

{kind=link}
Introduction
Indexes are an important a part of correct knowledge modeling for all databases, and DynamoDB is not any exception. DynamoDB’s secondary indexes are a strong instrument for enabling new entry patterns in your knowledge.
On this publish, we’ll take a look at DynamoDB secondary indexes. First, we’ll begin with some conceptual factors about how to consider DynamoDB and the issues that secondary indexes resolve. Then, we’ll take a look at some sensible suggestions for utilizing secondary indexes successfully. Lastly, we’ll shut with some ideas on when you need to use secondary indexes and when you need to search for different options.
Let’s get began.
What’s DynamoDB, and what are DynamoDB secondary indexes?
Earlier than we get into use circumstances and greatest practices for secondary indexes, we must always first perceive what DynamoDB secondary indexes are. And to do this, we must always perceive a bit about how DynamoDB works.
This assumes some fundamental understanding of DynamoDB. We’ll cowl the essential factors it’s essential know to grasp secondary indexes, however when you’re new to DynamoDB, you could wish to begin with a extra fundamental introduction.
The Naked Minimal you Must Find out about DynamoDB
DynamoDB is a singular database. It is designed for OLTP workloads, that means it is nice for dealing with a excessive quantity of small operations — consider issues like including an merchandise to a buying cart, liking a video, or including a touch upon Reddit. In that approach, it might probably deal with related functions as different databases you may need used, like MySQL, PostgreSQL, MongoDB, or Cassandra.
DynamoDB’s key promise is its assure of constant efficiency at any scale. Whether or not your desk has 1 megabyte of information or 1 petabyte of information, DynamoDB desires to have the identical latency in your OLTP-like requests. This can be a massive deal — many databases will see diminished efficiency as you enhance the quantity of information or the variety of concurrent requests. Nevertheless, offering these ensures requires some tradeoffs, and DynamoDB has some distinctive traits that it’s essential perceive to make use of it successfully.
