

{kind=link}
Over the previous six months the engineering staff at Rockset has totally built-in similarity indexes into its search and analytics database.
Indexing has at all times been on the forefront of Rockset’s expertise. Rockset constructed a Converged Index which incorporates parts of a search index, columnar retailer, row retailer and now a similarity index that may scale to billions of vectors and terabytes of information. We’ve architected these indexes to help real-time updates in order that streaming knowledge will be made out there for search in lower than 200 milliseconds.
Earlier this yr, Rockset launched a brand new cloud structure with compute-storage and compute-compute separation. In consequence, indexing of newly ingested vectors and metadata doesn’t negatively impression search efficiency. Customers can constantly stream and index vectors totally remoted from search. This structure is advantageous for streaming knowledge and likewise similarity indexing as these are resource-intensive operations.
What we’ve additionally seen is that vector search just isn’t on an island of its personal. Many functions apply filters to vector search utilizing textual content, geo, time sequence knowledge and extra. Rockset makes hybrid search as straightforward as a SQL WHERE clause. Rockset has exploited the facility of the search index with an built-in SQL engine so your queries are at all times executed effectively.
On this weblog, we’ll dig into how Rockset has totally built-in vector search into its search and analytics database. We’ll describe how Rockset has architected its answer for native SQL, real-time updates and compute-compute separation.
Watch the tech speak on How We Constructed Vector Search within the Cloud with Chief Architect Tudor Bosman and engineer Daniel Latta-Lin. Hear how they constructed a distributed similarity index utilizing FAISS-IVF that’s memory-efficient and helps fast insertion and recall.
FAISS-IVF at Rockset
Whereas Rockset is algorithm agnostic in its implementation of similarity indexing, for the preliminary implementation we leveraged FAISS-IVF because it’s broadly used, effectively documented and helps updates.
There are a number of strategies to indexing vectors together with constructing a graph, tree knowledge construction and inverted file construction. Tree and graph constructions take an extended time to construct, making them computationally costly and time consuming to help use circumstances with ceaselessly updating vectors. The inverted file method is effectively favored due to its quick indexing time and search efficiency.
Whereas the FAISS library is open sourced and will be leveraged as a standalone index, customers want a database to handle and scale vector search. That’s the place Rockset is available in as a result of it has solved database challenges together with question optimization, multi-tenancy, sharding, consistency and extra that customers want when scaling vector search functions.
Implementation of FAISS-IVF at Rockset
As Rockset is designed for scale, it builds a distributed FAISS similarity index that’s memory-efficient and helps fast insertion and recall.
Utilizing a DDL command, a consumer creates a similarity index on any vector area in a Rockset assortment. Underneath the hood, the inverted file indexing algorithm partitions the vector area into Voronoi cells and assigns every partition a centroid, or the purpose which falls within the heart of the partition. Vectors are then assigned to a partition, or cell, based mostly on which centroid they’re closest to.
CREATE SIMILARITY INDEX vg_ann_index
ON FIELD confluent_webinar.video_game_embeddings:embedding
DIMENSION 1536 as 'faiss::IVF256,Flat';
An instance of the DDL command used to create a similarity index in Rockset.
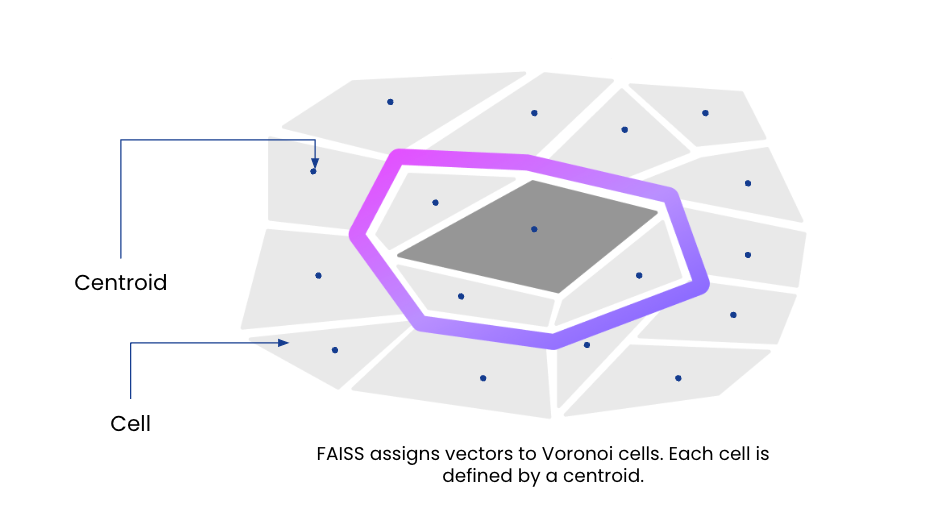
On the time of similarity index creation, Rockset builds a posting listing of the centroids and their identifiers that’s saved in reminiscence. Every file within the assortment can be listed and extra fields are added to every file to retailer the closest centroid and the residual, the offset or distance from the closest centroid. The gathering is saved on SSDs for efficiency and cloud object storage for sturdiness, providing higher value efficiency than in-memory vector database options. As new information are added, their nearest centroids and residuals are computed and saved.
