

{kind=link}
OpenAI Canvas is a flexible software designed to streamline collaborative coding and textual content enhancing. With its intuitive interface, Canvas provides a dynamic platform for builders to jot down, edit, and debug code alongside ChatGPT’s AI-driven help. This makes it significantly helpful for a variety of duties, from primary scripting to managing complicated tasks. On this article, I’ll discover coding with Canvas and share my general expertise.
Key Options and Benefits of Canvas
- Seamless Collaboration: Canvas integrates conversational interfaces, enabling customers to change, request suggestions, or discover concepts in actual time with out switching instruments.
- Dynamic Coding Setting: Designed for Python builders, Canvas helps code execution, making it excellent for duties like information evaluation, coding, and visualization.
- Multi-functional Platform: Canvas isn’t only for textual content enhancing; it’s a flexible area for brainstorming, coding, and structured workflows.
Checkout – Why o1 Mannequin Higher than GPT-4o
Palms-on Coding with Canvas
Getting Began
I explored the coding options of Canvas with the aim of attaching a dataset and performing primary exploratory information evaluation (EDA). Whereas the interface was intuitive and promising, I encountered challenges in integrating exterior datasets.
The Problem: Accessing Information within the Sandbox
When trying to connect a dataset, I discovered that the sandbox surroundings couldn’t entry the file. As a workaround, I pasted a subset of the info instantly into Canvas, however this didn’t resolve the difficulty. Even with appropriately written code, an error message endured, indicating that the info couldn’t be discovered. This limitation highlights the necessity for enhanced information integration capabilities inside Canvas.
Artificial Information and Visualizations
After encountering these limitations, I prompted Canvas to generate artificial information and carry out visualizations. The next code was generated and executed efficiently:
Immediate: Create a dataset and after which do some visualizations on it.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Step 1: Create a dataset
np.random.seed(42)
information = {
'Class': np.random.selection(['A', 'B', 'C', 'D'], 100),
'Value1': np.random.regular(50, 10, 100),
'Value2': np.random.regular(100, 20, 100),
'Group': np.random.selection(['X', 'Y'], 100)
}
df = pd.DataFrame(information)
