

{kind=link}
For the reason that launch of ChatGPT in November 2022, the GenAI
panorama has undergone speedy cycles of experimentation, enchancment, and
adoption throughout a variety of use instances. Utilized to the software program
engineering trade, GenAI assistants primarily assist engineers write code
sooner by offering autocomplete solutions and producing code snippets
primarily based on pure language descriptions. This strategy is used for each
producing and testing code. Whereas we recognise the large potential of
utilizing GenAI for ahead engineering, we additionally acknowledge the numerous
problem of coping with the complexities of legacy techniques, along with
the truth that builders spend much more time studying code than writing it.
By way of modernizing quite a few legacy techniques for our purchasers, we have now discovered that an evolutionary strategy makes
legacy displacement each safer and simpler at attaining its worth targets. This technique not solely reduces the
dangers of modernizing key enterprise techniques but in addition permits us to generate worth early and incorporate frequent
suggestions by regularly releasing new software program all through the method. Regardless of the constructive outcomes we have now seen
from this strategy over a “Massive Bang” cutover, the price/time/worth equation for modernizing giant techniques is commonly
prohibitive. We consider GenAI can flip this case round.
For our half, we have now been experimenting over the past 18 months with
LLMs to deal with the challenges related to the
modernization of legacy techniques. Throughout this time, we have now developed three
generations of CodeConcise, an inner modernization
accelerator at Thoughtworks . The motivation for
constructing CodeConcise stemmed from our commentary that the modernization
challenges confronted by our purchasers are related. Our aim is for this
accelerator to turn into our smart default in
legacy modernization, enhancing our modernization worth stream and enabling
us to comprehend the advantages for our purchasers extra effectively.
We intend to make use of this text to share our expertise making use of GenAI for Modernization. Whereas a lot of the
content material focuses on CodeConcise, that is just because we have now hands-on expertise
with it. We don’t recommend that CodeConcise or its strategy is the one solution to apply GenAI efficiently for
modernization. As we proceed to experiment with CodeConcise and different instruments, we
will share our insights and learnings with the group.
GenAI period: A timeline of key occasions
One major purpose for the
present wave of hype and pleasure round GenAI is the
versatility and excessive efficiency of general-purpose LLMs. Every new era of those fashions has constantly
proven enhancements in pure language comprehension, inference, and response
high quality. We’re seeing a variety of organizations leveraging these highly effective
fashions to satisfy their particular wants. Moreover, the introduction of
multimodal AIs, equivalent to text-to-image generative fashions like DALL-E, alongside
with AI fashions able to video and audio comprehension and era,
has additional expanded the applicability of GenAIs. Furthermore, the
newest AI fashions can retrieve new info from real-time sources,
past what’s included of their coaching datasets, additional broadening
their scope and utility.
Since then, we have now noticed the emergence of recent software program merchandise designed
with GenAI at their core. In different instances, current merchandise have turn into
GenAI-enabled by incorporating new options beforehand unavailable. These
merchandise usually make the most of basic objective LLMs, however these quickly hit limitations when their use case goes past
prompting the LLM to generate responses purely primarily based on the info it has been educated with (text-to-text
transformations). For example, in case your use case requires an LLM to grasp and
entry your group’s information, essentially the most economically viable resolution typically
entails implementing a Retrieval-Augmented Era (RAG) strategy.
Alternatively, or together with RAG, fine-tuning a general-purpose mannequin is perhaps acceptable,
particularly when you want the mannequin to deal with advanced guidelines in a specialised
area, or if regulatory necessities necessitate exact management over the
mannequin’s outputs.
The widespread emergence of GenAI-powered merchandise will be partly
attributed to the supply of quite a few instruments and improvement
frameworks. These instruments have democratized GenAI, offering abstractions
over the complexities of LLM-powered workflows and enabling groups to run
fast experiments in sandbox environments with out requiring AI technical
experience. Nevertheless, warning should be exercised in these comparatively early
days to not fall into traps of comfort with frameworks to which
Thoughtworks’ current expertise radar
attests.
Issues that make modernization costly
After we started exploring the usage of “GenAI for Modernization”, we
targeted on issues that we knew we’d face repeatedly – issues
we knew have been those inflicting modernization to be time or value
prohibitive.
- How can we perceive the prevailing implementation particulars of a system?
- How can we perceive its design?
- How can we collect data about it with out having a human professional obtainable
to information us? - Can we assist with idiomatic translation of code at scale to our desired tech
stack? How? - How can we decrease dangers from modernization by bettering and including
automated assessments as a security internet? - Can we extract from the codebase the domains, subdomains, and
capabilities? - How can we offer higher security nets in order that variations in habits
between previous techniques and new techniques are clear and intentional? How will we allow
cut-overs to be as headache free as potential?
