

{kind=link}
Within the fast-growing space of digital healthcare, medical chatbots have gotten an necessary instrument
for bettering affected person care and offering fast, dependable info. This text explains construct a medical chatbot that makes use of a number of vectorstores. It focuses on making a chatbot that may perceive medical reviews uploaded by customers and provides solutions based mostly on the knowledge in these reviews.
Moreover, this chatbot makes use of one other vectorstore crammed with conversations between medical doctors and sufferers about totally different medical points. This method permits the chatbot to have a variety of medical data and affected person interplay examples, serving to it give customized and related solutions to person questions. The purpose of this text is to supply builders and healthcare professionals a transparent information on develop a medical chatbot that may be a useful useful resource for sufferers on the lookout for info and recommendation based mostly on their very own well being reviews and issues.
Studying Aims
- Study to make the most of open-source medical datasets to coach a chatbot on doctor-patient conversations.
- Perceive construct and implement a vectorstore service for environment friendly information retrieval.
- Achieve abilities in integrating massive language fashions (LLMs) and embeddings to reinforce chatbot efficiency.
- Discover ways to construct a Multi-Vector Chatbot utilizing LangChain, Milvus, and Cohere for enhanced AI conversations.
- Perceive combine vectorstores and retrieval mechanisms for context-aware, environment friendly chatbot responses.
This text was printed as part of the Knowledge Science Blogathon.
Constructing a Multi-Vector Chatbot with LangChain, Milvus, and Cohere
The development of a medical chatbot able to understanding and responding to queries based mostly on medical reviews and conversations requires a rigorously architected pipeline. This pipeline integrates varied providers and information sources to course of person queries and ship correct, context-aware responses. Beneath, we define the steps concerned in constructing this subtle chatbot pipeline.
Observe: The providers like logger, vector retailer, LLM and embeddings has been imported from different modules. You may entry them from this repository. Be certain that so as to add all API keys and vector retailer urls earlier than working the pocket book.
Step1: Importing Essential Libraries and Modules
We’ll start by importing needed Python libraries and modules. The dotenv library hundreds surroundings variables, that are important for managing delicate info securely. The src.providers module comprises customized lessons for interacting with varied providers like vector shops, embeddings, and language fashions. The Ingestion class from src.ingest handles the ingestion of paperwork into the system. We import varied elements from LangChain and langchain_core to facilitate the retrieval of knowledge and technology of responses based mostly on the chatbot’s reminiscence and dialog historical past.
import pandas as pd
from dotenv import load_dotenv
from src.providers import LLMFactory, VectorStoreFactory, EmbeddingsFactory
from src.ingest import Ingestion
from langchain_core.prompts import (
ChatPromptTemplate,
)
from langchain.retrievers.ensemble import EnsembleRetriever
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain.reminiscence import ConversationBufferWindowMemory, SQLChatMessageHistory
_ = load_dotenv()Step2: Loading Knowledge
We’ll then load the dialog dataset from the info listing. The dataset might be downloaded from this URL. This dataset is crucial for offering the LLM with a data base to attract from when answering person queries.
information = pd.read_parquet("information/medqa.parquet", engine="pyarrow")
information.head()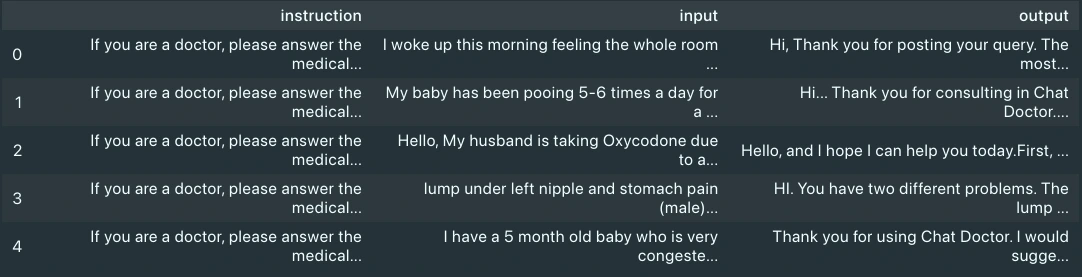
On visualizing the info, we will see it has three columns: enter, output and directions. We’ll contemplate solely the enter and output columns, as they’re the affected person’s question and physician’s response, respectively.
