outlined interval. Subtle advice methods may make use of tons of and even hundreds of such options, every contributing to a extra nuanced and customized person expertise.
Infrastructure challenges: The function extraction stage is taken into account probably the most difficult from an infrastructure perspective in a advice system. The first purpose for that is the intensive information I/O (Enter/Output) operations concerned. As an illustration, suppose you have got hundreds of candidates after filtering and hundreds of options within the system. This leads to a matrix with doubtlessly thousands and thousands of information factors. Every of those information factors entails trying up pre-computed portions, akin to what number of occasions a selected occasion has occurred for a selected mixture. This course of is generally random entry, and the information factors have to be regularly up to date to replicate the most recent occasions.
For instance, if a person watches a video, the system must replace a number of counters related to that interplay. This requirement results in a storage system that should help very excessive write throughput and even greater learn throughput. Furthermore, the system is latency-bound, usually needing to course of these thousands and thousands of information factors inside tens of milliseconds..
Moreover, this stage requires important computational energy. A few of this computation happens through the information ingestion (write) path, and a few through the information retrieval (learn) path. In most advice methods, the majority of the computational sources is cut up between function extraction and mannequin serving. Mannequin inference is one other important space that consumes a substantial quantity of compute sources. This interaction of excessive information throughput and computational calls for makes the function extraction stage notably intensive in advice methods.
There are even deeper challenges related to function extraction and processing, notably associated to balancing latency and throughput necessities. Whereas the necessity for low latency is paramount through the dwell serving of suggestions, the identical code path used for function extraction should additionally deal with batch processing for coaching fashions with thousands and thousands of examples. On this situation, the issue turns into throughput-bound and fewer delicate to latency, contrasting with the real-time serving necessities.
To deal with this dichotomy, the standard method entails adapting the identical code for various functions. The code is compiled or configured in a method for batch processing, optimizing for throughput, and in one other method for real-time serving, optimizing for low latency. Reaching this twin optimization may be very difficult because of the differing necessities of those two modes of operation.
Step 4: Scoring
After getting recognized all of the alerts for all of the candidates you someway have to mix them and convert them right into a single quantity, that is known as scoring.
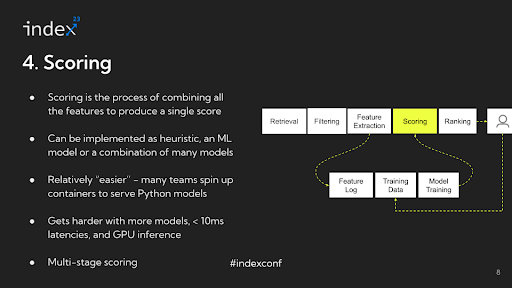
Detailed evaluation: Within the means of scoring for advice methods, the methodology can differ considerably relying on the applying. For instance, the rating for the primary merchandise may be 0.7, for the second merchandise 3.1, and for the third merchandise -0.1. The way in which scoring is carried out can vary from easy heuristics to advanced machine studying fashions.
An illustrative instance is the evolution of the feed at Quora. Initially, the Quora feed was chronologically sorted, which means the scoring was so simple as utilizing the timestamp of content material creation. On this case, no advanced steps had been wanted, and objects had been sorted in descending order based mostly on the time they had been created. Later, the Quora feed developed to make use of a ratio of upvotes to downvotes, with some modifications, as its scoring perform.
This instance highlights that scoring doesn’t all the time contain machine studying. Nonetheless, in additional mature or subtle settings, scoring usually comes from machine studying fashions, typically even a mix of a number of fashions. It is common to make use of a various set of machine studying fashions, probably half a dozen to a dozen, every contributing to the ultimate scoring in several methods. This range in scoring strategies permits for a extra nuanced and tailor-made method to rating content material in advice methods.
Infrastructure challenges: The infrastructure side of scoring in advice methods has considerably developed, turning into a lot simpler in comparison with what it was 5 to six years in the past. Beforehand a serious problem, the scoring course of has been simplified with developments in expertise and methodology. These days, a standard method is to make use of a Python-based mannequin, like XGBoost, spun up inside a container and hosted as a service behind FastAPI. This technique is simple and sufficiently efficient for many purposes.