First, DynamoDB horizontally scales your databases by spreading your knowledge throughout a number of partitions beneath the hood. These partitions will not be seen to you as a consumer, however they’re on the core of how DynamoDB works. You’ll specify a main key in your desk (both a single ingredient, referred to as a ‘partition key’, or a mixture of a partition key and a kind key), and DynamoDB will use that main key to find out which partition your knowledge lives on. Any request you make will undergo a request router that can decide which partition ought to deal with the request. These partitions are small — typically 10GB or much less — to allow them to be moved, break up, replicated, and in any other case managed independently.
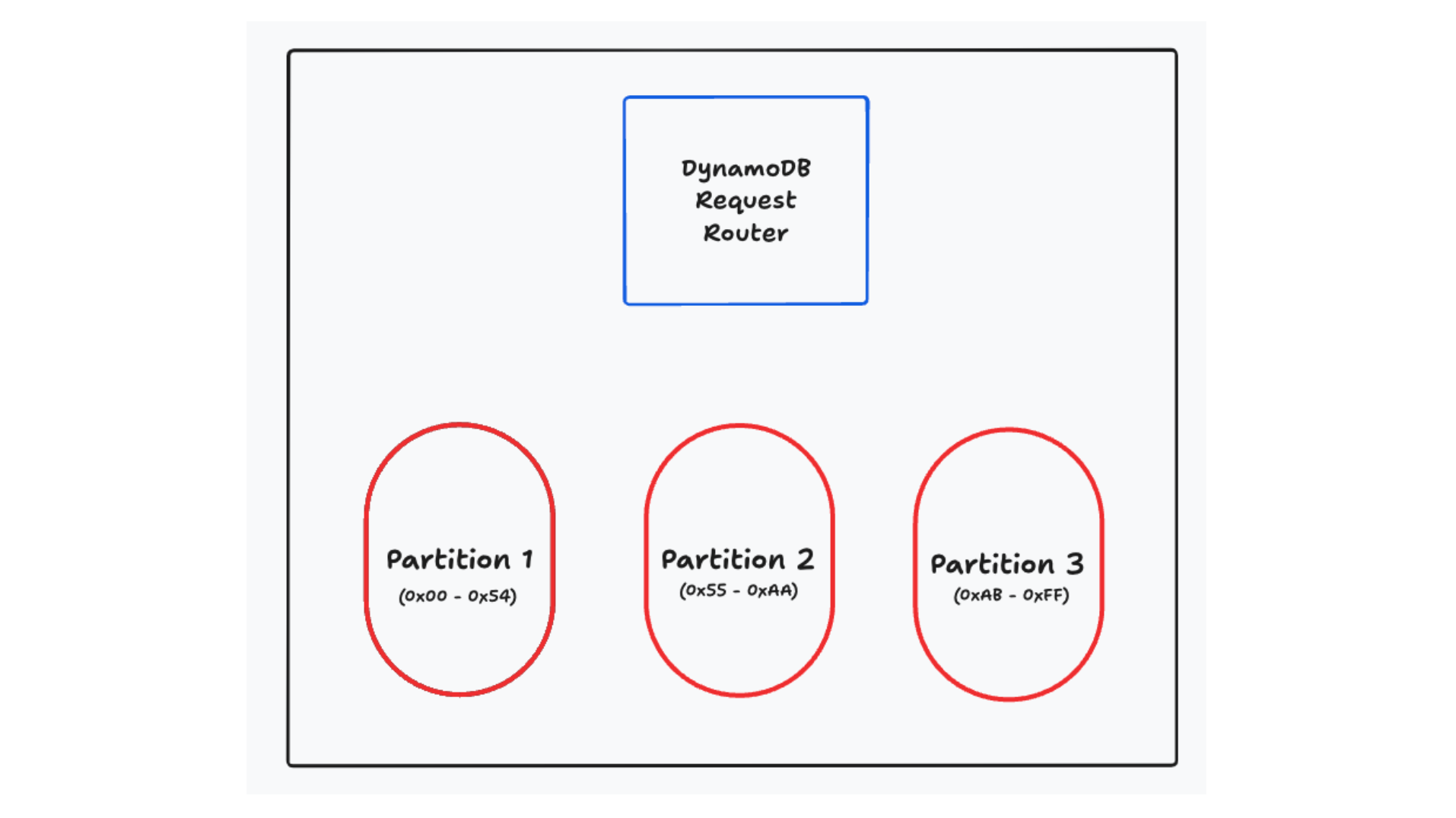
Horizontal scalability through sharding is fascinating however is certainly not distinctive to DynamoDB. Many different databases — each relational and non-relational — use sharding to horizontally scale. Nevertheless, what is distinctive to DynamoDB is the way it forces you to make use of your main key to entry your knowledge. Moderately than utilizing a question planner that interprets your requests right into a collection of queries, DynamoDB forces you to make use of your main key to entry your knowledge. You’re primarily getting a instantly addressable index in your knowledge.
The API for DynamoDB displays this. There are a collection of operations on particular person gadgets (GetItem, PutItem, UpdateItem, DeleteItem) that can help you learn, write, and delete particular person gadgets. Moreover, there’s a Question operation that permits you to retrieve a number of gadgets with the identical partition key. When you’ve got a desk with a composite main key, gadgets with the identical partition key can be grouped collectively on the identical partition. They are going to be ordered in line with the kind key, permitting you to deal with patterns like “Fetch the latest Orders for a Consumer” or “Fetch the final 10 Sensor Readings for an IoT System”.
For instance, lets say a SaaS utility that has a desk of Customers. All Customers belong to a single Group. We’d have a desk that appears as follows:
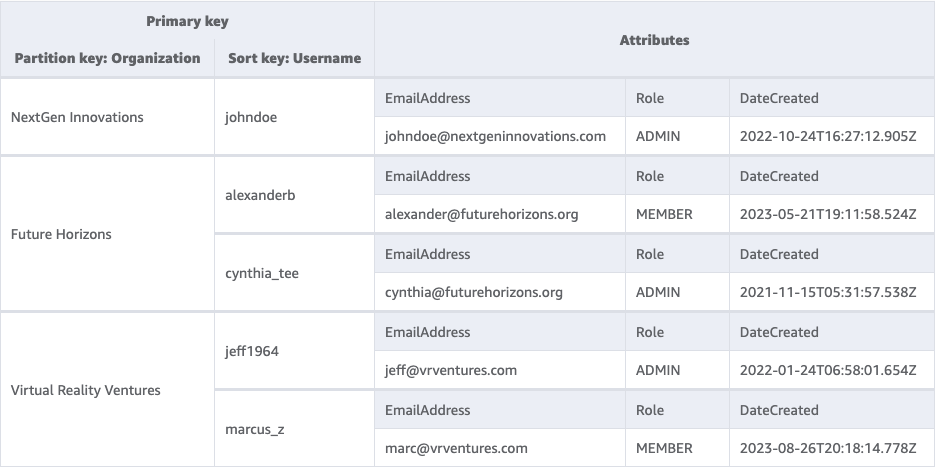
We’re utilizing a composite main key with a partition key of ‘Group’ and a kind key of ‘Username’. This permits us to do operations to fetch or replace a person Consumer by offering their Group and Username. We will additionally fetch the entire Customers for a single Group by offering simply the Group to a Question operation.
