

{kind=link}
Finetuning Embedding Fashions for Higher Retrieval and RAG
TL;DR: Finetuning an embedding mannequin on in-domain knowledge can considerably enhance vector search and retrieval-augmented era (RAG) accuracy. With Databricks, it’s straightforward to finetune, deploy, and consider embedding fashions to optimize retrieval to your particular use case—leveraging artificial knowledge with out handbook labeling.
Why It Issues: In case your vector search or RAG system isn’t retrieving one of the best outcomes, finetuning an embedding mannequin is an easy but highly effective option to enhance efficiency. Whether or not you’re coping with monetary paperwork, information bases, or inner code documentation, finetuning can provide you extra related search outcomes and higher downstream LLM responses.
What We Discovered: We finetuned and examined two embedding fashions on three enterprise datasets and noticed main enhancements in retrieval metrics (Recall@10) and downstream RAG efficiency. This implies finetuning could be a game-changer for accuracy with out requiring handbook labeling, leveraging solely your present knowledge.
Need to attempt embedding finetuning? We offer a reference resolution that can assist you get began. Databricks makes vector search, RAG, reranking, and embedding finetuning straightforward. Attain out to your Databricks Account Govt or Options Architect for extra info.
Why Finetune Embeddings?
Embedding fashions energy fashionable vector search and RAG techniques. An embedding mannequin transforms textual content into vectors, making it potential to seek out related content material primarily based on which means reasonably than simply key phrases. Nonetheless, off-the-shelf fashions aren’t at all times optimized to your particular area—that’s the place finetuning is available in.
Finetuning an embedding mannequin on domain-specific knowledge helps in a number of methods:
- Enhance retrieval accuracy: Customized embeddings enhance search outcomes by aligning along with your knowledge.
- Improve RAG efficiency: Higher retrieval reduces hallucinations and allows extra grounded generative AI responses.
- Enhance price and latency: A smaller finetuned mannequin can generally outperform bigger, costly options.
On this weblog submit, we present that finetuning an embedding mannequin is an efficient approach to enhance retrieval and RAG efficiency for task-specific, enterprise use circumstances.
Outcomes: Finetuning Works
We finetuned two embedding fashions (gte-large-en-v1.5 and e5-mistral-7b-instruct) on artificial knowledge and evaluated them on three datasets from our Area Intelligence Benchmark Suite (DIBS) (FinanceBench, ManufactQA, and Databricks DocsQA). We then in contrast them towards OpenAI’s text-embedding-3-large.
Key Takeaways:
- Finetuning improved retrieval accuracy throughout datasets, typically considerably outperforming baseline fashions.
- Finetuned embeddings carried out in addition to or higher than reranking in lots of circumstances, exhibiting they could be a robust standalone resolution.
- Higher retrieval led to higher RAG efficiency on FinanceBench, demonstrating end-to-end advantages.
Retrieval Efficiency
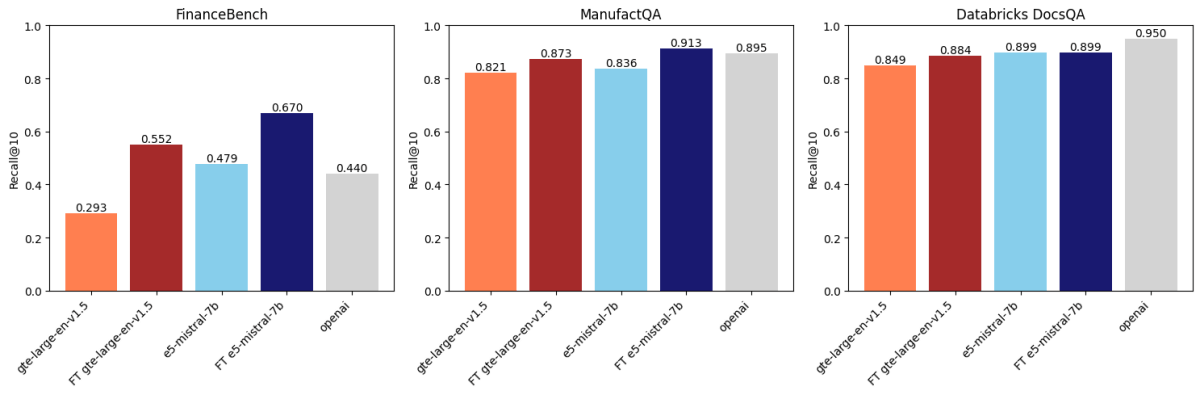
After evaluating throughout three datasets, we discovered that embedding finetuning improves accuracy on two of those datasets. Determine 1 exhibits that for FinanceBench and ManufactQA, finetuned embeddings outperformed their base variations, generally even beating OpenAI’s API mannequin (gentle gray). For Databricks DocsQA, nonetheless, OpenAI text-embedding-3-large accuracy surpasses all finetuned fashions. It’s potential that it is because the mannequin has been skilled on public Databricks documentation. This exhibits that whereas finetuning might be efficient, it strongly will depend on the coaching dataset and the analysis job.