Nonetheless, the situation turns into extra advanced when coping with a number of fashions, tighter latency necessities, or deep studying duties that require GPU inference. One other attention-grabbing side is the multi-staged nature of rating in advice methods. Completely different phases usually require completely different fashions. As an illustration, within the earlier phases of the method, the place there are extra candidates to think about, lighter fashions are sometimes used. As the method narrows right down to a smaller set of candidates, say round 200, extra computationally costly fashions are employed. Managing these various necessities and balancing the trade-offs between various kinds of fashions, particularly when it comes to computational depth and latency, turns into an important side of the advice system infrastructure.
Step 5: Rating
Following the computation of scores, the ultimate step within the advice system is what may be described as ordering or sorting the objects. Whereas sometimes called ‘rating’, this stage may be extra precisely termed ‘ordering’, because it primarily entails sorting the objects based mostly on their computed scores.
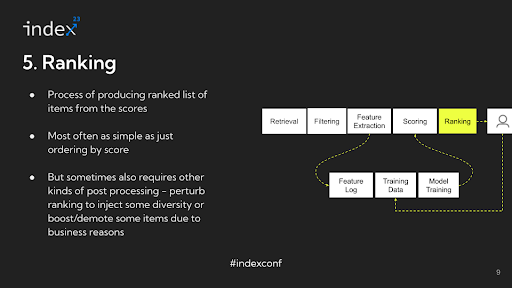
Detailed evaluation: This sorting course of is simple — sometimes simply arranging the objects in descending order of their scores. There is no further advanced processing concerned at this stage; it is merely about organizing the objects in a sequence that displays their relevance or significance as decided by their scores. In subtle advice methods, there’s extra complexity concerned past simply ordering objects based mostly on scores. For instance, suppose a person on TikTok sees movies from the identical creator one after one other. In that case, it would result in a much less pleasurable expertise, even when these movies are individually related. To deal with this, these methods usually regulate or ‘perturb’ the scores to boost points like range within the person’s feed. This perturbation is a part of a post-processing stage the place the preliminary sorting based mostly on scores is modified to take care of different fascinating qualities, like selection or freshness, within the suggestions. After this ordering and adjustment course of, the outcomes are introduced to the person.
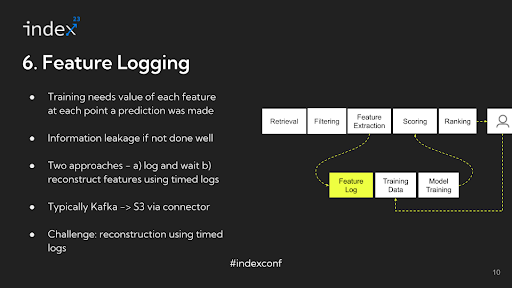
Step 6: Characteristic logging
When extracting options for coaching a mannequin in a advice system, it is essential to log the information precisely. The numbers which can be extracted throughout function extraction are sometimes logged in methods like Apache Kafka. This logging step is significant for the mannequin coaching course of that happens later.
As an illustration, in case you plan to coach your mannequin 15 days after information assortment, you want the information to replicate the state of person interactions on the time of inference, not on the time of coaching. In different phrases, in case you’re analyzing the variety of impressions a person had on a selected video, you want to know this quantity because it was when the advice was made, not as it’s 15 days later. This method ensures that the coaching information precisely represents the person’s expertise and interactions on the related second.
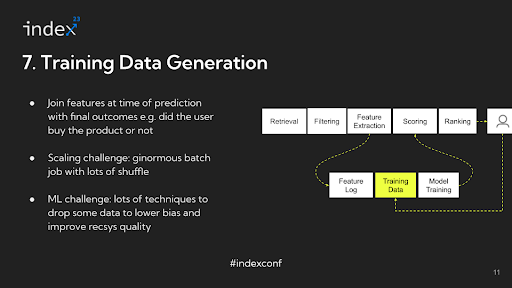
Step 7: Coaching Information
To facilitate this, a standard observe is to log all of the extracted information, freeze it in its present state, after which carry out joins on this information at a later time when making ready it for mannequin coaching. This technique permits for an correct reconstruction of the person’s interplay state on the time of every inference, offering a dependable foundation for coaching the advice mannequin.
As an illustration, Airbnb may want to think about a 12 months’s value of information as a consequence of seasonality elements, not like a platform like Fb which could take a look at a shorter window. This necessitates sustaining intensive logs, which may be difficult and decelerate function improvement. In such situations, options may be reconstructed by traversing a log of uncooked occasions on the time of coaching information era.
