

{kind=link}
Within the twenty years because the completion of the primary draft of the human genome, the panorama of organic analysis has undergone a revolutionary transformation. The sector of genomics has expanded exponentially, giving rise to a broader “omics” revolution, encompassing numerous knowledge varieties resembling single-cell RNA sequencing, proteomics, and metabolomics to call a number of.
These cutting-edge applied sciences are offering unprecedented insights into organic capabilities on the most granular stage, providing a deeper understanding of illness mechanisms, organism diversifications, and interactions with environmental elements, together with medicine and chemical compounds. The implications of this omics explosion are far-reaching, promising to revolutionize drug discovery, precision medication, agriculture, and biomanufacturing.
Nonetheless, the vast majority of life sciences organizations battle to totally unlock these insights, resulting from a wide range of challenges posed by the present knowledge infrastructure and applied sciences used. To beat these challenges, modernizing knowledge platforms is essential for the profitable software of multi-omics in analysis and growth.
On this weblog we discover how new applied sciences resembling Databricks Knowledge Intelligence Platform can handle these points, paving the best way for simpler and environment friendly multi-omics knowledge administration.
Most organizations battle to faucet into this knowledge resulting from legacy structure
Legacy knowledge infrastructures battle to handle the complexities of multiomics knowledge, notably in offering a scalable answer for knowledge integration and analyzing these huge datasets. Moreover, they lack native assist for superior analytics and the rising demand for AI.
Points resembling knowledge interoperability, accessibility, and reusability are widespread, exacerbated by the dearth of standardization throughout siloed omics platforms. To make this much more advanced, organizations should stability knowledge accessibility with affected person privateness and regulatory compliance in a extremely regulated setting.
Key knowledge challenges dealing with life sciences organizations
How are organizations at the moment addressing these points? At the moment, most make use of a variety of applied sciences concurrently to deal with omics knowledge. This technique, nevertheless, presents a number of challenges, together with:
Knowledge Quantity and Complexity
Omics knowledge is each huge and extremely advanced, requiring superior computational strategies for evaluation. For instance, with the rise of superior deep studying strategies for multi-omics knowledge integration, the excessive dimensionality of those datasets can introduce vital “noise,” making it troublesome to derive actionable insights. Specifically, the Excessive-Dimensional Low-Pattern-Measurement (HDLSS) drawback is difficult in omics analysis, the place the danger of overfitting in machine studying (ML) fashions can scale back the generalizability of findings. Addressing this problem requires sturdy knowledge preprocessing and superior computational methods, that many legacy knowledge infrastructures aren’t designed to deal with.
Standardization and Interoperability
The absence of widespread requirements throughout completely different omics platforms presents vital challenges in guaranteeing knowledge interoperability and reusability. With out standardized protocols, integrating numerous datasets right into a cohesive framework turns into an arduous job.
Regulatory Concerns
Making certain that omics knowledge are accessible whereas sustaining affected person privateness and adhering to laws resembling HIPAA and GDPR is a posh balancing act. This problem is heightened in a worldwide analysis setting the place knowledge is commonly shared throughout completely different jurisdictions. As well as, as extra genetics knowledge are being utilized in diagnostic settings or for coaching machine studying fashions for predicting illness threat (resembling polygenic threat scoring), the flexibility to trace all facets of the coaching course of—from knowledge acquisition and high quality management to mannequin coaching and explainability—has grow to be more and more vital.
Consumer Expertise
The pharmaceutical business advantages from entry to a various vary of execs, together with IT specialists, knowledge scientists, medical researchers, and bench scientists conducting advanced experiments on numerous organic samples. Most present knowledge platforms, constructed on completely different applied sciences—spanning Excessive-Efficiency Computing (HPC), conventional knowledge warehouses and completely different native cloud companies—require vital technical upkeep to adapt to the quickly evolving panorama of omics knowledge.