Not all of those questions could also be related in each modernization
effort. We’ve intentionally channeled our issues from essentially the most
difficult modernization eventualities: Mainframes. These are a few of the
most important legacy techniques we encounter, each when it comes to measurement and
complexity. If we will remedy these questions on this state of affairs, then there
will definitely be fruit born for different expertise stacks.
The Structure of CodeConcise

Determine 1: The conceptual strategy of CodeConcise.
CodeConcise is impressed by the Code-as-data
idea, the place code is
handled and analyzed in methods historically reserved for information. This implies
we aren’t treating code simply as textual content, however by way of using language
particular parsers, we will extract its intrinsic construction, and map the
relationships between entities within the code. That is carried out by parsing the
code right into a forest of Summary Syntax Timber (ASTs), that are then
saved in a graph database.

Determine 2: An ingestion pipeline in CodeConcise.
Edges between nodes are then established, for instance an edge is perhaps saying
“the code on this node transfers management to the code in that node”. This course of
doesn’t solely permit us to grasp how one file within the codebase may relate
to a different, however we additionally extract at a a lot granular stage, for instance, which
conditional department of the code in a single file transfers management to code within the
different file. The flexibility to traverse the codebase at such a stage of granularity
is especially vital because it reduces noise (i.e. pointless code) from the
context supplied to LLMs, particularly related for information that don’t comprise
extremely cohesive code. Primarily, there are two advantages we observe from this
noise discount. First, the LLM is extra more likely to keep focussed on the immediate.
Second, we use the restricted area within the context window in an environment friendly approach so we
can match extra info into one single immediate. Successfully, this permits the
LLM to investigate code in a approach that’s not restricted by how the code is organized in
the primary place by builders. We seek advice from this deterministic course of because the ingestion pipeline.
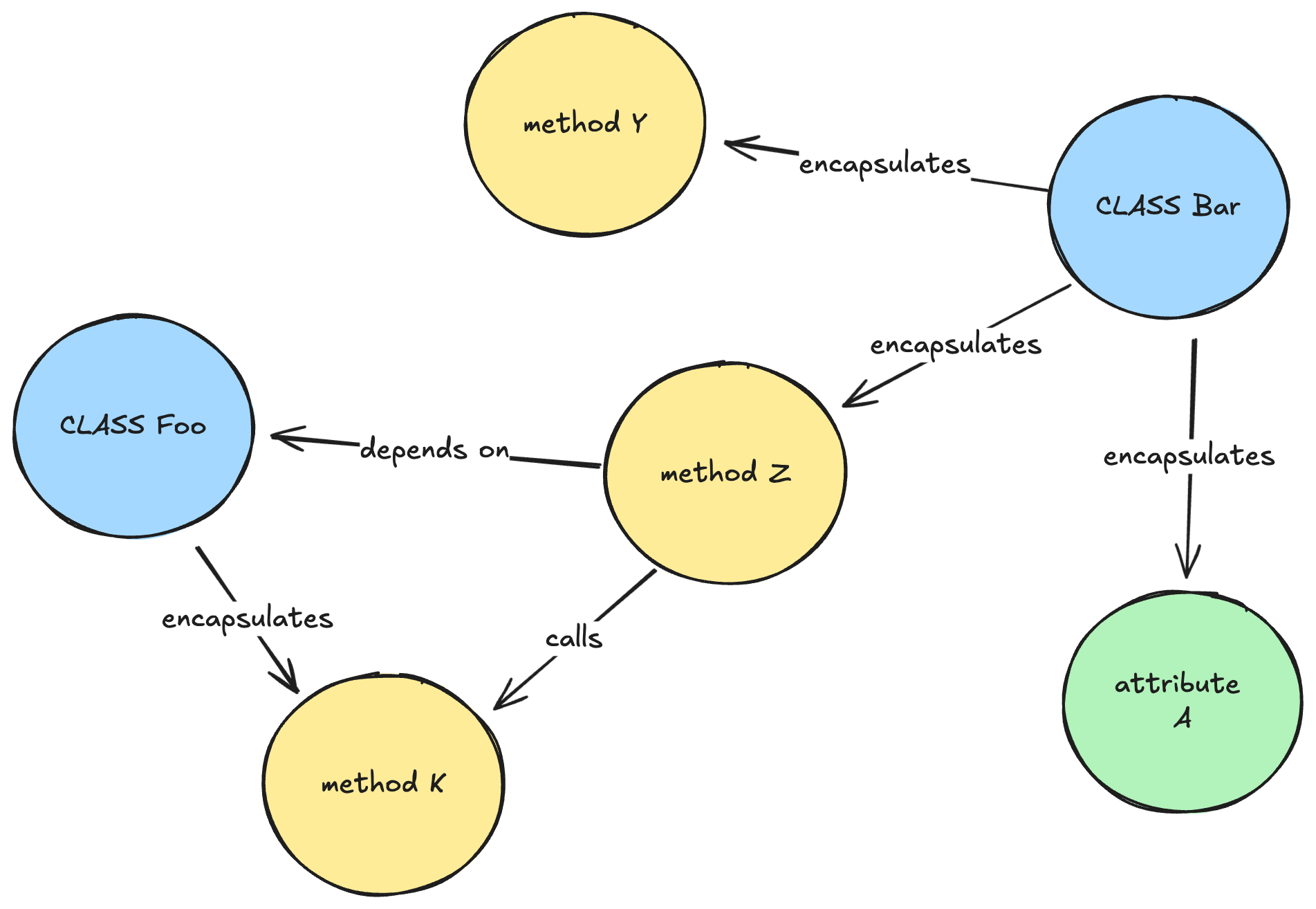
Determine 3: A simplified illustration of how a data graph may appear like for a Java codebase.