What are secondary indexes, and the way do they work
With some fundamentals in thoughts, let’s now take a look at secondary indexes. The easiest way to grasp the necessity for secondary indexes is to grasp the issue they resolve. We have seen how DynamoDB partitions your knowledge in line with your main key and the way it pushes you to make use of the first key to entry your knowledge. That is all effectively and good for some entry patterns, however what if it’s essential entry your knowledge otherwise?
In our instance above, we had a desk of customers that we accessed by their group and username. Nevertheless, we can also have to fetch a single consumer by their e-mail tackle. This sample would not match with the first key entry sample that DynamoDB pushes us in direction of. As a result of our desk is partitioned by completely different attributes, there’s not a transparent solution to entry our knowledge in the best way we wish. We might do a full desk scan, however that is gradual and inefficient. We might duplicate our knowledge right into a separate desk with a unique main key, however that provides complexity.
That is the place secondary indexes are available. A secondary index is mainly a completely managed copy of your knowledge with a unique main key. You’ll specify a secondary index in your desk by declaring the first key for the index. As writes come into your desk, DynamoDB will mechanically replicate the information to your secondary index.
Observe: All the things on this part applies to world secondary indexes. DynamoDB additionally offers native secondary indexes, that are a bit completely different. In virtually all circumstances, you want a worldwide secondary index. For extra particulars on the variations, take a look at this text on selecting a worldwide or native secondary index.
On this case, we’ll add a secondary index to our desk with a partition key of “E mail”. The secondary index will look as follows:
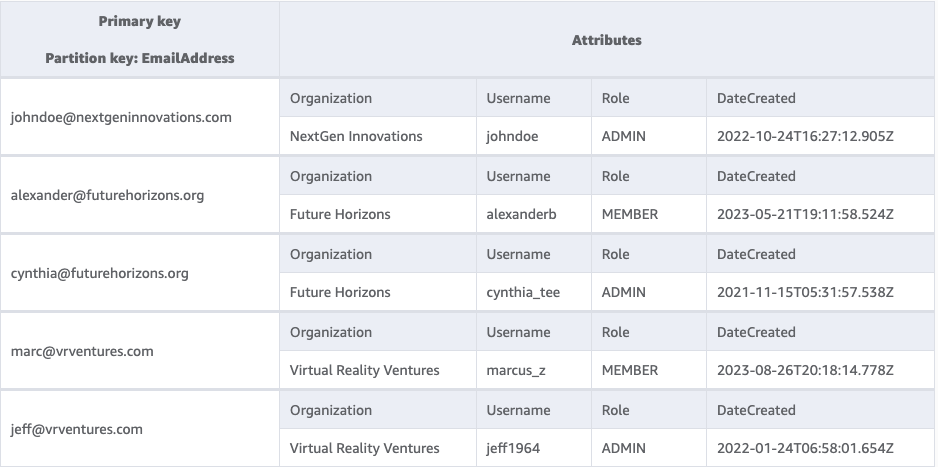
Discover that this is identical knowledge, it has simply been reorganized with a unique main key. Now, we will effectively lookup a consumer by their e-mail tackle.
In some methods, that is similar to an index in different databases. Each present an information construction that’s optimized for lookups on a specific attribute. However DynamoDB’s secondary indexes are completely different in just a few key methods.
First, and most significantly, DynamoDB’s indexes stay on totally completely different partitions than your essential desk. DynamoDB desires each lookup to be environment friendly and predictable, and it desires to supply linear horizontal scaling. To do that, it must reshard your knowledge by the attributes you may use to question it.