The method of producing coaching information entails an enormous be part of operation at scale, combining the logged options with precise person actions like clicks or views. This step may be data-intensive and requires environment friendly dealing with to handle the information shuffle concerned.
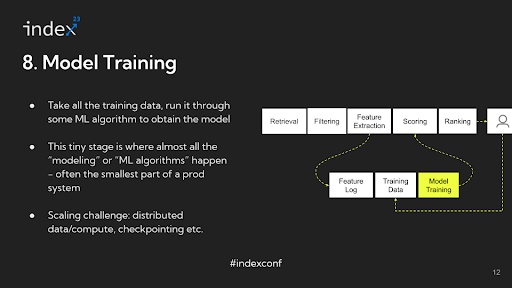
Step 8: Mannequin Coaching
Lastly, as soon as the coaching information is ready, the mannequin is skilled, and its output is then used for scoring within the advice system. Curiously, in the complete pipeline of a advice system, the precise machine studying mannequin coaching may solely represent a small portion of an ML engineer’s time, with the bulk spent on dealing with information and infrastructure-related duties.
Infrastructure challenges: For larger-scale operations the place there’s a important quantity of information, distributed coaching turns into essential. In some circumstances, the fashions are so massive – actually terabytes in measurement – that they can not match into the RAM of a single machine. This necessitates a distributed method, like utilizing a parameter server to handle completely different segments of the mannequin throughout a number of machines.
One other important side in such situations is checkpointing. Provided that coaching these massive fashions can take intensive durations, typically as much as 24 hours or extra, the chance of job failures have to be mitigated. If a job fails, it is essential to renew from the final checkpoint moderately than beginning over from scratch. Implementing efficient checkpointing methods is important to handle these dangers and guarantee environment friendly use of computational sources.
Nonetheless, these infrastructure and scaling challenges are extra related for large-scale operations like these at Fb, Pinterest, or Airbnb. In smaller-scale settings, the place the information and mannequin complexity are comparatively modest, the complete system may match on a single machine (‘single field’). In such circumstances, the infrastructure calls for are considerably much less daunting, and the complexities of distributed coaching and checkpointing could not apply.
Total, this delineation highlights the various infrastructure necessities and challenges in constructing advice methods, depending on the size and complexity of the operation. The ‘blueprint’ for setting up these methods, subsequently, must be adaptable to those differing scales and complexities.
Particular Circumstances of Suggestion System Blueprint
Within the context of advice methods, varied approaches may be taken, every becoming right into a broader blueprint however with sure phases both omitted or simplified.

Let us take a look at just a few examples for instance this:
Chronological Sorting: In a really primary advice system, the content material may be sorted chronologically. This method entails minimal complexity, as there’s primarily no retrieval or function extraction stage past utilizing the time at which the content material was created. The scoring on this case is solely the timestamp, and the sorting is predicated on this single function.
Handcrafted Options with Weighted Averages: One other method entails some retrieval and the usage of a restricted set of handcrafted options, perhaps round 10. As a substitute of utilizing a machine studying mannequin for scoring, a weighted common calculated by a hand-tuned components is used. This technique represents an early stage within the evolution of rating methods.
Sorting Based mostly on Reputation: A extra particular method focuses on the preferred content material. This might contain a single generator, probably an offline pipeline, that computes the preferred content material based mostly on metrics just like the variety of likes or upvotes. The sorting is then based mostly on these recognition metrics.
On-line Collaborative Filtering: Beforehand thought of state-of-the-art, on-line collaborative filtering entails a single generator that performs an embedding lookup on a skilled mannequin. On this case, there is no separate function extraction or scoring stage; it is all about retrieval based mostly on model-generated embeddings.
Batch Collaborative Filtering: Just like on-line collaborative filtering, batch collaborative filtering makes use of the identical method however in a batch processing context.
These examples illustrate that whatever the particular structure or method of a rating advice system, they’re all variations of a elementary blueprint. In easier methods, sure phases like function extraction and scoring could also be omitted or drastically simplified. As methods develop extra subtle, they have an inclination to include extra phases of the blueprint, finally filling out the complete template of a posh advice system.
Bonus Part: Storage issues
Though we have now accomplished our blueprint, together with the particular circumstances for it, storage issues nonetheless type an essential a part of any trendy advice system. So, it is worthwhile to pay some consideration to this bit.