# Step 2: Show primary details about the dataset
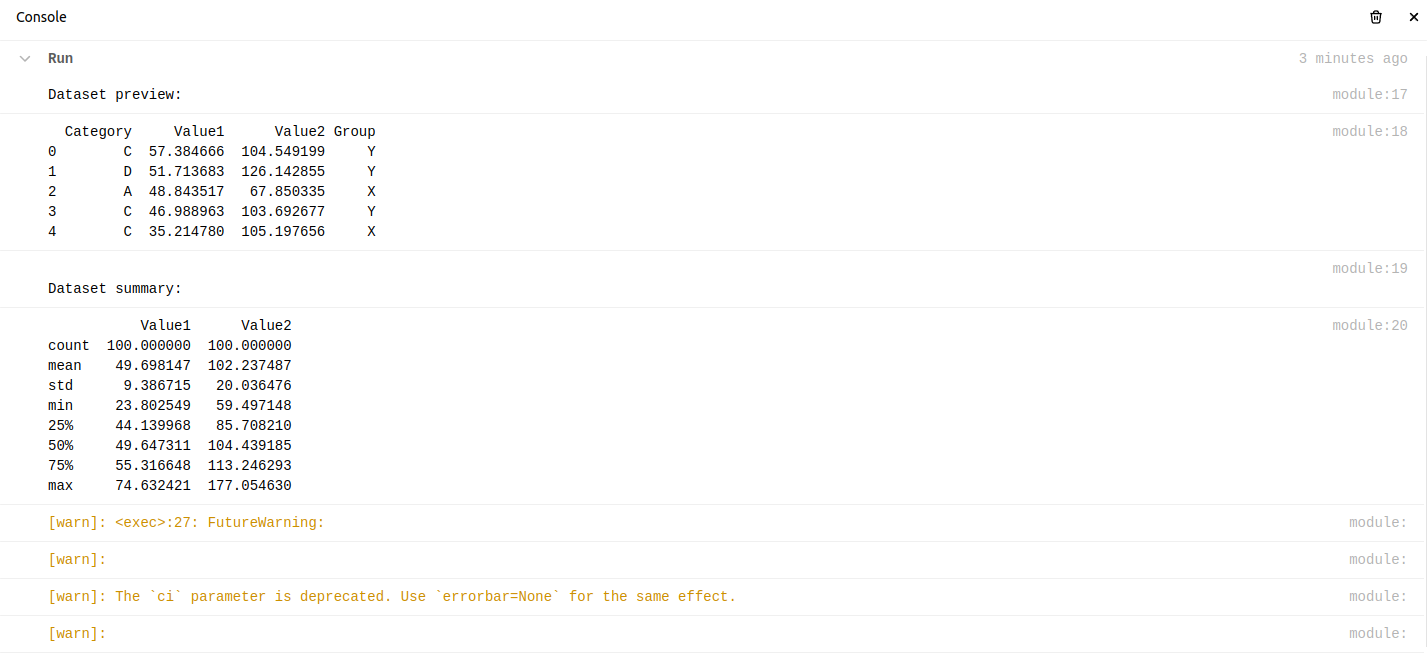
print("Dataset preview:")
print(df.head())
print("nDataset abstract:")
print(df.describe())
# Step 3: Visualizations
plt.determine(figsize=(12, 8))
# Bar plot: Common of Value1 by Class
plt.subplot(2, 2, 1)
sns.barplot(x='Class', y='Value1', information=df, ci=None)
plt.title('Common of Value1 by Class')
# Field plot: Distribution of Value2 by Group
plt.subplot(2, 2, 2)
sns.boxplot(x='Group', y='Value2', information=df)
plt.title('Distribution of Value2 by Group')
# Scatter plot: Value1 vs. Value2
plt.subplot(2, 2, 3)
sns.scatterplot(x='Value1', y='Value2', hue="Class", information=df)
plt.title('Scatter plot of Value1 vs Value2')
# Histogram: Distribution of Value1
plt.subplot(2, 2, 4)
sns.histplot(df['Value1'], kde=True, bins=20)
plt.title('Histogram of Value1')
plt.tight_layout()
plt.present()
And upon run this was the output:
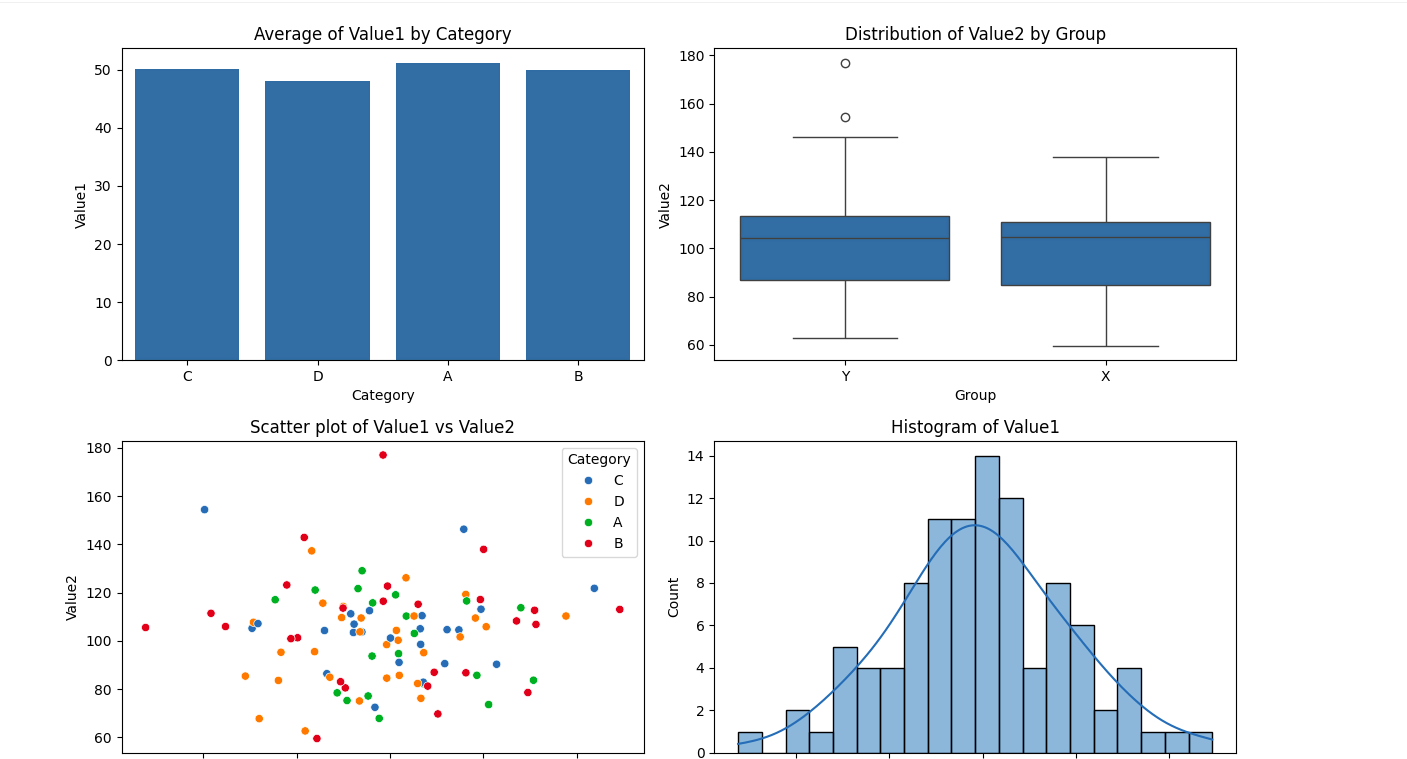
The outcomes had been visually informative, showcasing the platform’s capability to deal with primary EDA duties successfully. Following this, I carried out superior EDA to uncover deeper insights:
Whereas working this advance EDA I acquired this bug:
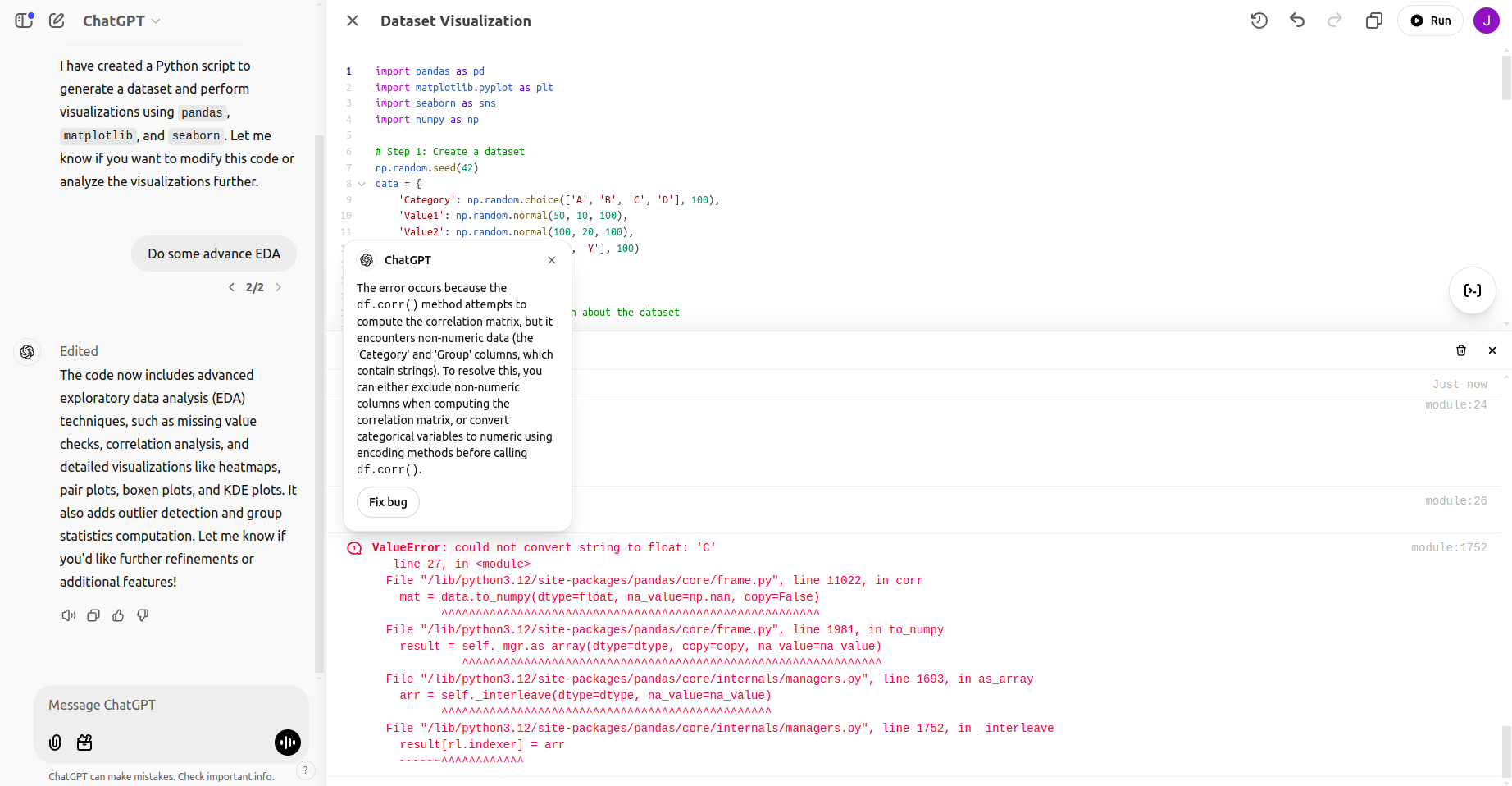