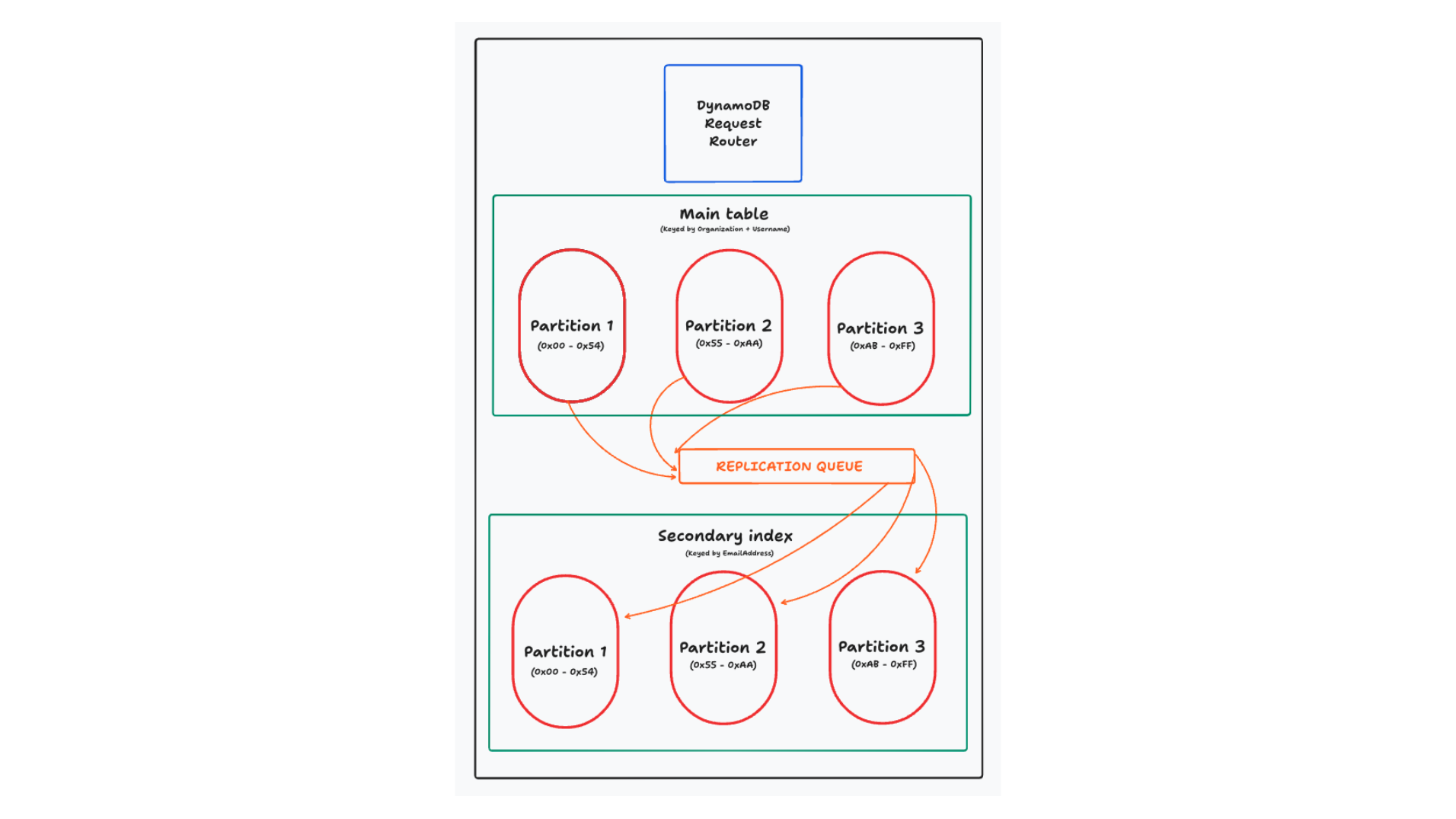
In different distributed databases, they typically do not reshard your knowledge for the secondary index. They’re going to normally simply preserve the secondary index for all knowledge on the shard. Nevertheless, in case your indexes do not use the shard key, you are shedding a number of the advantages of horizontally scaling your knowledge as a question with out the shard key might want to do a scatter-gather operation throughout all shards to search out the information you are on the lookout for.
A second approach that DynamoDB’s secondary indexes are completely different is that they (typically) copy your complete merchandise to the secondary index. For indexes on a relational database, the index will typically comprise a pointer to the first key of the merchandise being listed. After finding a related report within the index, the database will then have to go fetch the complete merchandise. As a result of DynamoDB’s secondary indexes are on completely different nodes than the principle desk, they wish to keep away from a community hop again to the unique merchandise. As an alternative, you may copy as a lot knowledge as you want into the secondary index to deal with your learn.
