

{kind=link}
Introduction
Retrieval-augmented technology (RAG) has revolutionized how enterprises harness their unstructured information base utilizing Giant Language Fashions (LLMs), and its potential has far-reaching impacts. Intercontinental Trade (ICE) is a worldwide monetary group working exchanges, clearing homes, information providers, and mortgage expertise, together with the most important inventory trade group on the planet, the New York Inventory Trade (NYSE). ICE is breaking new floor by pioneering a seamless resolution for pure language seek for structured information merchandise by having a structured RAG pipeline with out the necessity for any information motion from the pre-existing utility. This resolution eliminates the necessity for finish customers to grasp information fashions, schemas, or SQL queries.
The ICE crew collaborated with Databricks engineers to leverage the complete stack of Databricks Mosaic AI merchandise (Unity Catalog, Vector Search, Basis Mannequin APIs, and Mannequin Serving) and implement an end-to-end RAG lifecycle with strong analysis. The crew tailored the widely known Spider analysis benchmark for state-of-the-art text-to-SQL functions to swimsuit their enterprise use case. By evaluating syntax match and execution match metrics between floor reality queries and LLM-generated queries, ICE is ready to establish incorrect queries for few-shot studying, thereby refining the standard of their SQL question outputs.
For the aim of confidentiality, artificial information is referenced within the code snippets proven all through this weblog submit.
Large-Image Workflow

The crew leveraged Vector Seek for indexing desk metadata to allow fast retrieval of related tables and columns. Basis Mannequin APIs gave ICE entry to a set of enormous language fashions (LLMs), facilitating seamless experimentation with numerous fashions throughout improvement.
Inference Tables, a part of the Mosaic AI Gateway, have been used to trace all incoming queries and outgoing responses. To compute analysis metrics, the crew in contrast LLM-generated responses with floor reality SQL queries. Incorrect LLM-generated queries have been then streamed into a question pattern desk, offering useful information for few-shot studying.
This closed-loop strategy allows steady enchancment of the text-to-SQL system, permitting for refinement and adaptation to evolving SQL queries. This technique is designed to be extremely configurable, with part settings simply adjustable by way of a YAML file. This modularity ensures the system stays adaptable and future-proof, able to combine with best-in-breed options for every part.
Learn on for extra particulars on how ICE and Databricks collaborated to construct this text-to-SQL system.
Establishing RAG