Subsequently, a comprehension pipeline traverses the graph utilizing a number of
algorithms, equivalent to Depth-first Search with
backtracking in post-order
traversal, to complement the graph with LLM-generated explanations at numerous depths
(e.g. strategies, lessons, packages). Whereas some approaches at this stage are
widespread throughout legacy tech stacks, we have now additionally engineered prompts in our
comprehension pipeline tailor-made to particular languages or frameworks. As we started
utilizing CodeConcise with actual, manufacturing consumer code, we recognised the necessity to
hold the comprehension pipeline extensible. This ensures we will extract the
data most respected to our customers, contemplating their particular area context.
For instance, at one consumer, we found {that a} question to a selected database
desk applied in code could be higher understood by Enterprise Analysts if
described utilizing our consumer’s enterprise terminology. That is notably related
when there’s not a Ubiquitous
Language shared between
technical and enterprise groups. Whereas the (enriched) data graph is the principle
product of the comprehension pipeline, it isn’t the one useful one. Some
enrichments produced through the pipeline, equivalent to mechanically generated
documentation in regards to the system, are useful on their very own. When supplied
on to customers, these enrichments can complement or fill gaps in current
techniques documentation, if one exists.
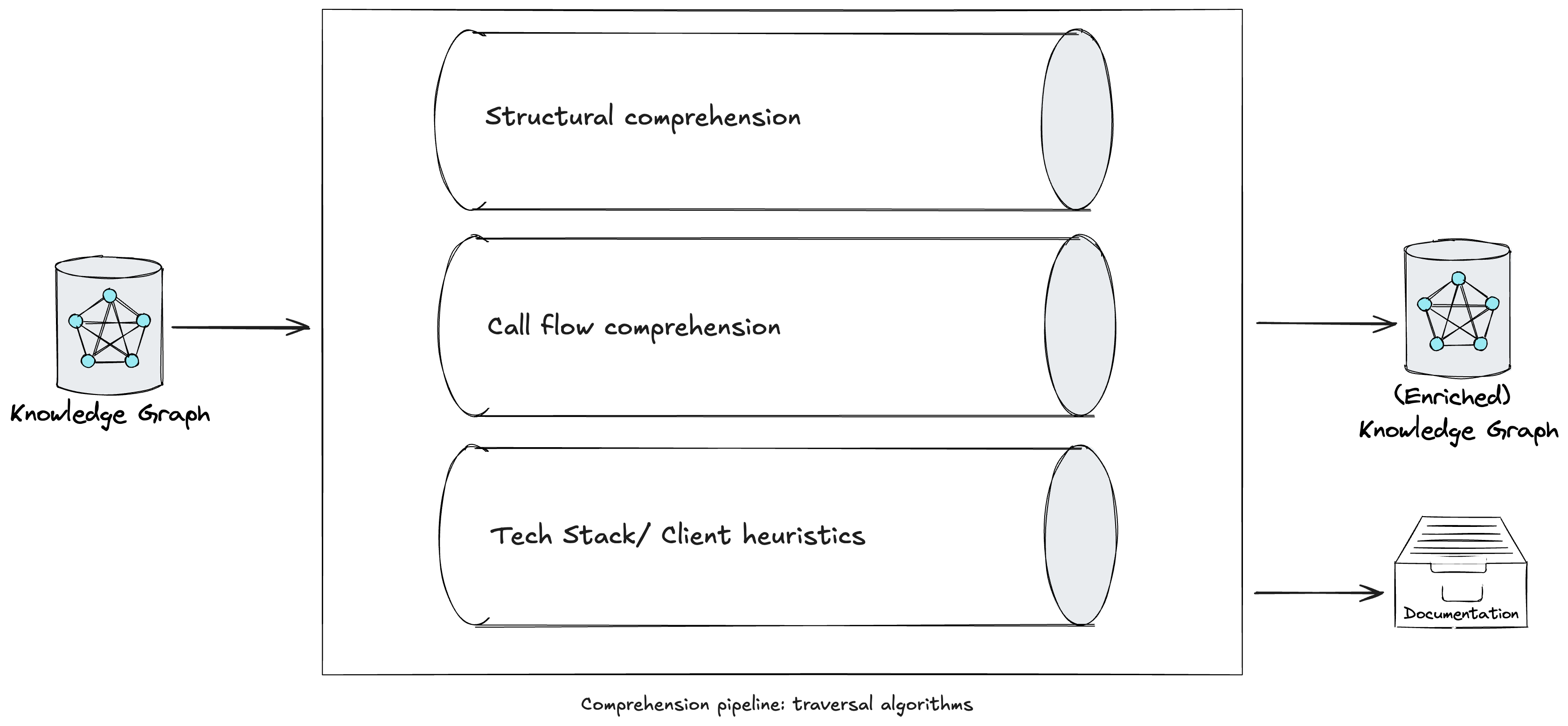
Determine 4: A comprehension pipeline in CodeConcise.