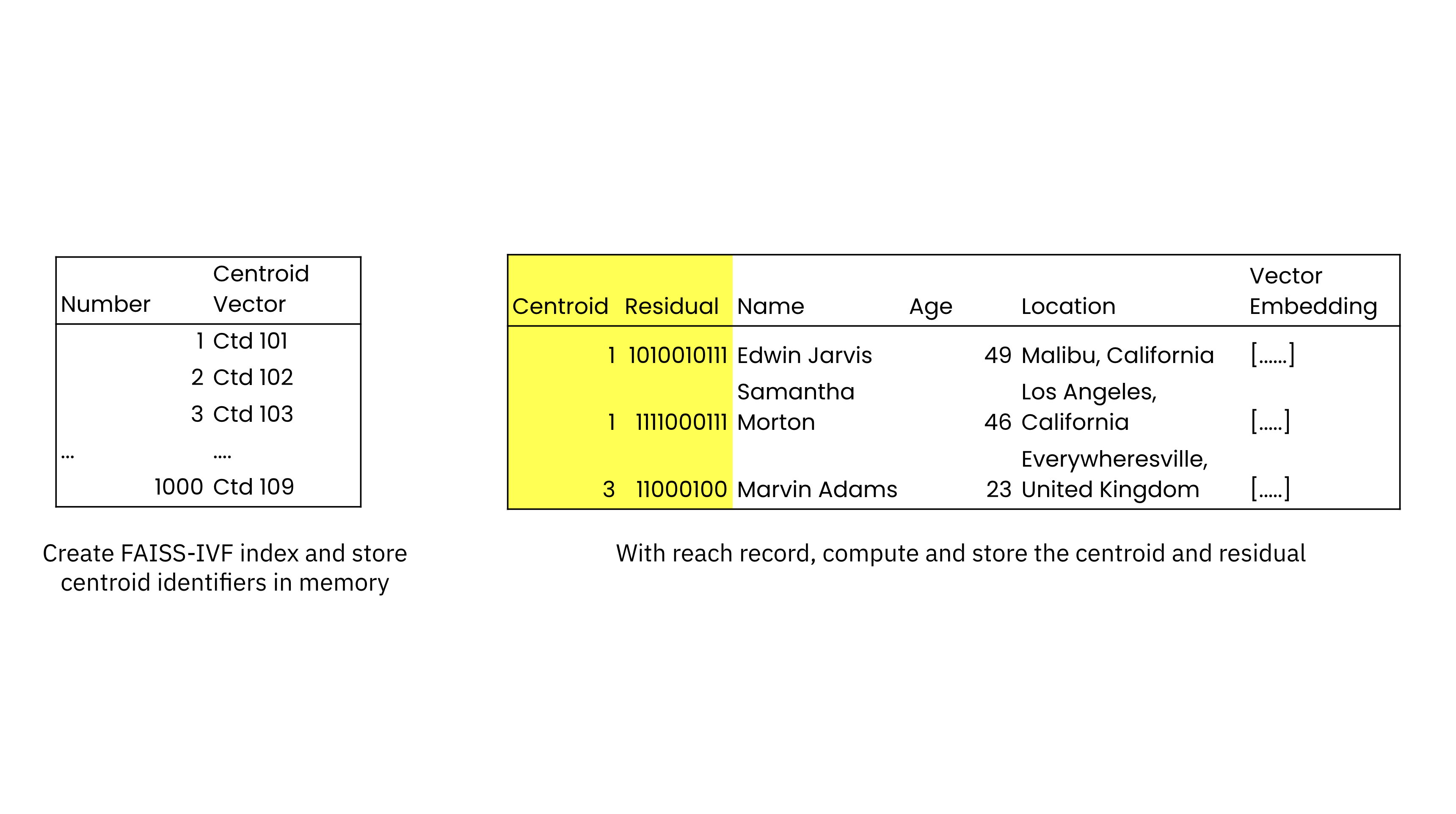
With Rockset’s Converged Index, vector search can leverage each the similarity and search index in parallel. When working a search, Rockset’s question optimizer will get the closest centroids to the goal embedding from FAISS. Rockset’s question optimizer then searches throughout the centroids utilizing the search index to return the consequence.

Rockset additionally offers flexibility to the consumer to commerce off between recall and pace for his or her AI utility. At similarity index creation time, the consumer can decide the variety of centroids, with extra centroids resulting in quicker search but in addition elevated indexing time. At question time, the consumer can even choose the variety of probes, or the variety of cells to go looking, buying and selling off between pace and accuracy of search.
Rockset’s implementation minimizes the quantity of information saved in reminiscence, limiting it to a posting listing, and leverages the similarity index and search index for efficiency.