To generate correct SQL queries from pure language inputs, we used few-shot studying in our immediate. We additional augmented the enter query with related context (desk DDLs, pattern information, pattern queries), utilizing two specialised retrievers: ConfigRetriever and VectorSearchRetriever.
ConfigRetriever reads context from a YAML configuration file, permitting customers to rapidly experiment with totally different desk definitions and pattern queries with out the necessity to create tables and vector indexes in Unity Catalog. This retriever offers a versatile and light-weight technique to check and refine the text-to-SQL system. Right here is an instance of the YAML configuration file:
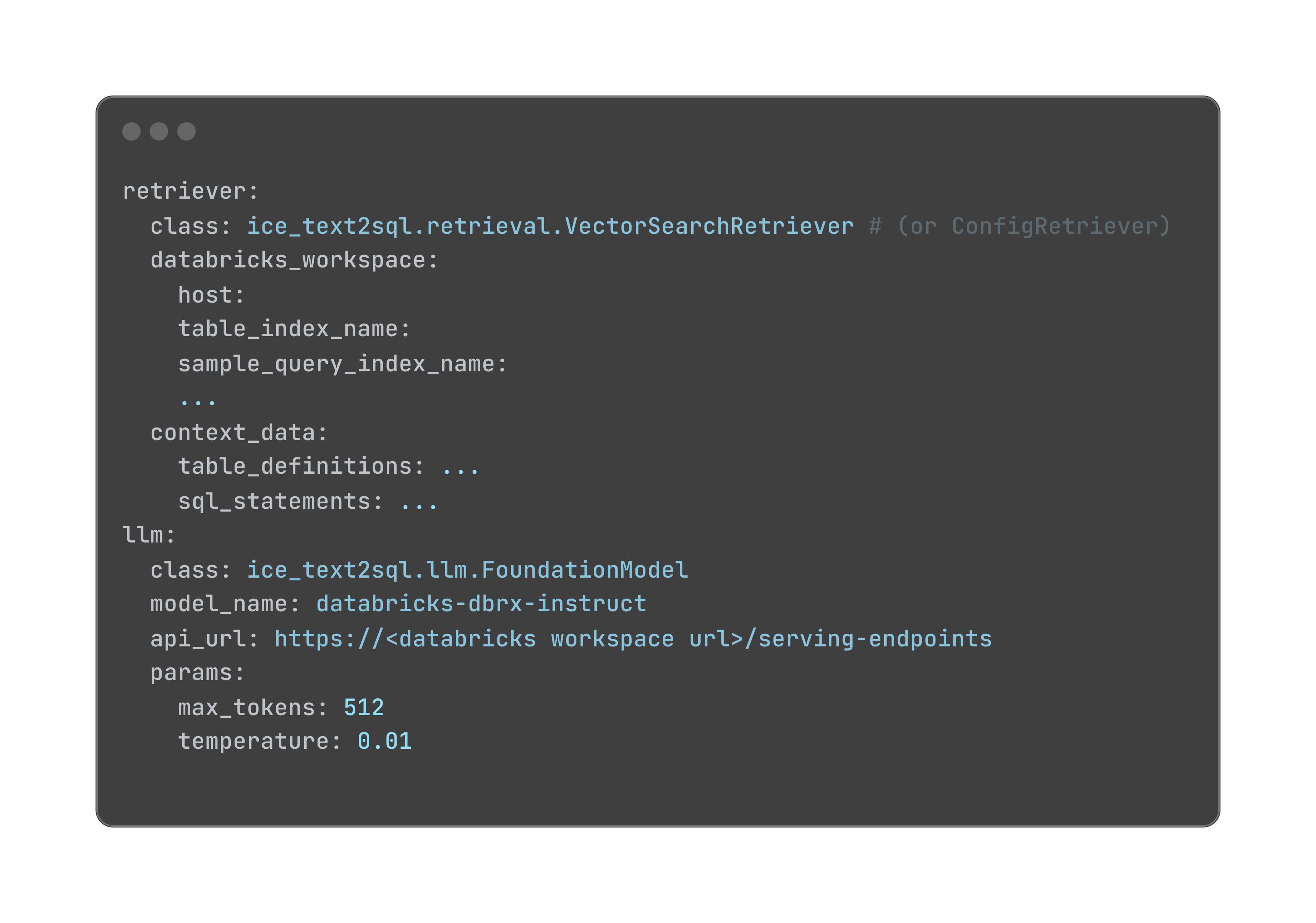
VectorSearchRetriever reads context from two metadata tables: table_definitions and sample_queries. These tables retailer detailed details about the database schema and pattern queries, that are listed utilizing Vector Search to allow environment friendly retrieval of related context. By leveraging the VectorSearchRetriever, the text-to-SQL system can faucet right into a wealthy supply of contextual data to tell its question technology.
Metadata Tables
We created two metadata tables to retailer details about the tables and queries:
table_definitions: Thetable_definitionsdesk shops metadata concerning the tables within the database, together with column names, column sorts, column descriptions/feedback and desk descriptions.Desk feedback/descriptions might be outlined in a delta desk utilizing
COMMENT ON TABLE. Particular person column remark/description might be outlined utilizingALTER TABLE {table_name} ALTER COLUMN {column} COMMENT ”{remark}”. Desk DDLs might be extracted from a delta desk utilizing theSHOW CREATE TABLEcommand. These table- and column-level descriptions are tracked and versioned utilizing GitHub.The
table_definitionsdesk is listed by the desk Information Definition Language (DDL) by way of Vector Search, enabling environment friendly retrieval of related desk metadata.sample_queries: Thesample_queriesdesk shops pairs of questions and corresponding SQL queries, which function a place to begin for the text-to-SQL system. This desk is initialized with a set of predefined question-SQL pairs.At runtime, the questions and LLM-generated SQL statements are logged within the Inference Desk. To enhance response accuracy, customers can present floor reality SQLs which shall be utilized to guage the LLM-generated SQLs. Incorrect queries shall be ingested into the
sample_queriesdesk. The bottom reality for these incorrect queries might be utilized as context for associated upcoming queries.
Mosaic AI Vector Search
To allow environment friendly retrieval of related context, we listed each metadata tables utilizing Vector Search to retrieve essentially the most related tables primarily based on queries by way of similarity search.