After fixing the bug:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Step 1: Create a dataset
np.random.seed(42)
information = {
'Class': np.random.selection(['A', 'B', 'C', 'D'], 100),
'Value1': np.random.regular(50, 10, 100),
'Value2': np.random.regular(100, 20, 100),
'Group': np.random.selection(['X', 'Y'], 100)
}
df = pd.DataFrame(information)
# Step 2: Show primary details about the dataset
print("Dataset preview:")
print(df.head())
print("nDataset abstract:")
print(df.describe())
# Superior EDA
print("nChecking for lacking values:")
print(df.isnull().sum())
# Guarantee solely numeric information is used for correlation matrix
print("nCorrelation matrix:")
numeric_df = df.select_dtypes(embrace=[np.number])
correlation_matrix = numeric_df.corr()
print(correlation_matrix)
# Visualizations for superior EDA
plt.determine(figsize=(15, 12))
# Heatmap of correlation matrix
plt.subplot(3, 2, 1)
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Matrix Heatmap')
# Pairplot for relationships
sns.pairplot(df, hue="Class", nook=True, diag_kind='kde')
plt.suptitle('Pairplot of Variables', y=1.02)
plt.present()
# Boxen plot: Distribution of Value1 by Class and Group
plt.subplot(3, 2, 2)
sns.boxenplot(x='Class', y='Value1', hue="Group", information=df)