Neo4j, our graph database of alternative, holds the (enriched) Data Graph.
This DBMS options vector search capabilities, enabling us to combine the
Data Graph into the frontend utility implementing RAG. This strategy
gives the LLM with a a lot richer context by leveraging the graph’s construction,
permitting it to traverse neighboring nodes and entry LLM-generated explanations
at numerous ranges of abstraction. In different phrases, the retrieval element of RAG
pulls nodes related to the person’s immediate, whereas the LLM additional traverses the
graph to collect extra info from their neighboring nodes. For example,
when in search of info related to a question about “how does authorization
work when viewing card particulars?” the index could solely present again outcomes that
explicitly take care of validating person roles, and the direct code that does so.
Nevertheless, with each behavioral and structural edges within the graph, we will additionally
embody related info in referred to as strategies, the encompassing bundle of code,
and within the information buildings which have been handed into the code when offering
context to the LLM, thus frightening a greater reply. The next is an instance
of an enriched data graph for AWS Card
Demo,
the place blue and inexperienced nodes are the outputs of the enrichments executed within the
comprehension pipeline.

Determine 5: An (enriched) data graph for AWS Card Demo.
The relevance of the context supplied by additional traversing the graph
finally relies on the standards used to assemble and enrich the graph within the
first place. There is no such thing as a one-size-fits-all resolution for this; it’ll depend upon
the particular context, the insights one goals to extract from their code, and,
finally, on the rules and approaches that the event groups adopted
when setting up the answer’s codebase. For example, heavy use of
inheritance buildings may require extra emphasis on INHERITS_FROM edges vs
COMPOSED_OF edges in a codebase that favors composition.
For additional particulars on the CodeConcise resolution mannequin, and insights into the
progressive studying we had by way of the three iterations of the accelerator, we
will quickly be publishing one other article: Code comprehension experiments with
LLMs.
Within the subsequent sections, we delve deeper into particular modernization
challenges that, if solved utilizing GenAI, might considerably affect the price,
worth, and time for modernization – elements that always discourage us from making
the choice to modernize now. In some instances, we have now begun exploring internally
how GenAI may deal with challenges we have now not but had the chance to
experiment with alongside our purchasers. The place that is the case, our writing is
extra speculative, and we have now highlighted these cases accordingly.
Reverse engineering: drawing out low-level necessities
When enterprise a legacy modernization journey and following a path
like Rewrite or Substitute, we have now realized that, with the intention to draw a
complete listing of necessities for our goal system, we have to
look at the supply code of the legacy system and carry out reverse
engineering. These will information your ahead engineering groups. Not all
these necessities will essentially be included into the goal
system, particularly for techniques developed over a few years, a few of which
could not be related in in the present day’s enterprise and market context.
Nevertheless, it’s essential to grasp current habits to make knowledgeable
selections about what to retain, discard, and introduce in your new
system.
The method of reverse engineering a legacy codebase will be time
consuming and requires experience from each technical and enterprise
folks. Allow us to take into account under a few of the actions we carry out to achieve
a complete low-level understanding of the necessities, together with
how GenAI might help improve the method.
Guide code critiques
Encompassing each static and dynamic code evaluation. Static
evaluation entails reviewing the supply code straight, generally
aided by particular instruments for a given technical stack. These purpose to
extract insights equivalent to dependency diagrams, CRUD (Create Learn
Replace Delete) reviews for the persistence layer, and low-level
program flowcharts. Dynamic code evaluation, however,
focuses on the runtime habits of the code. It’s notably
helpful when a piece of the code will be executed in a managed
atmosphere to watch its habits. Analyzing logs produced throughout
runtime also can present useful insights into the system’s
habits and its parts. GenAI can considerably improve
the understanding and clarification of code by way of code critiques,
particularly for engineers unfamiliar with a selected tech stack,
which is commonly the case with legacy techniques. We consider this
functionality is invaluable to engineering groups, because it reduces the
typically inevitable dependency on a restricted variety of specialists in a
particular stack. At one consumer, we have now leveraged CodeConcise,
using an LLM to extract low-level necessities from the code. We
have prolonged the comprehension pipeline to supply static reviews
containing the data Enterprise Analysts (BAs) wanted to
successfully derive necessities from the code, demonstrating how
GenAI can empower non-technical folks to be concerned in
this particular use case.