Finetuning vs. Reranking
We then in contrast the above outcomes with API-based reranking utilizing voyageai/rerank-1 (Determine 2). A reranker usually takes the highest ok outcomes retrieved by an embedding mannequin, reranks these outcomes by relevance to the search question, after which returns the reranked prime ok (in our case ok=30 adopted by ok=10). This works as a result of rerankers are often bigger, extra highly effective fashions than embedding fashions and likewise mannequin the interplay between the question and the doc in a approach that’s extra expressive.
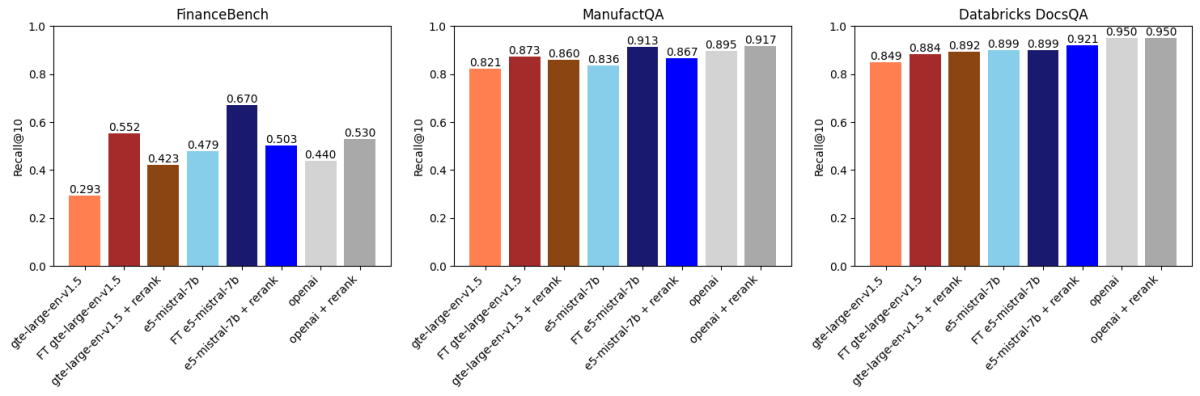
What we discovered was:
- Finetuning gte-large-en-v1.5 outperformed reranking on FinanceBench and ManufactQA.
- OpenAI’s text-embedding-3-large benefited from reranking, however the enhancements have been marginal on some datasets.
- For Databricks DocsQA, reranking had a smaller affect, however finetuning nonetheless introduced enhancements, exhibiting the dataset-dependent nature of those strategies.
Rerankers often incur further per-query inference latency and price relative to embedding fashions. Nonetheless, they can be utilized with present vector databases and might in some circumstances be less expensive than re-embedding knowledge with a more recent embedding mannequin. The selection of whether or not to make use of a reranker will depend on your area and your latency/price necessities.
Finetuning Helps RAG Efficiency
For FinanceBench, higher retrieval translated on to higher RAG accuracy when mixed with GPT-4o (see Appendix). Nonetheless, in domains the place retrieval was already robust, corresponding to Databricks DocsQA, finetuning didn’t add a lot—highlighting that finetuning works greatest when retrieval is a transparent bottleneck.
How We Finetuned and Evaluated Embedding Fashions
Listed below are among the extra technical particulars of our artificial knowledge era, finetuning, and analysis.
Embedding Fashions
We finetuned two open-source embedding fashions:
- gte-large-en-v1.5 is a well-liked embedding mannequin primarily based on BERT Massive (434M parameters, 1.75 GB). We selected to run experiments on this mannequin due to its modest dimension and open licensing. This embedding mannequin can also be at present supported on the Databricks Basis Mannequin API.