plt.title('Boxen plot of Value1 by Class and Group')
# Violin plot: Distribution of Value2 by Class
plt.subplot(3, 2, 3)
sns.violinplot(x='Class', y='Value2', information=df, hue="Group", break up=True)
plt.title('Violin plot of Value2 by Class')
# Rely plot: Frequency of Classes
plt.subplot(3, 2, 4)
sns.countplot(x='Class', information=df, hue="Group")
plt.title('Frequency of Classes by Group')
# KDE plot: Distribution of Value1 and Value2
plt.subplot(3, 2, 5)
sns.kdeplot(x='Value1', y='Value2', hue="Class", information=df, fill=True, alpha=0.6)
plt.title('KDE plot of Value1 vs Value2')
plt.tight_layout()
plt.present()
# Outlier detection
print("nIdentifying potential outliers:")
for column in ['Value1', 'Value2']:
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df[column] < lower_bound) | (df[column] > upper_bound)]
print(f"Outliers in {column}:n", outliers)
# Group statistics
print("nGroup statistics:")
print(df.groupby(['Category', 'Group']).agg({'Value1': ['mean', 'std'], 'Value2': ['mean', 'std']}))
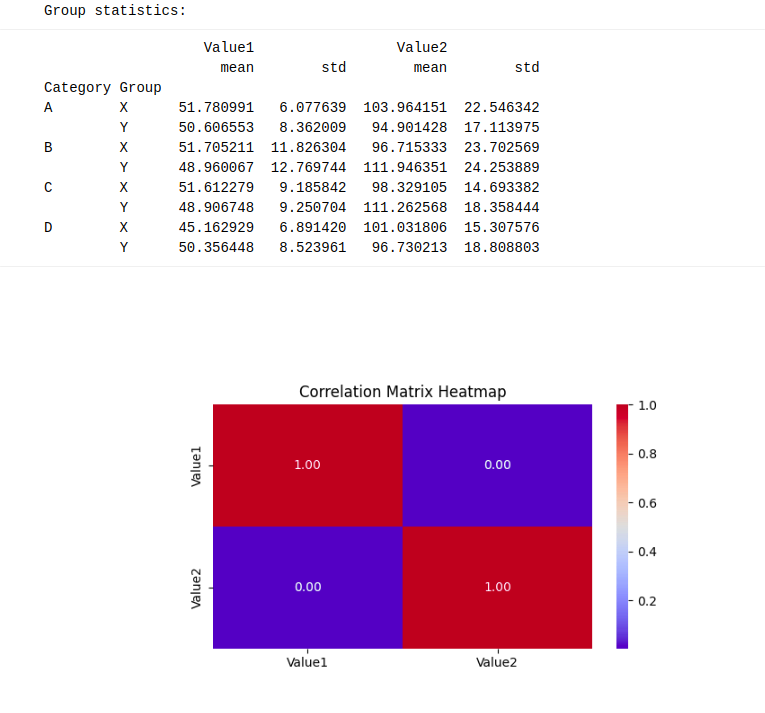
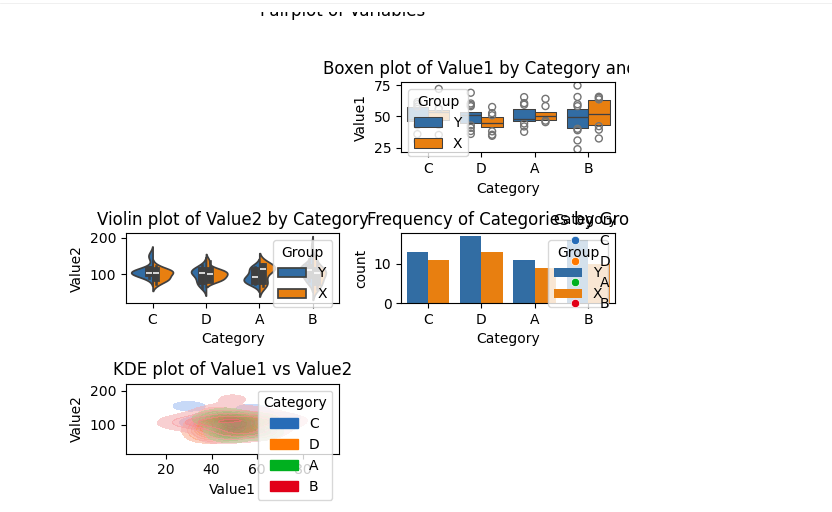
These superior analyses highlighted Canvas’s capabilities for exploratory duties but in addition underscored the platform’s limitations in integrating exterior datasets.