Abstracted program flowcharts
Low-level program flowcharts can obscure the general intent of
the code and overwhelm BAs with extreme technical particulars.
Due to this fact, collaboration between reverse engineers and Topic
Matter Specialists (SMEs) is essential. This collaboration goals to create
abstracted variations of program flowcharts that protect the
important flows and intentions of the code. These visible artifacts
help BAs in harvesting necessities for ahead engineering. We’ve
learnt with our consumer that we might make use of GenAI to supply
summary flowcharts for every module within the system. Whereas it could be
cheaper to manually produce an summary flowchart at a system stage,
doing so for every module(~10,000 strains of code, with a complete of 1500
modules) could be very inefficient. With GenAI, we have been capable of
present BAs with visible abstractions that exposed the intentions of
the code, whereas eradicating many of the technical jargon.
SME validation
SMEs are consulted at a number of phases through the reverse
engineering course of by each builders and BAs. Their mixed
technical and enterprise experience is used to validate the
understanding of particular elements of the system and the artifacts
produced through the course of, in addition to to make clear any excellent
queries. Their enterprise and technical experience, developed over many
years, makes them a scarce useful resource inside organizations. Typically,
they’re stretched too skinny throughout a number of groups simply to “hold
the lights on”. This presents a chance for GenAI
to scale back dependencies on SMEs. At our consumer, we experimented with
the chatbot featured in CodeConcise, which permits BAs to make clear
uncertainties or request extra info. This chatbot, as
beforehand described, leverages LLM and Data Graph applied sciences
to offer solutions just like these an SME would supply, serving to to
mitigate the time constraints BAs face when working with them.
Thoughtworks labored with the consumer talked about earlier to discover methods to
speed up the reverse engineering of a big legacy codebase written in COBOL/
IDMS. To realize this, we prolonged CodeConcise to assist the consumer’s tech
stack and developed a proof of idea (PoC) using the accelerator within the
method described above. Earlier than the PoC, reverse engineering 10,000 strains of code
usually took 6 weeks (2 FTEs working for 4 weeks, plus wait time and an SME
assessment). On the finish of the PoC, we estimated that our resolution might scale back this
by two-thirds, from 6 weeks to 2 weeks for a module. This interprets to a
potential saving of 240 FTE years for the whole mainframe modernization
program.
Excessive-level, summary clarification of a system
We’ve skilled that LLMs might help us perceive low-level
necessities extra rapidly. The subsequent query is whether or not they also can
assist us with high-level necessities. At this stage, there’s a lot
info to soak up and it’s robust to digest all of it. To deal with this,
we create psychological fashions which function abstractions that present a
conceptual, manageable, and understandable view of the purposes we
are wanting into. Often, these fashions exist solely in folks’s heads.
Our strategy entails working carefully with specialists, each technical and
enterprise focussed, early on within the undertaking. We maintain workshops, equivalent to
Occasion
Storming
from Area-driven Design, to extract SMEs’ psychological fashions and retailer them
on digital boards for visibility, steady evolution, and
collaboration. These fashions comprise a site language understood by each
enterprise and technical folks, fostering a shared understanding of a
advanced area amongst all staff members. At the next stage of abstraction,
these fashions might also describe integrations with exterior techniques, which
will be both inner or exterior to the group.
It’s changing into evident that entry to, and availability of SMEs is
important for understanding advanced legacy techniques at an summary stage
in an economical method. Lots of the constraints beforehand
highlighted are due to this fact relevant to this modernization
problem.
Within the period of GenAI, particularly within the modernization area, we’re
seeing good outputs from LLMs when they’re prompted to clarify a small
subset of legacy code. Now, we wish to discover whether or not LLMs will be as
helpful in explaining a system at the next stage of abstraction.
Our accelerator, CodeConcise, builds upon Code as Information methods by
using the graph illustration of a legacy system codebase to
generate LLM-generated explanations of code and ideas at totally different
ranges of abstraction:
- Graph traversal technique: We leverage the whole codebase’s
illustration as a graph and use traversal algorithms to complement the graph with
LLM-generated explanations at numerous depths. - Contextual data: Past processing the code and storing it within the
graph, we’re exploring methods to course of any obtainable system documentation, as
it typically gives useful insights into enterprise terminology, processes, and
guidelines, assuming it’s of fine high quality. By connecting this contextual
documentation to code nodes on the graph, our speculation is we will improve
additional the context obtainable to LLMs throughout each upfront code clarification and
when retrieving info in response to person queries.