- e5-mistral-7b-instruct belongs to a more recent class of embedding fashions constructed on prime of robust LLMs (on this case Mistral-7b-instruct-v0.1). Though e5-mistral-7b-instruct is healthier on the usual embedding benchmarks corresponding to MTEB and is ready to deal with longer and extra nuanced prompts, it’s a lot bigger than gte-large-en-v1.5 (because it has 7 billion parameters) and is barely slower and costlier to serve.
We then in contrast them towards OpenAI’s text-embedding-3-large.
Analysis Datasets
We evaluated all fashions on the next datasets from our Area Intelligence Benchmark Suite (DIBS): FinanceBench, ManufactQA, and Databricks DocsQA.
| Dataset | Description | # Queries | # Corpus |
|---|---|---|---|
| FinanceBench | Questions on SEC 10-Ok paperwork generated by human specialists. Retrieval is finished over particular person pages from a superset of 360 SEC 10-Ok filings. | 150 | 53,399 |
| ManufactQA | Questions and solutions sampled from public boards of an digital gadgets producer. | 6,787 | 6,787 |
| Databricks DocsQA | Questions primarily based on publicly obtainable Databricks documentation generated by Databricks specialists. | 139 | 7,561 |
We report recall@10 as our fundamental retrieval metric; this measures whether or not the right doc is within the prime 10 retrieved paperwork.
The golden customary for embedding mannequin high quality is the MTEB benchmark, which includes retrieval duties corresponding to BEIR in addition to many different non-retrieval duties. Whereas fashions corresponding to gte-large-en-v1.5 and e5-mistral-7b-instruct do nicely on MTEB, we have been curious to see how they carried out on our inner enterprise duties.
Coaching Knowledge
We skilled separate fashions on artificial knowledge tailor-made for every of the benchmarks above:
| Coaching Set | Description | # Distinctive Samples |
| Artificial FinanceBench | Queries generated from 2,400 SEC 10-Ok paperwork | ~6,000 |
| Artificial Databricks Docs QA | Queries generated from public Databricks documentation. | 8,727 |
| ManufactQA | Queries generated from electronics manufacturing PDFs | 14,220 |
With a purpose to generate the coaching set for every area, we took present paperwork and generated pattern queries grounded within the content material of every doc utilizing LLMs corresponding to Llama 3 405B. The artificial queries have been then filtered for high quality by an LLM-as-a-judge (GPT4o). The filtered queries and their related paperwork have been then used as contrastive pairs for finetuning. We used in-batch negatives for contrastive coaching, however including arduous negatives might additional enhance efficiency (see Appendix).
Hyperparameter Tuning
We ran sweeps throughout:
- Studying fee, batch dimension, softmax temperature
- Epoch depend (1-3 epochs examined)
- Question immediate variations (e.g., “Question:” vs. instruction-based prompts)
- Pooling technique (imply pooling vs. final token pooling)
All finetuning was achieved utilizing the open supply mosaicml/composer, mosaicml/llm-foundry, and mosaicml/streaming libraries on the Databricks platform.
The right way to Enhance Vector Search and RAG on Databricks
Finetuning is just one method for enhancing vector search and RAG efficiency; we checklist a couple of further approaches beneath.
For Higher Retrieval:
- Use a greater embedding mannequin: Many customers unknowingly work with outdated embeddings. Merely swapping in a higher-performing mannequin can yield quick features. Examine the MTEB leaderboard for prime fashions.
- Strive hybrid search: Mix dense embeddings with keyword-based seek for improved accuracy. Databricks Vector Search makes this straightforward with a one-click resolution.
- Use a reranker: A reranker can refine outcomes by reordering them primarily based on relevance. Databricks supplies this as a built-in characteristic (at present in Personal Preview). Attain out to your Account Govt to attempt it.
For Higher RAG:
Get Began with Finetuning on Databricks
Finetuning embeddings might be an straightforward win for enhancing retrieval and RAG in your AI techniques. On Databricks, you’ll be able to:
- Finetune and serve embedding fashions on scalable infrastructure.
- Use built-in instruments for vector search, reranking, and RAG.
- Rapidly check totally different fashions to seek out what works greatest to your use case.
Able to attempt it? We’ve constructed a reference resolution to make fine-tuning simpler—attain out to your Databricks Account Govt or Options Architect to get entry.
Appendix
|
|
|
|
|
||||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Desk 1: Comparability of gte-large-en-v1.5, e5-mistral-7b-instruct and text-embedding-3-large. Identical knowledge as Determine 1.