Porting Code to Different Languages
Whereas Canvas helps coding primarily in python, the platform permits customers to port python code to different languages, reminiscent of java. Nevertheless, it doesn’t execute code in languages apart from Python. Right here is an instance of a Python-to-Java port:
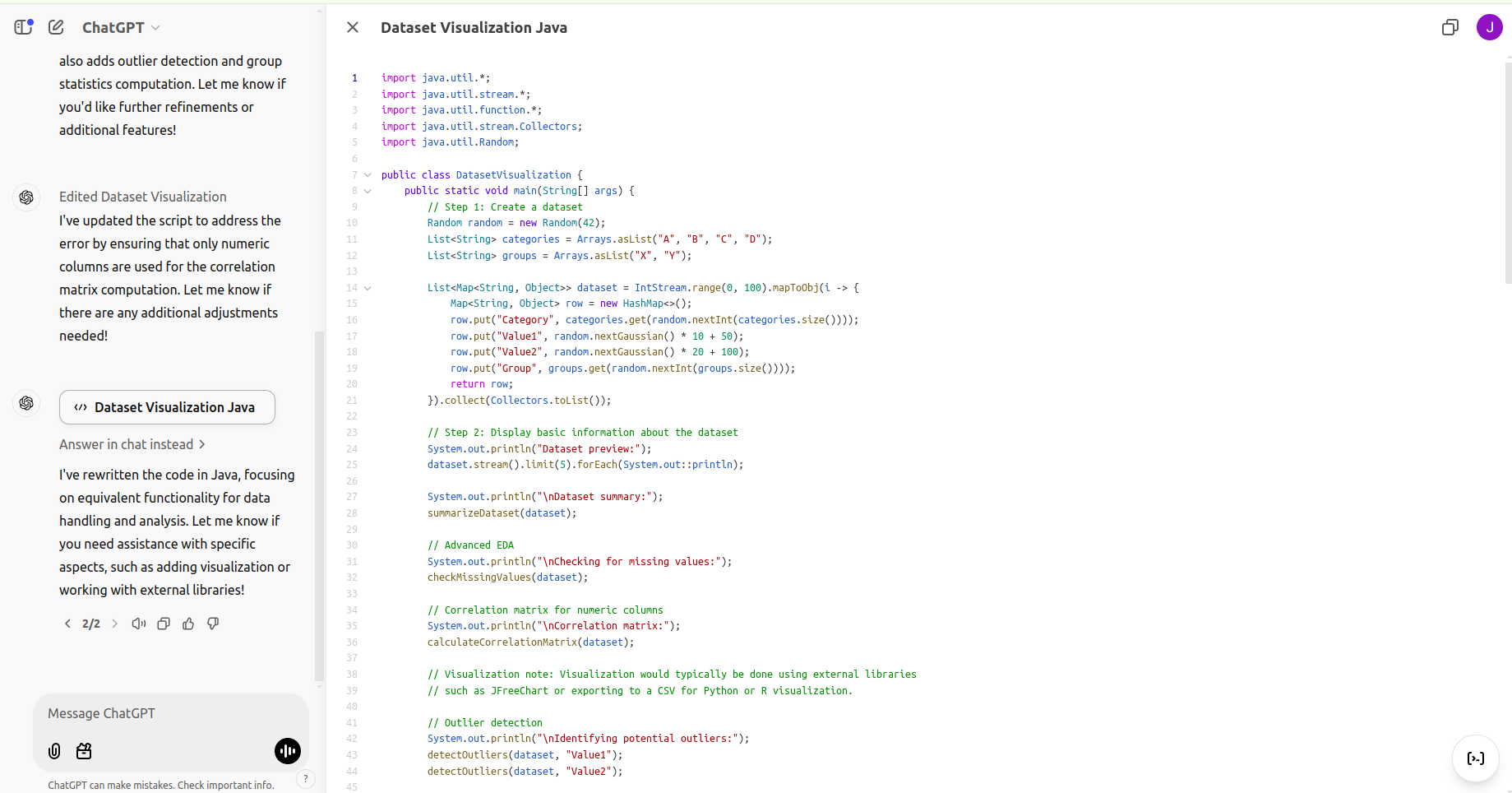
import java.util.*;
import java.util.stream.Collectors;
public class DatasetVisualization {
public static void foremost(String[] args) {
// Step 1: Create an artificial dataset
Random random = new Random(42); // For reproducibility
Record<Integer> ages = random.ints(200, 18, 70).boxed().accumulate(Collectors.toList());
Record<Integer> incomes = random.ints(200, 30000, 120000).boxed().accumulate(Collectors.toList());
Record<String> genders = random.ints(200, 0, 2).mapToObj(i -> i == 0 ? "Male" : "Feminine").accumulate(Collectors.toList());
Record<Integer> spendScores = random.ints(200, 1, 101).boxed().accumulate(Collectors.toList());
Record<String> cities = random.ints(200, 0, 5).mapToObj(i -> {
change (i) {
case 0: return "New York";
case 1: return "Los Angeles";
case 2: return "Chicago";
case 3: return "Houston";
default: return "Phoenix";
}
}).accumulate(Collectors.toList());
// Step 2: Create demographic segments
Record<String> ageGroups = ages.stream().map(age -> {
if (age <= 30) return "Younger";
else if (age <= 50) return "Center-aged";
else return "Senior";
}).accumulate(Collectors.toList());
Record<String> incomeGroups = incomes.stream().map(earnings -> {
if (earnings < 40000) return "Low";
else if (earnings <= 70000) return "Medium";
else return "Excessive";
}).accumulate(Collectors.toList());
// Step 3: Print a abstract of the dataset
System.out.println("Pattern of the dataset:");
for (int i = 0; i < 5; i++) {
System.out.printf("Age: %d, Revenue: %d, Gender: %s, Spend Rating: %d, Metropolis: %s, Age Group: %s, Revenue Group: %sn",
ages.get(i), incomes.get(i), genders.get(i), spendScores.get(i), cities.get(i), ageGroups.get(i), incomeGroups.get(i));
}
// Step 4: Carry out a correlation-like evaluation (simplified for Java)
double ageIncomeCorrelation = calculateCorrelation(ages, incomes);
double ageSpendScoreCorrelation = calculateCorrelation(ages, spendScores);
double incomeSpendScoreCorrelation = calculateCorrelation(incomes, spendScores);
System.out.println("nCorrelation Evaluation:");
System.out.printf("Age-Revenue Correlation: %.2fn", ageIncomeCorrelation);
System.out.printf("Age-Spend Rating Correlation: %.2fn", ageSpendScoreCorrelation);
System.out.printf("Revenue-Spend Rating Correlation: %.2fn", incomeSpendScoreCorrelation);
// Visualizations would usually require a separate library for Java, reminiscent of JFreeChart or JavaFX.