Furthermore, entry to insights by non-technical staff members with area data is hindered as a result of complexity of those programs and the steep studying curve related to their use. This problem creates a major barrier to efficient collaboration and data-driven decision-making inside life sciences organizations.
Rise of GenAI Functions
Coaching new basis fashions utilizing multi-omics knowledge is revolutionizing biomedical analysis and drug discovery. For instance, with the rise of single-cell omics knowledge, fashions like scGPT and Geneformer leverage large-scale multi-omics datasets to foretell drug responses and establish new therapeutic targets, driving developments in personalised medication. Firms resembling EvolutionaryScale and Profulent.bio have skilled giant language fashions (LLMs) for producing new artificial proteins based mostly on multiomics knowledge. Nonetheless, operationalizing these fashions presents vital challenges, notably by way of coaching effectivity and cost-effectiveness. The computational calls for of processing huge datasets require superior infrastructure, that may deal with each knowledge administration and cost-effective coaching of such giant fashions on huge quantities of multi-modal knowledge.
Introducing the Databricks Knowledge Intelligence Platform for Omics
The Databricks Knowledge Intelligence Platform presents a robust basis for a multi-omics knowledge platform, successfully addressing the complexities that researchers and IT professionals encounter when managing omics knowledge. Here is how Databricks may help overcome every of the important thing challenges:

Knowledge Quantity and Complexity
Databricks is constructed on a scalable cloud infrastructure that may deal with the huge and sophisticated datasets typical of omics analysis. With its integration with Apache Spark and a high-performance compute engine powered by Photon, Databricks permits cost-effective distributed knowledge processing. Moreover, by having the ML/AI stack constructed on prime of a robust knowledge administration infrastructure, it reduces the friction of managing separate tech stacks for knowledge administration and superior analytics whereas accelerating time to worth.
The Databricks Photon engine supplies a major enhance to Spark-based genomic pipelines and instruments resembling Venture Glow, accelerating and simplifying the evaluation of enormous genomic datasets, notably for genetic goal identification through Genome-Large Affiliation Research (GWAS).
Standardization and Interoperability
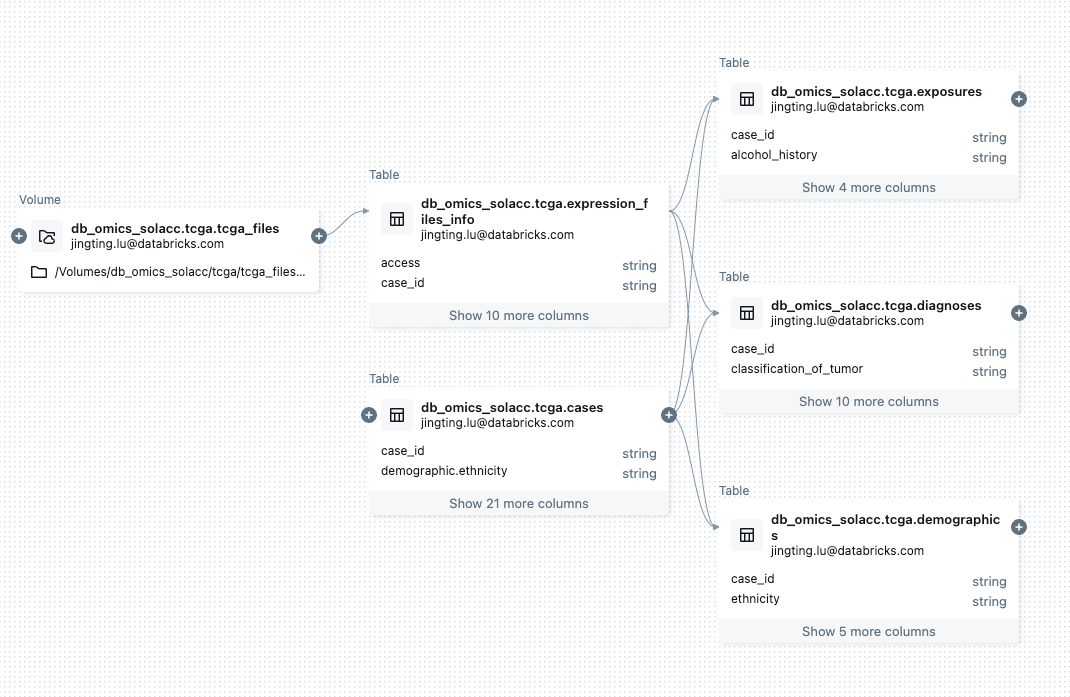
The Databricks lakehouse structure permits seamless interoperability by integrating unstructured, semi-structured, and structured knowledge from knowledge lakes and knowledge warehouses right into a single, unified platform based mostly on open-source applied sciences resembling Delta Lake and Unity Catalog. This method facilitates the mixing of numerous datasets, supporting open knowledge codecs and interfaces to cut back vendor lock-in and simplify knowledge integration throughout completely different programs.