In the end, the aim is to reinforce CodeConcise’s understanding of the
code with extra summary ideas, enabling its chatbot interface to
reply questions that usually require an SME, maintaining in thoughts that
such questions won’t be straight answerable by analyzing the code
alone.
At Thoughtworks, we’re observing constructive outcomes in each
traversing the graph and producing LLM explanations at numerous ranges
of code abstraction. We’ve analyzed an open-source COBOL repository,
AWS Card
Demo,
and efficiently requested high-level questions equivalent to detailing the system
options and person interactions. On this event, the codebase included
documentation, which supplied extra contextual data for the
LLM. This enabled the LLM to generate higher-quality solutions to our
questions. Moreover, our GenAI-powered staff assistant, Haiven, has
demonstrated at a number of purchasers how contextual details about a
system can allow an LLM to offer solutions tailor-made to
the particular consumer context.
Discovering a functionality map of a system
One of many first issues we do when starting a modernization journey
is catalog current expertise, processes, and the individuals who assist
them. Inside this course of, we additionally outline the scope of what’s going to be
modernized. By assembling and agreeing on these parts, we will construct a
robust enterprise case for the change, develop the expertise and enterprise
roadmaps, and take into account the organizational implications.
With out having this at hand, there is no such thing as a solution to decide what wants
to be included, what the plan to realize is, the incremental steps to
take, and after we are carried out.
Earlier than GenAI, our groups have been utilizing a variety of
methods to construct this understanding, when it isn’t already current.
These methods vary from Occasion Storming and Course of Mapping by way of
to “following the info” by way of the system, and even focused code
critiques for notably advanced subdomains. By combining these
approaches, we will assemble a functionality map of our purchasers’
landscapes.
Whereas this may increasingly appear as if a considerable amount of guide effort, these can
be a few of the most respected actions because it not solely builds a plan for
the longer term supply, however the pondering and collaboration that goes into
making it ensures alignment of the concerned stakeholders, particularly
round what will be included or excluded from the modernization
scope. Additionally, we have now learnt that functionality maps are invaluable after we
take a capability-driven strategy to modernization. This helps modernize
the legacy system incrementally by regularly delivering capabilities in
the goal system, along with designing an structure the place
considerations are cleanly separated.
GenAI modifications this image loads.
One of the crucial highly effective capabilities that GenAI brings is
the power to summarize giant volumes of textual content and different media. We are able to
use this functionality throughout current documentation which may be current
relating to expertise or processes to extract out, if not the tip
data, then at the very least a place to begin for additional conversations.
There are a variety of methods which can be being actively developed and
launched on this space. Specifically, we consider that
GraphRAG which was lately
launched by Microsoft could possibly be used to extract a stage of information from
these paperwork by way of Graph Algorithm evaluation of the physique of
textual content.
We’ve additionally been trialing GenAI excessive of the data graph
that we construct out of the legacy code as talked about earlier by asking what
key capabilities modules have after which clustering and abstracting these
by way of hierarchical summarization. This then serves as a map of
capabilities, expressed succinctly at each a really excessive stage and a
detailed stage, the place every functionality is linked to the supply code
modules the place it’s applied. That is then used to scope and plan for
the modernization in a sooner method. The next is an instance of a
functionality map for a system, together with the supply code modules (small
grey nodes) they’re applied in.