Context Retrieval
When a query is submitted, an embedding vector is created and matched towards the vector indexes of the table_definitions and sample_queries tables. This retrieves the next context:
- Associated desk DDLs: We retrieve the desk DDLs with column descriptions (feedback) for the tables related to the enter query.
- Pattern information: We learn a number of pattern information rows for every associated desk from Unity Catalog to offer concrete examples of the info.
- Instance question-SQL pairs: We extract a number of instance question-SQL pairs from the sample_queries desk which can be related to the enter query.
Immediate Augmentation
The retrieved context is used to enhance the enter query, making a immediate that gives the LLM with a wealthy understanding of the related tables, information, and queries. The immediate contains:
- The enter query
- Associated desk DDLs with column descriptions
- Pattern information for every associated desk
- Instance question-SQL pairs
Right here is an instance of a immediate augmented with retrieved context:

The augmented immediate is shipped to an LLM of alternative, e.g., Llama3.1-70B, by way of the Basis Mannequin APIs. The LLM generates a response primarily based on the context supplied, from which we utilized regex to extract the SQL assertion.
Analysis
We tailored the favored Spider benchmark to comprehensively assess the efficiency of our text-to-SQL system. SQL statements might be written in numerous syntactically appropriate kinds whereas producing equivalent outcomes. To account for this flexibility, we employed two complementary analysis approaches:
- Syntactic matching: Compares the construction and syntax of generated SQL statements with floor reality queries.
- Execution matching: Assesses whether or not the generated SQL statements, when executed, produce the identical outcomes as the bottom reality queries.
To make sure compatibility with the Spider analysis framework, we preprocessed the generated LLM responses to standardize their codecs and buildings. This step includes modifying the SQL statements to adapt to the anticipated enter format of the analysis framework, for instance:

After producing the preliminary response, we utilized a post-processing perform to extract the SQL assertion from the generated textual content. This crucial step isolates the SQL question from any surrounding textual content or metadata, enabling correct analysis and comparability with the bottom reality SQL statements.
This streamlined analysis with processing strategy affords two vital benefits:
- It facilitates analysis on a large-scale dataset and allows on-line analysis straight from the inference desk.
- It eliminates the necessity to contain LLMs as judges, which usually depend on arbitrarily human-defined grading rubrics to assign scores to generated responses.
By automating these processes, we guarantee constant, goal, and scalable analysis of our text-to-SQL system’s efficiency, paving the best way for steady enchancment and refinement. We’ll present further particulars on our analysis course of afterward on this weblog submit.
Syntactic Matching
We evaluated the syntactic correctness of our generated SQL queries by computing the F1 rating to evaluate part matching and accuracy rating for precise matching. Extra particulars are beneath:
- Element Matching: This metric evaluates the accuracy of particular person SQL parts, akin to SELECT, WHERE, and GROUP BY. The prediction is taken into account appropriate if the set of parts matches precisely with the supplied floor reality statements.
- Actual Matching: This measures whether or not the whole predicted SQL question matches the gold question. A prediction is appropriate provided that all parts are appropriate, whatever the order. This additionally ensures that SELECT col2, col2 is evaluated the identical as SELECT col2, col1.
For this analysis, we now have 48 queries with floor reality SQL statements. Spider implements SQL Hardness Standards, which categorizes queries into 4 ranges of problem: simple, medium, laborious, and further laborious. There have been 0 simple, 36 medium, 7 laborious, and 5 additional laborious queries. This categorization helps analyze mannequin efficiency throughout totally different ranges of question problem.
Preprocessing for Syntactic Matching
Previous to computing syntactic matching metrics, we made certain that the desk schemas conformed to the Spider’s format. In Spider, desk names, column names and column sorts are all outlined in particular person lists and they’re linked collectively by indexes. Right here is an instance of desk definitions:

Every column identify is a tuple of the desk it belongs to and column identify. The desk is represented as an integer which is the index of that desk within the table_names record. The column sorts are in the identical order because the column names.
One other caveat is that the desk alias must be outlined with the as key phrase. Column alias within the choose clause shouldn’t be supported and is eliminated earlier than analysis. SQL statements from each floor reality and prediction are preprocessed in response to the particular necessities earlier than operating the analysis.