In advice methods, Key-Worth (KV) shops play a pivotal position, particularly in function serving. These shops are characterised by extraordinarily excessive write throughput. As an illustration, on platforms like Fb, TikTok, or Quora, hundreds of writes can happen in response to person interactions, indicating a system with a excessive write throughput. Much more demanding is the learn throughput. For a single person request, options for doubtlessly hundreds of candidates are extracted, regardless that solely a fraction of those candidates might be proven to the person. This leads to the learn throughput being magnitudes bigger than the write throughput, usually 100 occasions extra. Reaching single-digit millisecond latency (P99) below such circumstances is a difficult job.
The writes in these methods are sometimes read-modify writes, that are extra advanced than easy appends. At smaller scales, it is possible to maintain the whole lot in RAM utilizing options like Redis or in-memory dictionaries, however this may be pricey. As scale and price enhance, information must be saved on disk. Log-Structured Merge-tree (LSM) databases are generally used for his or her capacity to maintain excessive write throughput whereas offering low-latency lookups. RocksDB, for instance, was initially utilized in Fb’s feed and is a well-liked alternative in such purposes. Fennel makes use of RocksDB for the storage and serving of function information. Rockset, a search and analytics database, additionally makes use of RocksDB as its underlying storage engine. Different LSM database variants like ScyllaDB are additionally gaining recognition.
As the quantity of information being produced continues to develop, even disk storage is turning into pricey. This has led to the adoption of S3 tiering as a must have answer for managing the sheer quantity of information in petabytes or extra. S3 tiering additionally facilitates the separation of write and browse CPUs, making certain that ingestion and compaction processes don’t burn up CPU sources wanted for serving on-line queries. As well as, methods should handle periodic backups and snapshots, and guarantee exact-once processing for stream processing, additional complicating the storage necessities. Native state administration, usually utilizing options like RocksDB, turns into more and more difficult as the size and complexity of those methods develop, presenting quite a few intriguing storage issues for these delving deeper into this house.
What does the long run maintain for the advice methods?
In discussing the way forward for advice methods, Nikhil highlights two important rising developments which can be converging to create a transformative impression on the trade.

Extraordinarily Massive Deep Studying Fashions: There is a pattern in direction of utilizing deep studying fashions which can be extremely massive, with parameter areas within the vary of terabytes. These fashions are so intensive that they can not match within the RAM of a single machine and are impractical to retailer on disk. Coaching and serving such large fashions current appreciable challenges. Handbook sharding of those fashions throughout GPU playing cards and different advanced methods are at present being explored to handle them. Though these approaches are nonetheless evolving, and the sphere is basically uncharted, libraries like PyTorch are creating instruments to help with these challenges.
Actual-Time Suggestion Programs: The trade is shifting away from batch-processed advice methods to real-time methods. This shift is pushed by the belief that real-time processing results in important enhancements in key manufacturing metrics akin to person engagement and gross merchandise worth (GMV) for e-commerce platforms. Actual-time methods usually are not solely more practical in enhancing person expertise however are additionally simpler to handle and debug in comparison with batch-processed methods. They are usually less expensive in the long term, as computations are carried out on-demand moderately than pre-computing suggestions for each person, a lot of whom could not even interact with the platform day by day.
A notable instance of the intersection of those developments is TikTok’s method, the place they’ve developed a system that mixes the usage of very massive embedding fashions with real-time processing. From the second a person watches a video, the system updates the embeddings and serves suggestions in real-time. This method exemplifies the modern instructions through which advice methods are heading, leveraging each the ability of large-scale deep studying fashions and the immediacy of real-time information processing.
These developments recommend a future the place advice methods usually are not solely extra correct and aware of person conduct but in addition extra advanced when it comes to the technological infrastructure required to help them. This intersection of enormous mannequin capabilities and real-time processing is poised to be a big space of innovation and development within the area.
Enthusiastic about exploring extra?
- Discover Fennel’s real-time function retailer for machine studying
For an in-depth understanding of how a real-time function retailer can improve machine studying capabilities, think about exploring Fennel. Fennel gives modern options tailor-made for contemporary advice methods. Go to Fennel or learn Fennel Docs.
- Discover out extra in regards to the Rockset search and analytics database
Find out how Rockset serves many advice use circumstances by its efficiency, real-time replace functionality, and vector search performance. Learn extra about Rockset or attempt Rockset at no cost.