By leveraging open-source applied sciences and offering a centralized knowledge catalog, Unity Catalog, Databricks ensures that knowledge is well discoverable, accessible, and could be built-in with exterior programs in a compliant and auditable method. This permits researchers to ship on the FAIR rules (Findability, Accessibility, Interoperability, and Reusability) for scientific knowledge administration, selling collaboration, reproducibility, and data-driven insights.
Regulatory Concerns
Databricks Unity Catalog permits organizations to satisfy stringent regulatory necessities, resembling HIPAA and GDPR, whereas enhancing knowledge findability and accessibility. With its centralized metadata repository and highly effective semantic search capabilities, customers can rapidly find related knowledge belongings based mostly on context and which means. The platform’s fine-grained entry controls, id federation, and complete audit logging guarantee knowledge safety and compliance.
Moreover, Unity Catalog supplies superior metadata administration, tagging, and knowledge lineage monitoring to reinforce the discoverability and reproducibility of experiments. To additional guarantee regulatory compliance, Databricks presents sturdy knowledge encryption and secret administration options. The platform additionally integrates open-source applied sciences, such because the Delta Sharing Protocol, which permits safe knowledge sharing between events. Databricks Clear Rooms facilitates safe collaboration amongst researchers from completely different organizations whereas assembly knowledge residency necessities.
These capabilities collectively allow organizations to uphold strict knowledge safety requirements whereas permitting licensed customers