Construct apps with real-time updates
One of many recognized arduous challenges with vector search is dealing with inserts, updates and deletions. That’s as a result of vector indexes are fastidiously organized for quick lookups and any try and replace them with new vectors will quickly deteriorate the quick lookup properties.
Rockset helps streaming updates to metadata and vectors in an environment friendly manner. Rockset is constructed on RocksDB, an open-source embedded storage engine which is designed for mutability and was constructed by the staff behind Rockset at Meta.
Utilizing RocksDB beneath the hood permits Rockset to help field-level mutations, so an replace to the vector on a person file will set off a question to FAISS to generate the brand new centroid and residual. Rockset will then replace solely the values of the centroid and the residual for an up to date vector area. This ensures that new or up to date vectors are queryable inside ~200 milliseconds.

Separation of indexing and search
Rockset’s compute-compute separation ensures that the continual streaming and indexing of vectors won’t have an effect on search efficiency. In Rockset’s structure, a digital occasion, cluster of compute nodes, can be utilized to ingest and index knowledge whereas different digital cases can be utilized for querying. A number of digital cases can concurrently entry the identical dataset, eliminating the necessity for a number of replicas of information.
Compute-compute separation makes it potential for Rockset to help concurrent indexing and search. In many different vector databases, you can’t carry out reads and writes in parallel so you might be compelled to batch load knowledge throughout off-hours to make sure the constant search efficiency of your utility.
Compute-compute separation additionally ensures that when similarity indexes have to be periodically retrained to maintain the recall excessive that there isn’t any interference with search efficiency. It’s well-known that periodically retraining the index will be computationally costly. In lots of programs, together with in Elasticsearch, the reindexing and search operations occur on the identical cluster. This introduces the potential for indexing to negatively intrude with the search efficiency of the applying.
With compute-compute separation, Rockset avoids the difficulty of indexing impacting seek for predictable efficiency at any scale.

Hybrid search as straightforward as a SQL WHERE clause
Many vector databases supply restricted help for hybrid search or metadata filtering and prohibit the forms of fields, updates to metadata and the scale of metadata. Being constructed for search and analytics, Rockset treats metadata as a first-class citizen and helps paperwork as much as 40MB in dimension.
The explanation that many new vector databases restrict metadata is that filtering knowledge extremely rapidly is a really arduous drawback. If you got the question, “Give me 5 nearest neighbors the place <filter>?” you would wish to have the ability to weigh the completely different filters, their selectivity after which reorder, plan and optimize the search. It is a very arduous drawback however one which search and analytics databases, like Rockset, have spent plenty of time, years even, fixing with a cost-based optimizer.
As a consumer, you possibly can sign to Rockset that you’re open to an approximate nearest neighbor search and buying and selling off some precision for pace within the search question utilizing approx_dot_product or approx_euclidean_dist.
WITH dune_embedding AS (
SELECT embedding
FROM commons.book_catalogue_embeddings catalogue
WHERE title="Dune"
LIMIT 1
)
SELECT title, writer, score, num_ratings, value,
APPROX_DOT_PRODUCT(dune_embedding.embedding, book_catalogue_embeddings.embedding) similarity,
description, language, book_format, page_count, liked_percent
FROM commons.book_catalogue_embeddings CROSS JOIN dune_embedding
WHERE score IS NOT NULL
AND book_catalogue_embeddings.embedding IS NOT NULL
AND writer != 'Frank Herbert'
AND score > 4.0
ORDER BY similarity DESC
LIMIT 30
A question with approx_dot_product which is an approximate measure of how intently two vectors align.
Rockset makes use of the search index for filtering by metadata and limiting the search to the closest centroids. This method is known as single-stage filtering and contrasts with two-step filtering together with pre-filtering and post-filtering that may induce latency.
Scale vector search within the cloud
At Rockset, we’ve spent years constructing a search and analytics database for scale. It’s been designed from the bottom up for the cloud with useful resource isolation that’s essential when constructing real-time functions or functions that run 24×7. On buyer workloads, Rockset has scaled to 20,000 QPS whereas sustaining a P50 knowledge latency of 10 milliseconds.
In consequence, we see corporations already utilizing vector seek for at-scale, manufacturing functions. JetBlue, the information chief within the airways trade, makes use of Rockset as its vector search database for making operational selections round flights, crew and passengers utilizing LLM-based chatbots. Whatnot, the quickest rising market within the US, makes use of Rockset for powering AI-recommendations on its stay public sale platform.
If you’re constructing an AI utility, we invite you to begin a free trial of Rockset or study extra about our expertise on your use case in a product demo.
Watch the tech speak on How We Constructed Vector Search within the Cloud with Chief Architect Tudor Bosman and engineer Daniel Latta-Lin. Hear how they constructed a distributed similarity index utilizing FAISS-IVF that’s memory-efficient and helps fast insertion and recall.