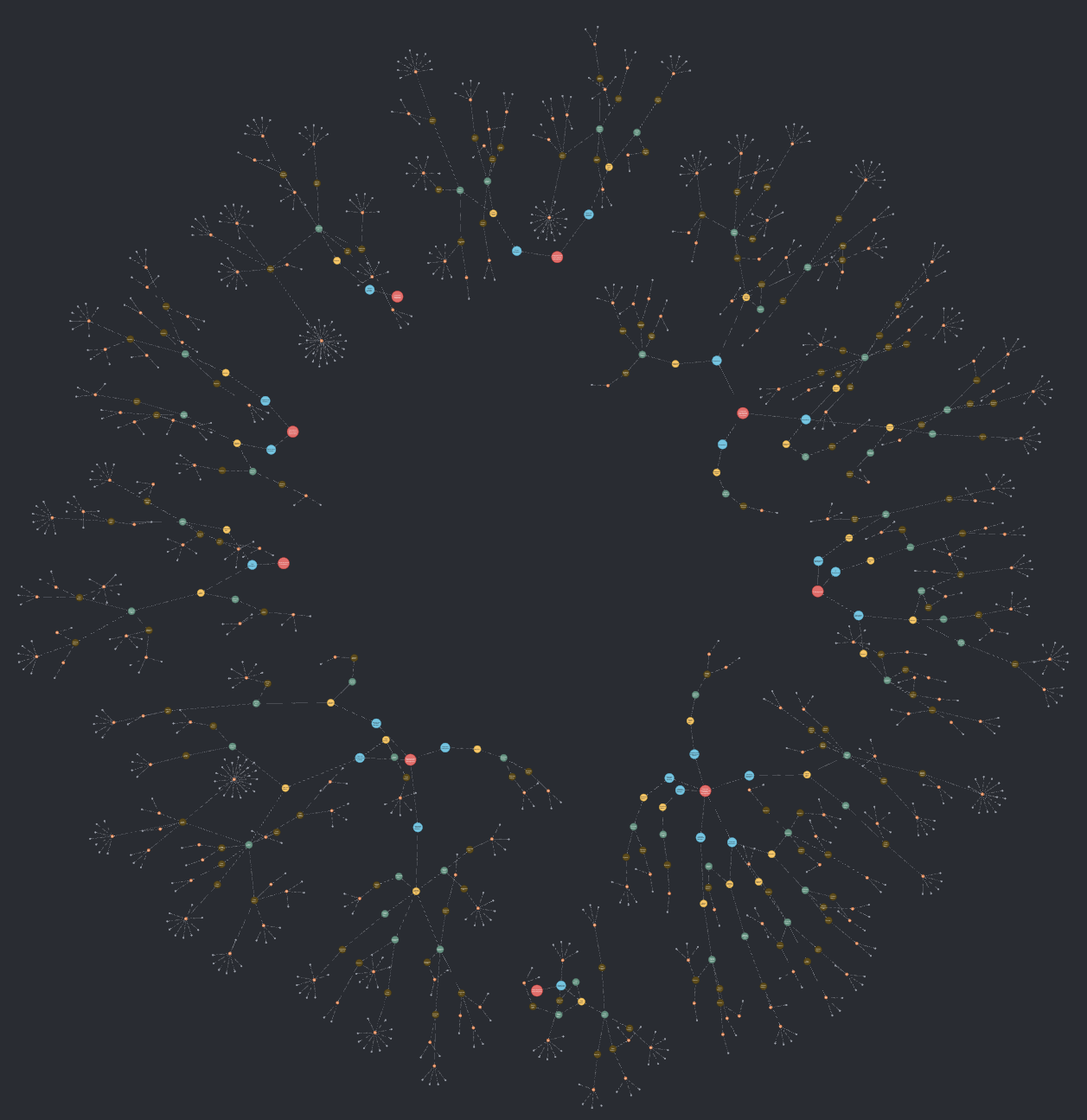
Nonetheless, we have now learnt to not view this solely LLM-generated
functionality map as mutually unique from the normal strategies of
creating functionality maps described earlier. These conventional approaches
are useful not just for aligning stakeholders on the scope of
modernization, but in addition as a result of, when a functionality already exists, it
can be utilized to cluster the supply code primarily based on the capabilities
applied. This strategy produces functionality maps that resonate higher
with SMEs by utilizing the group’s Ubiquitous language. Moreover,
evaluating each functionality maps is perhaps a useful train, absolutely one
we sit up for experimenting with, as every may supply insights the
different doesn’t.
Discovering unused / useless / duplicate code
One other a part of gathering info to your modernization efforts
is knowing inside your scope of labor, “what remains to be getting used at
all”, or “the place have we bought a number of cases of the identical
functionality”.
At present this may be addressed fairly successfully by combining two
approaches: static and dynamic evaluation. Static evaluation can discover unused
technique calls and statements inside sure scopes of interrogation, for
occasion, discovering unused strategies in a Java class, or discovering unreachable
paragraphs in COBOL. Nevertheless, it’s unable to find out whether or not complete
API endpoints or batch jobs are used or not.
That is the place we use dynamic evaluation which leverages system
observability and different runtime info to find out if these
capabilities are nonetheless in use, or will be dropped from our modernization
backlog.
When trying to discover duplicate technical capabilities, static
evaluation is essentially the most generally used device as it may do chunk-by-chunk textual content
similarity checks. Nevertheless, there are main shortcomings when utilized to
even a modest expertise property: we will solely discover code similarities in
the identical language.
We speculate that by leveraging the results of {our capability}
extraction strategy, we will use these expertise agnostic descriptions
of what giant and small abstractions of the code are doing to carry out an
estate-wide evaluation of duplication, which can take our future
structure and roadmap planning to the following stage.
In relation to unused code nevertheless, we see little or no use in
making use of GenAI to the issue. Static evaluation instruments within the trade for
discovering useless code are very mature, leverage the structured nature of
code and are already at builders’ fingertips, like IntelliJ or Sonar.
Dynamic evaluation from APM instruments is so highly effective there’s little that instruments
like GenAI can add to the extraction of data itself.
Then again, these two advanced approaches can yield an enormous
quantity of knowledge to grasp, interrogate and derive perception from. This
could possibly be one space the place GenAI might present a minor acceleration
for discovery of little used code and expertise.