to effectively uncover, entry, and share essential knowledge for evaluation and analysis in a safe, compliant setting—even throughout organizational boundaries.
Consumer Expertise
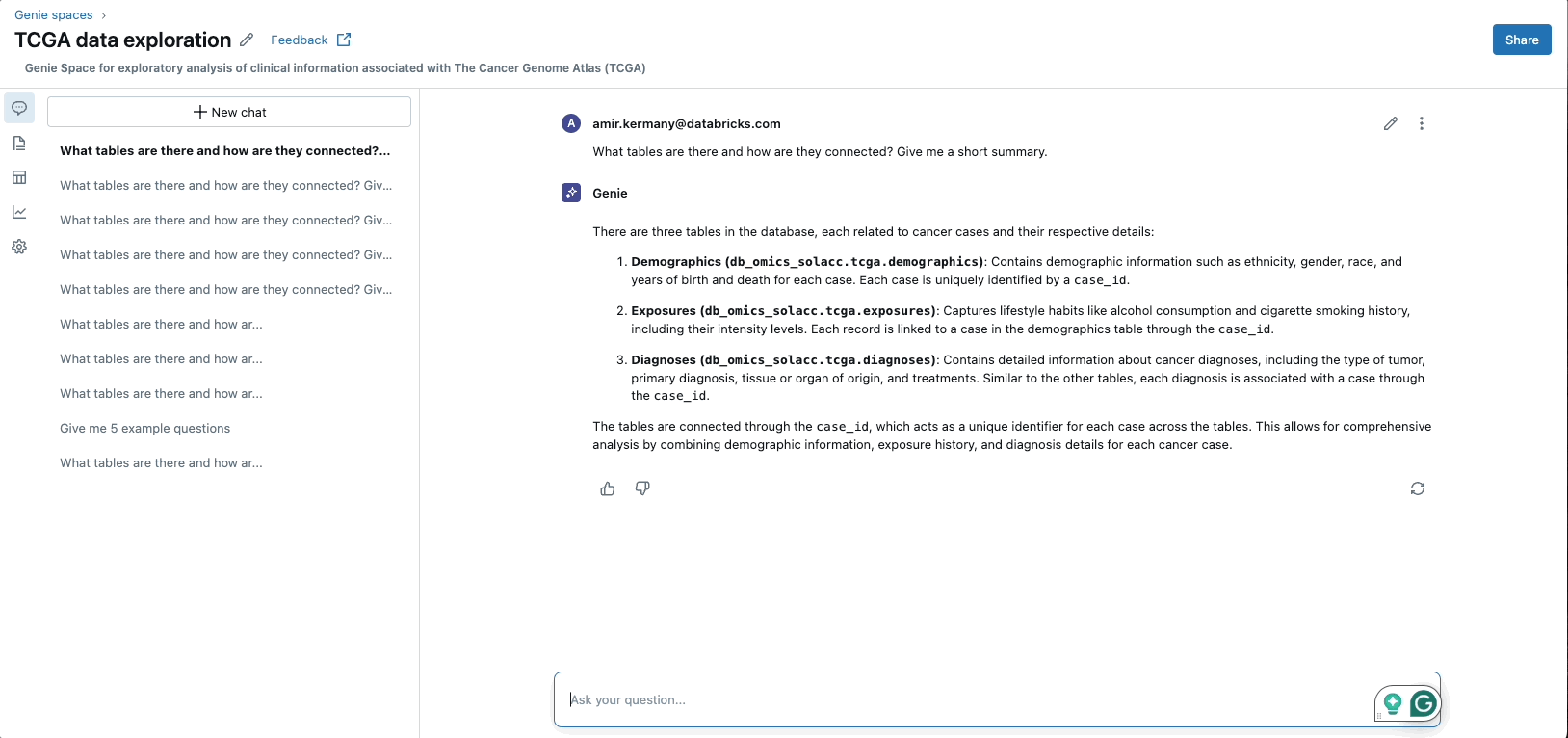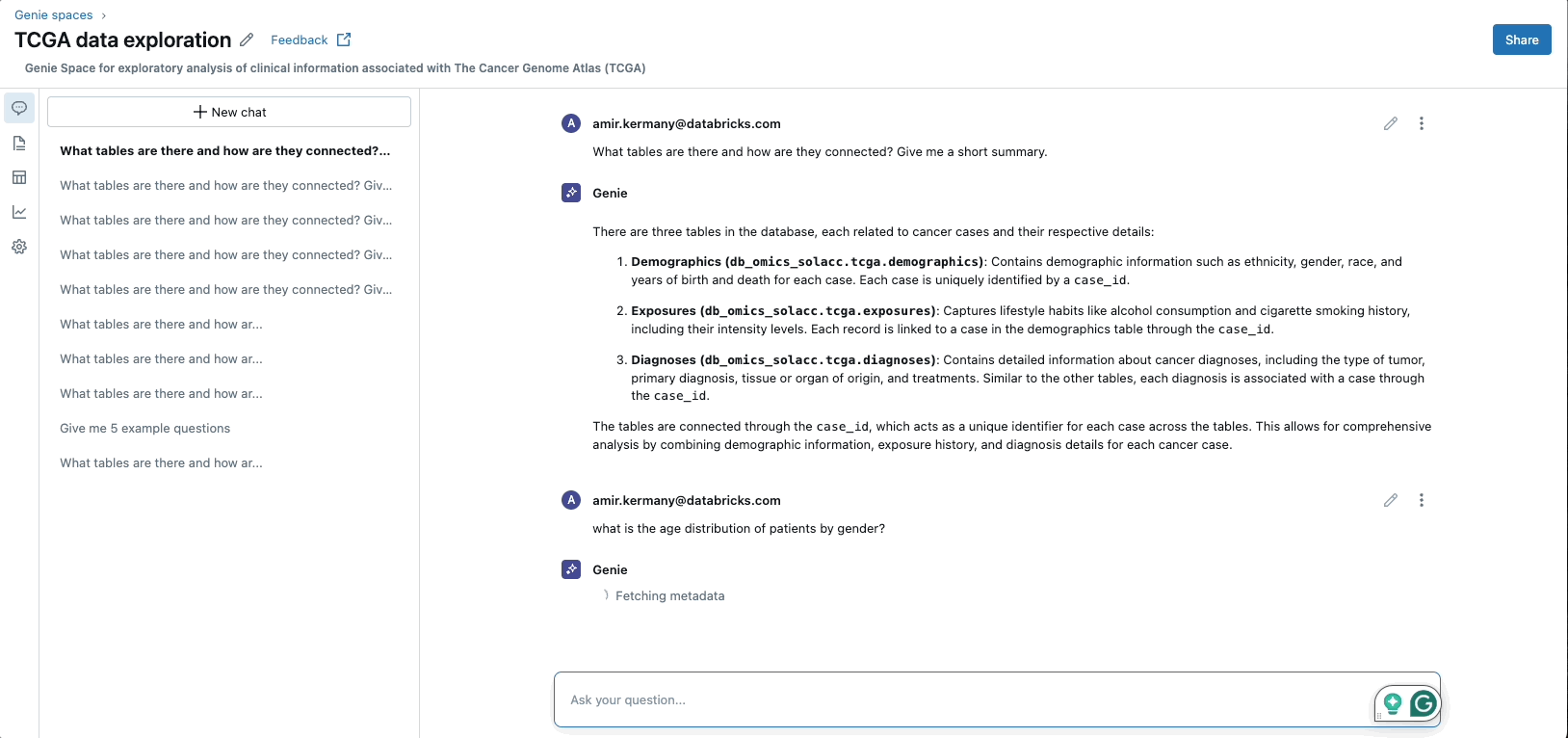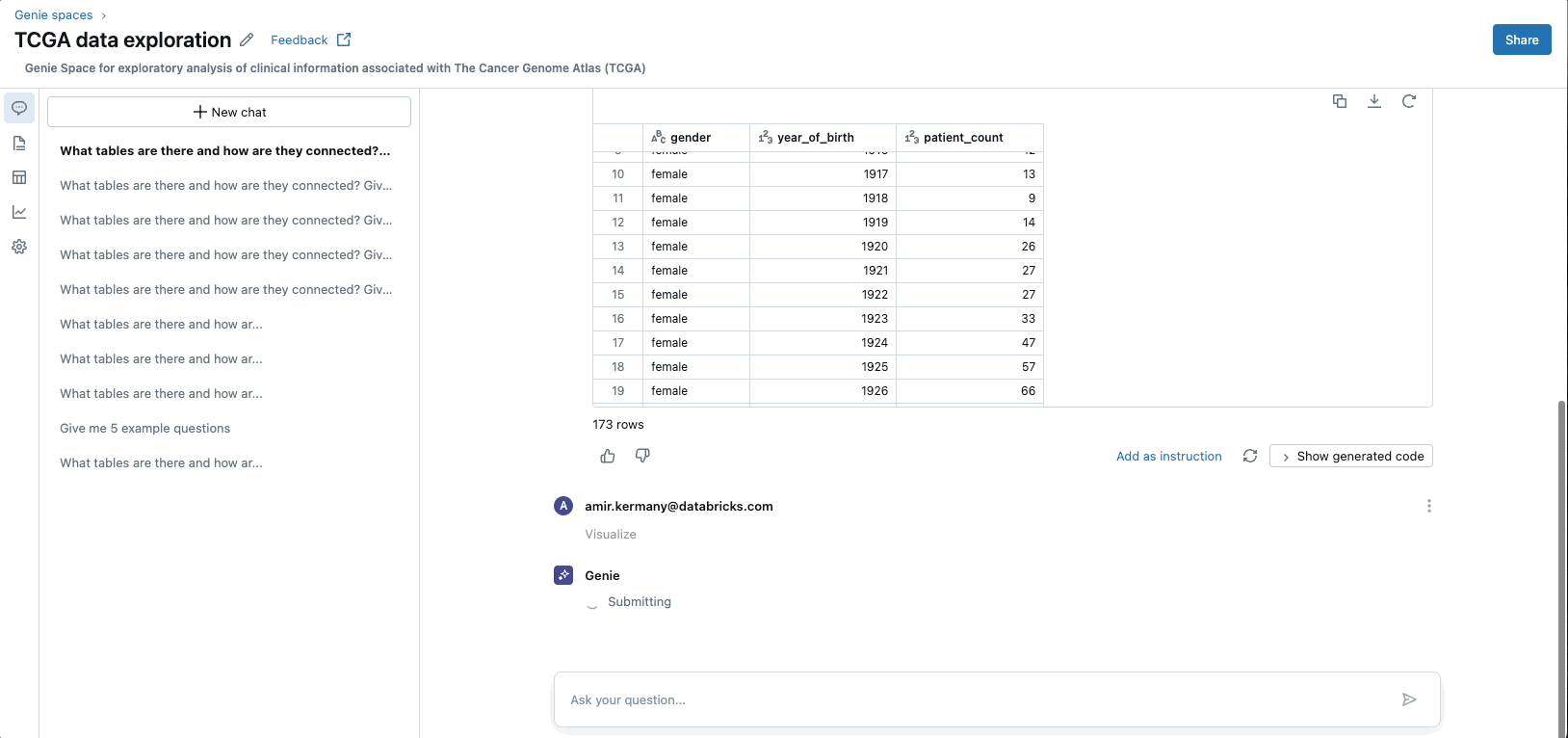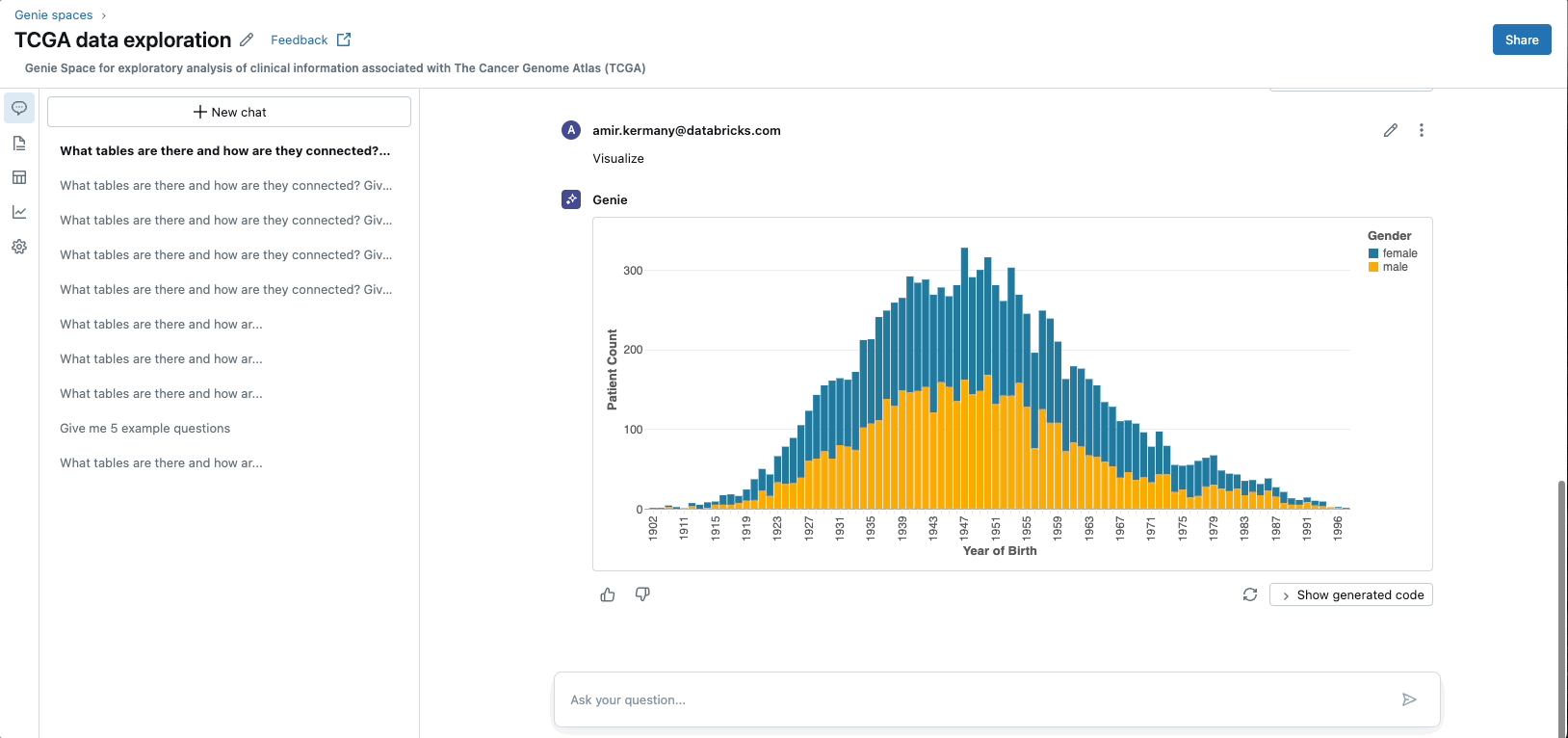
Databricks presents a complete, self-service knowledge platform that simplifies infrastructure administration and integrates numerous knowledge varieties. Its user-friendly interfaces, that includes pure language querying and context-aware AI-powered help, allow simple knowledge entry and evaluation. This method demystifies knowledge interactions, making the platform accessible not solely to technical customers but in addition to area specialists and not using a technical background.