Secondary indexes in DynamoDB are highly effective, however they’ve some limitations. First off, they’re read-only — you’ll be able to’t write on to a secondary index. Moderately, you’ll write to your essential desk, and DynamoDB will deal with the replication to your secondary index. Second, you’re charged for the write operations to your secondary indexes. Thus, including a secondary index to your desk will typically double the whole write prices in your desk.
Ideas for utilizing secondary indexes
Now that we perceive what secondary indexes are and the way they work, let’s speak about methods to use them successfully. Secondary indexes are a strong instrument, however they are often misused. Listed below are some suggestions for utilizing secondary indexes successfully.
Attempt to have read-only patterns on secondary indexes
The primary tip appears apparent — secondary indexes can solely be used for reads, so you need to goal to have read-only patterns in your secondary indexes! And but, I see this error on a regular basis. Builders will first learn from a secondary index, then write to the principle desk. This leads to further value and further latency, and you may typically keep away from it with some upfront planning.
Should you’ve learn something about DynamoDB knowledge modeling, you in all probability know that you need to consider your entry patterns first. It is not like a relational database the place you first design normalized tables after which write queries to hitch them collectively. In DynamoDB, you need to take into consideration the actions your utility will take, after which design your tables and indexes to assist these actions.
When designing my desk, I like to begin with the write-based entry patterns first. With my writes, I am typically sustaining some sort of constraint — uniqueness on a username or a most variety of members in a bunch. I wish to design my desk in a approach that makes this simple, ideally with out utilizing DynamoDB Transactions or utilizing a read-modify-write sample that might be topic to race circumstances.
As you’re employed by way of these, you may typically discover that there is a ‘main’ solution to determine your merchandise that matches up together with your write patterns. This may find yourself being your main key. Then, including in further, secondary learn patterns is simple with secondary indexes.
In our Customers instance earlier than, each Consumer request will possible embody the Group and the Username. This may permit me to lookup the person Consumer report in addition to authorize particular actions by the Consumer. The e-mail tackle lookup could also be for much less distinguished entry patterns, like a ‘forgot password’ stream or a ‘seek for a consumer’ stream. These are read-only patterns, they usually match effectively with a secondary index.
Use secondary indexes when your keys are mutable
A second tip for utilizing secondary indexes is to make use of them for mutable values in your entry patterns. Let’s first perceive the reasoning behind it, after which take a look at conditions the place it applies.
DynamoDB permits you to replace an current merchandise with the UpdateItem
operation. Nevertheless, you can not change the first key of an merchandise in an replace. The first key’s the distinctive identifier for an merchandise, and altering the first key’s mainly creating a brand new merchandise. If you wish to change the first key of an current merchandise, you may have to delete the previous merchandise and create a brand new one. This two-step course of is slower and dear. Usually you may have to learn the unique merchandise first, then use a transaction to delete the unique merchandise and create a brand new one in the identical request.
However, when you have this mutable worth within the main key of a secondary index, then DynamoDB will deal with this delete + create course of for you throughout replication. You may situation a easy UpdateItem request to alter the worth, and DynamoDB will deal with the remaining.
I see this sample come up in two essential conditions. The primary, and commonest, is when you’ve got a mutable attribute that you simply wish to kind on. The canonical examples listed below are a leaderboard for a recreation the place individuals are frequently racking up factors, or for a frequently updating listing of things the place you wish to show probably the most lately up to date gadgets first. Consider one thing like Google Drive, the place you’ll be able to kind your recordsdata by ‘final modified’.
A second sample the place this comes up is when you’ve got a mutable attribute that you simply wish to filter on. Right here, you’ll be able to consider an ecommerce retailer with a historical past of orders for a consumer. You could wish to permit the consumer to filter their orders by standing — present me all my orders which might be ‘shipped’ or ‘delivered’. You may construct this into your partition key or the start of your kind key to permit exact-match filtering. Because the merchandise modifications standing, you’ll be able to replace the standing attribute and lean on DynamoDB to group the gadgets accurately in your secondary index.
In each of those conditions, shifting this mutable attribute to your secondary index will prevent money and time. You will save time by avoiding the read-modify-write sample, and you may get monetary savings by avoiding the additional write prices of the transaction.