Much like having GenAI seek advice from giant reams of product documentation
or specs, we will leverage its data of the static and
dynamic instruments to assist us use them in the suitable approach for example by
suggesting potential queries that may be run over observability stacks.
NewRelic, for example, claims to have built-in LLMs in to its options to
speed up onboarding and error decision; this could possibly be turned to a
modernization benefit too.
Idiomatic translation of tech paradigm
Translation from one programming language to a different isn’t one thing new. Many of the instruments that do that have
utilized static evaluation methods – utilizing Summary Syntax Timber (ASTs) as intermediaries.
Though these methods and instruments have existed for a very long time, outcomes are sometimes poor when judged by way of
the lens of “would somebody have written it like this if they’d began authoring it in the present day”.
Usually the produced code suffers from:
Poor total Code high quality
Often, the code these instruments produce is syntactically appropriate, however leaves loads to be desired relating to
high quality. Loads of this may be attributed to the algorithmic translation strategy that’s used.
Non-idiomatic code
Usually, the code produced doesn’t match idiomatic paradigms of the goal expertise stack.
Poor naming conventions
Naming is nearly as good or dangerous because it was within the supply language/ tech stack – and even when naming is sweet within the
older code, it doesn’t translate nicely to newer code. Think about mechanically naming lessons/ objects/ strategies
when translating procedural code that transfers information to an OO paradigm!
Isolation from open-source libraries/ frameworks
- Trendy purposes usually use many open-source libraries and frameworks (versus older
languages) – and producing code at most instances doesn’t seamlessly do the identical - That is much more sophisticated in enterprise settings when organizations are inclined to have inner libraries
(that instruments won’t be accustomed to)
Lack of precision in information
Even with primitive varieties languages have totally different precisions – which is more likely to result in a loss in
precision.
Loss in relevance of supply code historical past
Many instances when attempting to grasp code we take a look at how that code advanced to that state with git log [or
equivalents for other SCMs] – however now that historical past isn’t helpful for a similar objective
Assuming a corporation embarks on this journey, it’ll quickly face prolonged testing and verification
cycles to make sure the generated code behaves precisely the identical approach as earlier than. This turns into much more difficult
when little to no security internet was in place initially.
Regardless of all of the drawbacks, code conversion approaches proceed to be an choice that pulls some organizations
due to their attract as doubtlessly the bottom value/ effort resolution for leapfrogging from one tech paradigm
to the opposite.
We’ve additionally been desirous about this and exploring how GenAI might help enhance the code produced/ generated. It
can not help all of these points, however possibly it may assist alleviate at the very least the primary three or 4 of them.
From an strategy perspective, we try to use the rules of
Refactoring
to this – basically
determine a approach we will safely and incrementally make the bounce from one tech paradigm to a different. This strategy
has already seen some success – two examples that come to thoughts:
Conclusion
Right now’s panorama has quite a few alternatives to leverage GenAI to
obtain outcomes that have been beforehand out of attain. Within the software program
trade, GenAI is already enjoying a big position in serving to folks
throughout numerous roles full their duties extra effectively, and this
affect is anticipated to develop. For example, GenAI has produced promising
leads to aiding technical engineers with writing code.
Over the previous a long time, our trade has advanced considerably, growing patterns, finest practices, and
methodologies that information us in constructing fashionable software program. Nevertheless, one of many greatest challenges we now face is
updating the huge quantity of code that helps key operations each day. These techniques are sometimes giant and sophisticated,
with a number of layers and patches constructed over time, making habits tough to alter. Moreover, there are
typically only some specialists who totally perceive the intricate particulars of how these techniques are applied and
function. For these causes, we use an evolutionary strategy to legacy displacement, lowering the dangers concerned
in modernizing these techniques and producing worth early. Regardless of this, the price/time/worth equation for
modernizing giant techniques is commonly prohibitive. On this article, we mentioned methods GenAI will be harnessed to
flip this case round. We are going to proceed experimenting with making use of GenAI to those modernization challenges
and share our insights by way of this text, which we’ll hold updated. This may embody sharing what has
labored, what we consider GenAI might doubtlessly remedy, and what, nevertheless, has not succeeded. Moreover, we
will prolong our accelerator, CodeConcise, with the purpose of additional innovating throughout the modernization course of to
drive better worth for our purchasers.
Hopefully, this text highlights the nice potential of harnessing
this new expertise, GenAI, to deal with a few of the challenges posed by
legacy techniques within the trade. Whereas there is no such thing as a one-size-fits-all
resolution to those challenges – every context has its personal distinctive nuances –
there are sometimes similarities that may information our efforts. We additionally hope this
article evokes others within the trade to additional develop experiments
with “GenAI for Modernization” and share their insights with the broader
group.