By simplifying knowledge entry and lowering IT overhead whereas enhancing collaboration amongst completely different groups, Databricks accelerates decision-making and innovation in drug discovery and growth.
Rise of GenAI Functions
Databricks’ MosaicAI platform permits the pre-training, fine-tuning, and deployment of generative AI fashions by offering a scalable and safe computational infrastructure. With MosaicAI, Databricks presents options particularly designed for cost-effective coaching of basis fashions on a corporation’s proprietary datasets. Moreover, MosaicAI presents extremely scalable vector search and an AI Agent Framework for constructing compound AI programs, together with LLMOps/MLOps capabilities for managing your entire lifecycle of AI fashions.
This ensures that they’re operationalized successfully, effectively, and at scale, permitting organizations to unlock the total potential of generative AI and drive enterprise worth from their AI investments.
Wanting forward
Within the upcoming technical blogs, we’ll discover the usage of Databricks applied sciences for multi-omics. This may embrace working Genome-Large Affiliation Research and pre-training the Geneformer basis mannequin with MosaicAI.
In abstract, Databricks presents a complete platform that addresses the varied challenges of managing omics knowledge. With its scalable infrastructure, assist for interoperability, robust safety features, and superior AI capabilities, Databricks permits pharmaceutical corporations to extract sensible insights from advanced omics datasets. By using Databricks, organizations can expedite their analysis and growth (R&D) efforts, resulting in innovation and improved affected person outcomes.
Be taught extra about our knowledge and AI options for healthcare and life sciences.