Moreover, be aware that this sample matches effectively with the earlier tip. It is unlikely you’ll determine an merchandise for writing based mostly on the mutable attribute like their earlier rating, their earlier standing, or the final time they have been up to date. Moderately, you may replace by a extra persistent worth, just like the consumer’s ID, the order ID, or the file’s ID. Then, you may use the secondary index to kind and filter based mostly on the mutable attribute.
Keep away from the ‘fats’ partition
We noticed above that DynamoDB divides your knowledge into partitions based mostly on the first key. DynamoDB goals to maintain these partitions small — 10GB or much less — and you need to goal to unfold requests throughout your partitions to get the advantages of DynamoDB’s scalability.
This typically means you need to use a high-cardinality worth in your partition key. Consider one thing like a username, an order ID, or a sensor ID. There are massive numbers of values for these attributes, and DynamoDB can unfold the site visitors throughout your partitions.
Usually, I see folks perceive this precept of their essential desk, however then fully neglect about it of their secondary indexes. Usually, they need ordering throughout your complete desk for a kind of merchandise. In the event that they wish to retrieve customers alphabetically, they’re going to use a secondary index the place all customers have USERS because the partition key and the username as the kind key. Or, if they need ordering of the latest orders in an ecommerce retailer, they’re going to use a secondary index the place all orders have ORDERS because the partition key and the timestamp as the kind key.
This sample can work for small-traffic functions the place you will not come near the DynamoDB partition throughput limits, however it’s a harmful sample for a high traffic utility. Your entire site visitors could also be funneled to a single bodily partition, and you may shortly hit the write throughput limits for that partition.
Additional, and most dangerously, this could trigger issues in your essential desk. In case your secondary index is getting write throttled throughout replication, the replication queue will again up. If this queue backs up an excessive amount of, DynamoDB will begin rejecting writes in your essential desk.
That is designed that will help you — DynamoDB desires to restrict the staleness of your secondary index, so it would forestall you from a secondary index with a considerable amount of lag. Nevertheless, it may be a stunning state of affairs that pops up if you’re least anticipating it.
Use sparse indexes as a worldwide filter
Individuals typically consider secondary indexes as a solution to replicate all of their knowledge with a brand new main key. Nevertheless, you do not want your entire knowledge to finish up in a secondary index. When you’ve got an merchandise that does not match the index’s key schema, it will not be replicated to the index.
This may be actually helpful for offering a worldwide filter in your knowledge. The canonical instance I take advantage of for it is a message inbox. In your essential desk, you would possibly retailer all of the messages for a specific consumer ordered by the point they have been created.
However when you’re like me, you’ve got loads of messages in your inbox. Additional, you would possibly deal with unread messages as a ‘todo’ listing, like little reminders to get again to somebody. Accordingly, I normally solely wish to see the unread messages in my inbox.
You may use your secondary index to supply this world filter the place unread == true. Maybe your secondary index partition key’s one thing like ${userId}#UNREAD, and the kind key’s the timestamp of the message. Whenever you create the message initially, it would embody the secondary index partition key worth and thus can be replicated to the unread messages secondary index. Later, when a consumer reads the message, you’ll be able to change the standing to READ and delete the secondary index partition key worth. DynamoDB will then take away it out of your secondary index.
I take advantage of this trick on a regular basis, and it is remarkably efficient. Additional, a sparse index will prevent cash. Any updates to learn messages is not going to be replicated to the secondary index, and you may save on write prices.
Slim your secondary index projections to scale back index dimension and/or writes
For our final tip, let’s take the earlier level just a little additional. We simply noticed that DynamoDB will not embody an merchandise in your secondary index if the merchandise would not have the first key parts for the index. This trick can be utilized for not solely main key parts but in addition for non-key attributes within the knowledge!
Whenever you create a secondary index, you’ll be able to specify which attributes from the principle desk you wish to embody within the secondary index. That is referred to as the projection of the index. You may select to incorporate all attributes from the principle desk, solely the first key attributes, or a subset of the attributes.
Whereas it is tempting to incorporate all attributes in your secondary index, this generally is a pricey mistake. Do not forget that each write to your essential desk that modifications the worth of a projected attribute can be replicated to your secondary index. A single secondary index with full projection successfully doubles the write prices in your desk. Every further secondary index will increase your write prices by 1/N + 1, the place N is the variety of secondary indexes earlier than the brand new one.
Moreover, your write prices are calculated based mostly on the dimensions of your merchandise. Every 1KB of information written to your desk makes use of a WCU. Should you’re copying a 4KB merchandise to your secondary index, you may be paying the complete 4 WCUs on each your essential desk and your secondary index.