Execution Matching
Along with syntactic matching, we applied execution matching to guage the accuracy of our generated SQL queries. We executed each the bottom reality SQL queries and the LLM-generated SQL queries on the identical dataset and in contrast the end result dataframes utilizing the next metrics:
- Row rely: The variety of rows returned by every question.
- Content material: The precise information values returned by every question.
- Column sorts: The info forms of the columns returned by every question.
In abstract, this dual-pronged analysis technique of involving each syntactic and execution matches allowed us to robustly and deterministically assess our text-to-SQL system’s efficiency. By analyzing each the syntactic accuracy and the purposeful equivalence of generated queries, we gained complete insights into our system’s capabilities. This strategy not solely supplied a extra nuanced understanding of the system’s strengths but in addition helped us pinpoint particular areas for enchancment, driving steady refinement of our text-to-SQL resolution.
Steady Enchancment
To successfully monitor our text-to-SQL system’s efficiency, we leveraged the Inference Desk characteristic inside Mannequin Serving. Inference Desk constantly ingests serving request inputs (user-submitted questions) and responses (LLM-generated solutions) from Mosaic AI Mannequin Serving endpoints. By consolidating all questions and responses right into a single Inference Desk, we simplified monitoring and diagnostics processes. This centralized strategy allows us to detect tendencies and patterns in LLM habits. With the extracted generated SQL queries from the inference desk, we evaluate them towards the bottom reality SQL statements to guage mannequin efficiency.
To create ground-truth SQLs, we extracted consumer questions from the inference desk, downloaded the desk as a .csv file, after which imported them into an open-source labeling device referred to as Label Studio. Material specialists can add ground-truth SQL statements on the Studio, and the info is imported again as an enter desk to Databricks and merged with the inference desk utilizing the desk key databricks_requests_id.
We then evaluated the predictions towards the bottom reality SQL statements utilizing the syntactic and execution matching strategies mentioned above. Incorrect queries might be detected and logged into the sample_queries desk. This course of permits for a steady loop that identifies the wrong SQL queries after which makes use of these queries for few-shot studying, enabling the mannequin to study from its errors and enhance its efficiency over time. This closed-loop strategy ensures that the mannequin is constantly studying and adapting to altering consumer wants and question patterns.
Mannequin Serving
We selected to implement this text-to-SQL utility as a Python library, designed to be totally modular and configurable. Configurable parts like retrievers, LLM names, inference parameters, and so forth., might be loaded dynamically primarily based on a YAML configuration file for straightforward customization and extension of the applying. A fundamental ConfigRetriever might be utilized for fast testing primarily based on hard-coded context within the YAML configuration. For production-level deployment, VectorSearchRetriever is used to dynamically retrieve desk DDLs, pattern queries and information from Databricks Lakehouse.
We deployed this utility as a Python .whl file and uploaded it to a Unity Catalog Quantity so it may be logged with the mannequin as a dependency. We are able to then seamlessly serve this mannequin utilizing Mannequin Serving endpoints. To invoke a question from an MLflow mannequin, use the next code snippet:

Impression and Conclusion
In simply 5 weeks, the Databricks and ICE crew was capable of develop a sturdy text-to-SQL system that solutions non-technical enterprise customers’ questions with exceptional accuracy: 77% syntactic accuracy and 96% execution matches throughout ~50 queries. This achievement underscores two necessary insights:
- Offering descriptive metadata for tables and columns is very necessary
- Making ready an analysis set of question-response pairs and SQL statements is crucial in guiding the iterative improvement course of.
The Databricks Information Intelligence Platform’s complete capabilities, together with information storage and governance (Unity Catalog), state-of-the-art LLM querying (Basis Mannequin APIs), and seamless utility deployment (Mannequin Serving), eradicated the technical complexities usually related to integrating various device stacks. This streamlined strategy enabled us to ship a high-caliber utility in a number of week’s time.
Finally, the Databricks Platform has empowered ICE to speed up the journey from uncooked monetary information to actionable insights, revolutionizing their data-driven decision-making processes.
This weblog submit was written in collaboration with the NYSE/ICE AI Heart of Excellence crew led by Anand Pradhan, together with Suresh Koppisetti (Director of AI and Machine Studying Expertise), Meenakshi Venkatasubramanian (Lead Information Scientist) and Lavanya Mallapragada (Information Scientist).