System.out.println("nVisualizations should not applied on this text-based instance.");
}
// Helper methodology to calculate a simplified correlation
personal static double calculateCorrelation(Record<Integer> x, Record<Integer> y) {
if (x.dimension() != y.dimension()) throw new IllegalArgumentException("Lists should have the identical dimension");
int n = x.dimension();
double meanX = x.stream().mapToDouble(a -> a).common().orElse(0);
double meanY = y.stream().mapToDouble(a -> a).common().orElse(0);
double covariance = 0;
double varianceX = 0;
double varianceY = 0;
for (int i = 0; i < n; i++) {
double deltaX = x.get(i) - meanX;
double deltaY = y.get(i) - meanY;
covariance += deltaX * deltaY;
varianceX += deltaX * deltaX;
varianceY += deltaY * deltaY;
}
return covariance / Math.sqrt(varianceX * varianceY);
}
}
Though the Java code offers performance for dataset creation and easy analyses, additional improvement would require extra libraries for visualization.
My Expertise utilizing Canvas
Whereas Canvas helps Python, integrating exterior datasets might be difficult attributable to sandbox restrictions. Nevertheless, producing artificial information inside Canvas or importing subsets of datasets can mitigate these points. Moreover, Python code might be ported to different languages, although execution outdoors Python isn’t supported inside Canvas.
General, Canvas provides a user-friendly and collaborative surroundings. Enhancing its capability to combine exterior information and supporting extra programming languages would make it much more versatile and helpful.
Conclusion
Coding with ChatGPT Canvas combines AI help with a collaborative workspace, making it a sensible software for builders. Whether or not you’re debugging code, analyzing information, or brainstorming concepts, Canvas simplifies the method and boosts productiveness.
Have you ever tried coding with Canvas? Share your experiences and let me know the way it labored for you within the remark part under.
Keep tuned to Analytics Vidhya Weblog for extra such updates!
Often Requested Questions
ChatGPT Canvas is a characteristic that permits customers to edit, collaborate, and refine lengthy paperwork or code instantly alongside their conversations with ChatGPT.
OpenAI provides free entry to some options of ChatGPT, however superior options and fashions typically require a paid subscription.
Sure, OpenAI Canvas permits customers to edit and refine code instantly alongside AI-powered solutions.
Hello, I’m Janvi, a passionate information science fanatic presently working at Analytics Vidhya. My journey into the world of information started with a deep curiosity about how we are able to extract significant insights from complicated datasets.