Thus, there are two methods you can get monetary savings by narrowing your secondary index projections. First, you’ll be able to keep away from sure writes altogether. When you’ve got an replace operation that does not contact any attributes in your secondary index projection, DynamoDB will skip the write to your secondary index. Second, for these writes that do replicate to your secondary index, it can save you cash by decreasing the dimensions of the merchandise that’s replicated.
This generally is a difficult stability to get proper. Secondary index projections will not be alterable after the index is created. Should you discover that you simply want further attributes in your secondary index, you may have to create a brand new index with the brand new projection after which delete the previous index.
Must you use a secondary index?
Now that we have explored some sensible recommendation round secondary indexes, let’s take a step again and ask a extra elementary query — must you use a secondary index in any respect?
As we have seen, secondary indexes assist you entry your knowledge otherwise. Nevertheless, this comes at the price of the extra writes. Thus, my rule of thumb for secondary indexes is:
Use secondary indexes when the diminished learn prices outweigh the elevated write prices.
This appears apparent if you say it, however it may be counterintuitive as you are modeling. It appears really easy to say “Throw it in a secondary index” with out enthusiastic about different approaches.
To carry this residence, let us take a look at two conditions the place secondary indexes may not make sense.
A number of filterable attributes in small merchandise collections
With DynamoDB, you typically need your main keys to do your filtering for you. It irks me just a little each time I take advantage of a Question in DynamoDB however then carry out my very own filtering in my utility — why could not I simply construct that into the first key?
Regardless of my visceral response, there are some conditions the place you would possibly wish to over-read your knowledge after which filter in your utility.
The commonest place you may see that is if you wish to present loads of completely different filters in your knowledge in your customers, however the related knowledge set is bounded.
Consider a exercise tracker. You would possibly wish to permit customers to filter on loads of attributes, reminiscent of sort of exercise, depth, period, date, and so forth. Nevertheless, the variety of exercises a consumer has goes to be manageable — even an influence consumer will take some time to exceed 1000 exercises. Moderately than placing indexes on all of those attributes, you’ll be able to simply fetch all of the consumer’s exercises after which filter in your utility.
That is the place I like to recommend doing the mathematics. DynamoDB makes it straightforward to calculate these two choices and get a way of which one will work higher in your utility.
A number of filterable attributes in massive merchandise collections
Let’s change our state of affairs a bit — what if our merchandise assortment is massive? What if we’re constructing a exercise tracker for a fitness center, and we wish to permit the fitness center proprietor to filter on the entire attributes we talked about above for all of the customers within the fitness center?
This modifications the state of affairs. Now we’re speaking about tons of and even hundreds of customers, every with tons of or hundreds of exercises. It will not make sense to over-read your complete merchandise assortment and do post-hoc filtering on the outcomes.
However secondary indexes do not actually make sense right here both. Secondary indexes are good for identified entry patterns the place you’ll be able to depend on the related filters being current. If we wish our fitness center proprietor to have the ability to filter on a wide range of attributes, all of that are non-compulsory, we might have to create numerous indexes to make this work.
We talked concerning the doable downsides of question planners earlier than, however question planners have an upside too. Along with permitting for extra versatile queries, they’ll additionally do issues like index intersections to have a look at partial outcomes from a number of indexes in composing these queries. You are able to do the identical factor with DynamoDB, however it should lead to loads of backwards and forwards together with your utility, together with some advanced utility logic to determine it out.
When I’ve most of these issues, I typically search for a instrument higher fitted to this use case. Rockset and Elasticsearch are my go-to suggestions right here for offering versatile, secondary-index-like filtering throughout your dataset.
Conclusion
On this publish, we discovered about DynamoDB secondary indexes. First, we checked out some conceptual bits to grasp how DynamoDB works and why secondary indexes are wanted. Then, we reviewed some sensible tricks to perceive methods to use secondary indexes successfully and to study their particular quirks. Lastly, we checked out how to consider secondary indexes to see when you need to use different approaches.
Secondary indexes are a strong instrument in your DynamoDB toolbox, however they are not a silver bullet. As with all DynamoDB knowledge modeling, be sure you rigorously contemplate your entry patterns and depend the prices earlier than you leap in.
Study extra about how you need to use Rockset for secondary-index-like filtering in Alex DeBrie’s weblog DynamoDB Filtering and Aggregation Queries Utilizing SQL on Rockset.