Producing Artificial Coaching Knowledge
For all datasets, the queries within the coaching set weren’t the identical because the queries within the check set. Nonetheless, within the case of Databricks DocsQA (however not FinanceBench or ManufactQA), the paperwork used to generate artificial queries have been the identical paperwork used within the analysis set. The main target of our examine is to enhance retrieval on specific duties and domains (versus a zero-shot, generalizable embedding mannequin); we subsequently see this as a legitimate method for sure manufacturing use circumstances. For FinanceBench and ManufactQA, the paperwork used to generate artificial knowledge didn’t overlap with the corpus used for analysis.
There are numerous methods to pick out unfavorable passages for contrastive coaching. They will both be chosen randomly, or they are often pre-defined. Within the first case, the unfavorable passages are chosen from throughout the coaching batch; these are sometimes called “in-batch negatives” or “gentle negatives”. Within the second case, the person preselects textual content examples which might be semantically tough, i.e. they’re doubtlessly associated to the question however barely incorrect or irrelevant. This second case is typically known as “arduous negatives”. On this work, we merely used in-batch negatives; the literature signifies that utilizing arduous negatives would doubtless result in even higher outcomes.
Finetuning Particulars
For all finetuning experiments, most sequence size is about to 2048. We then evaluated all checkpoints. For all benchmarking, corpus paperwork have been truncated to 2048 tokens (not chunked), which was an inexpensive constraint for our specific datasets. We select the strongest baselines on every benchmark after sweeping over question prompts and pooling technique.
Bettering RAG Efficiency
A RAG system consists of each a retriever and a generative mannequin. The retriever selects a set of paperwork related to a selected question, after which feeds them to the generative mannequin. We chosen one of the best finetuned gte-large-en-v1.5 fashions and used them for the primary retrieval stage of a easy RAG system (following the final method described in Lengthy Context RAG Efficiency of LLMs and The Lengthy Context RAG Capabilities of OpenAI o1 and Google Gemini). Specifically, we retrieved ok=10 paperwork every with a most size of 512 tokens and used GPT4o because the generative LLM. Ultimate accuracy was evaluated utilizing an LLM-as-a-judge (GPT4o).
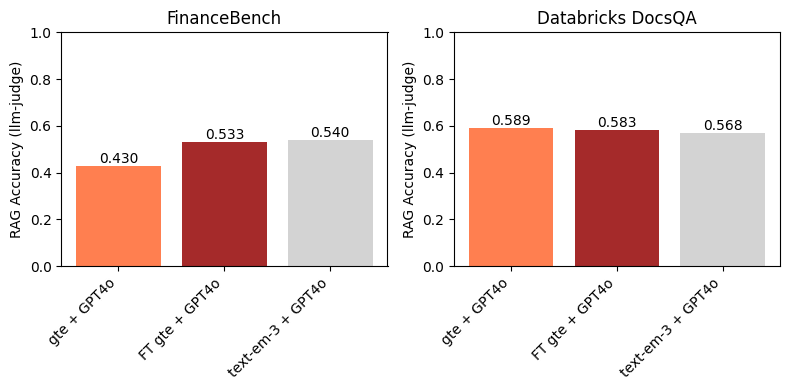
On FinanceBench, Determine 3 exhibits that utilizing a finetuned embedding mannequin results in an enchancment in downstream RAG accuracy. Moreover, it’s aggressive with text-embedding-3-large. That is anticipated, since finetuning gte led to a big enchancment in Recall@10 over baseline gte (Determine 1). This instance highlights the efficacy of embedding mannequin finetuning on specific domains and datasets.
On the Databricks DocsQA dataset, we don’t discover any enhancements when utilizing the finetuned gte mannequin above baseline gte. That is considerably anticipated, because the margins between the baseline and finetuned fashions in Figures 1 and a pair of are small. Apparently, though text-embedding-3-large has (barely) increased Recall@10 than any of the gte fashions, it doesn’t result in increased downstream RAG accuracy. As proven in Determine 1, all of the embedding fashions had comparatively excessive Recall@10 on the Databricks DocsQA dataset; this means that retrieval is probably going not the bottleneck for RAG, and that finetuning an embedding mannequin on this dataset is just not essentially probably the most fruitful method.
We want to thank Quinn Leng and Matei Zaharia for suggestions on this blogpost.