Step3: Ingesting Knowledge
The Ingestion class is instantiated with particular providers for embeddings and vector storage. This setup is essential for processing and storing the medical information in a manner that’s accessible and helpful for the chatbot. We’ll first ingest the dialog dataset, as this takes time. The ingestion pipeline was tuned to run ingestion in batches each minute for big content material, to beat the speed restrict error of embeddings providers. You may choose to vary the logic in src listing to ingest all of the content material, you probably have any paid service to beat fee restrict error. For this instance we might be utilizing an affected person report out there on-line. You may obtain the report from right here.
ingestion = Ingestion(
embeddings_service="cohere",
vectorstore_service="milvus",
)
ingestion.ingest_document(
file_path="information/medqa.parquet",
class="medical",
sub_category="dialog",
exclude_columns=["instruction"],
)
ingestion.ingest_document(
file_path="information/anxiety-patient.pdf",
class="medical",
sub_category="doc",
)Step4: Initializing Companies
The EmbeddingsFactory, VectorStoreFactory, and LLMFactory lessons are used to instantiate the embeddings, vector retailer, and language mannequin providers, respectively. You may obtain these modules from the repository talked about to start with of this part. It has a logger built-in for observability and has choices for selecting embeddings, LLM and vector retailer providers.
embeddings_instance = EmbeddingsFactory.get_embeddings(
embeddings_service="cohere",
)
vectorstore_instance = VectorStoreFactory.get_vectorstore(
vectorstore_service="milvus", embeddings=embeddings_instance
)
llm = LLMFactory.get_chat_model(llm_service="cohere")Step5: Creating Retrievers
We create two retrievers utilizing the vector retailer occasion: one for conversations (doctor-patient interactions) and one other for paperwork (medical reviews). We configure these retrievers to seek for info based mostly on similarity, utilizing filters to slender the search to related classes and sub-categories. Then, we use these retrievers to create an ensemble retriever.
conversation_retriever = vectorstore_instance.as_retriever(
search_type="similarity",
search_kwargs={
"okay": 6,
"fetch_k": 12,
"filter": {
"class": "medical",
"sub_category": "dialog",
},
},
)
document_retriever = vectorstore_instance.as_retriever(
search_type="similarity",
search_kwargs={
"okay": 6,
"fetch_k": 12,
"filter": {
"class": "medical",
"sub_category": "doc",
},
},
)
ensambled_retriever = EnsembleRetriever(
retrievers=[conversation_retriever, document_retriever],
weights=[0.4, 0.6],
)Step6: Managing Dialog Historical past
We arrange a SQL-based system to retailer the chat historical past, which is essential for sustaining context all through a dialog. This setup permits the chatbot to reference earlier interactions, guaranteeing coherent and contextually related responses.
historical past = SQLChatMessageHistory(
session_id="ghdcfhdxgfx",
connection_string="sqlite:///.cache/chat_history.db",
table_name="message_store",
session_id_field_name="session_id",
)
reminiscence = ConversationBufferWindowMemory(chat_memory=historical past)Step7: Producing Responses
The ChatPromptTemplate is used to outline the construction and directions for the chatbot’s responses. This template guides the chatbot in use the retrieved info to generate detailed and correct solutions to person queries.
immediate = ChatPromptTemplate.from_messages(
[
(
"system",
"""<INSTRUCTIONS FOR LLM>
{context}""",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
]
)Step8: Creating Historical past Conscious RAG Chain
Now that each one the elements are prepared, we sew them to create a RAG chain.
question_answer_chain = create_stuff_documents_chain(llm, immediate)
history_aware_retriever = create_history_aware_retriever(
llm, ensambled_retriever, immediate
)
rag_chain = create_retrieval_chain(
history_aware_retriever, question_answer_chain,
)Now the pipeline is prepared to absorb person queries. The chatbot processes these queries via a retrieval chain, which includes retrieving related info and producing a response based mostly on the language mannequin and the supplied immediate template. Let’s attempt the pipeline with some queries.
response = rag_chain.invoke({
"enter": "Give me an inventory of main axiety problems with Ann.",
}
)
print(response["answer"])The mannequin was in a position to reply the question from the PDF doc.
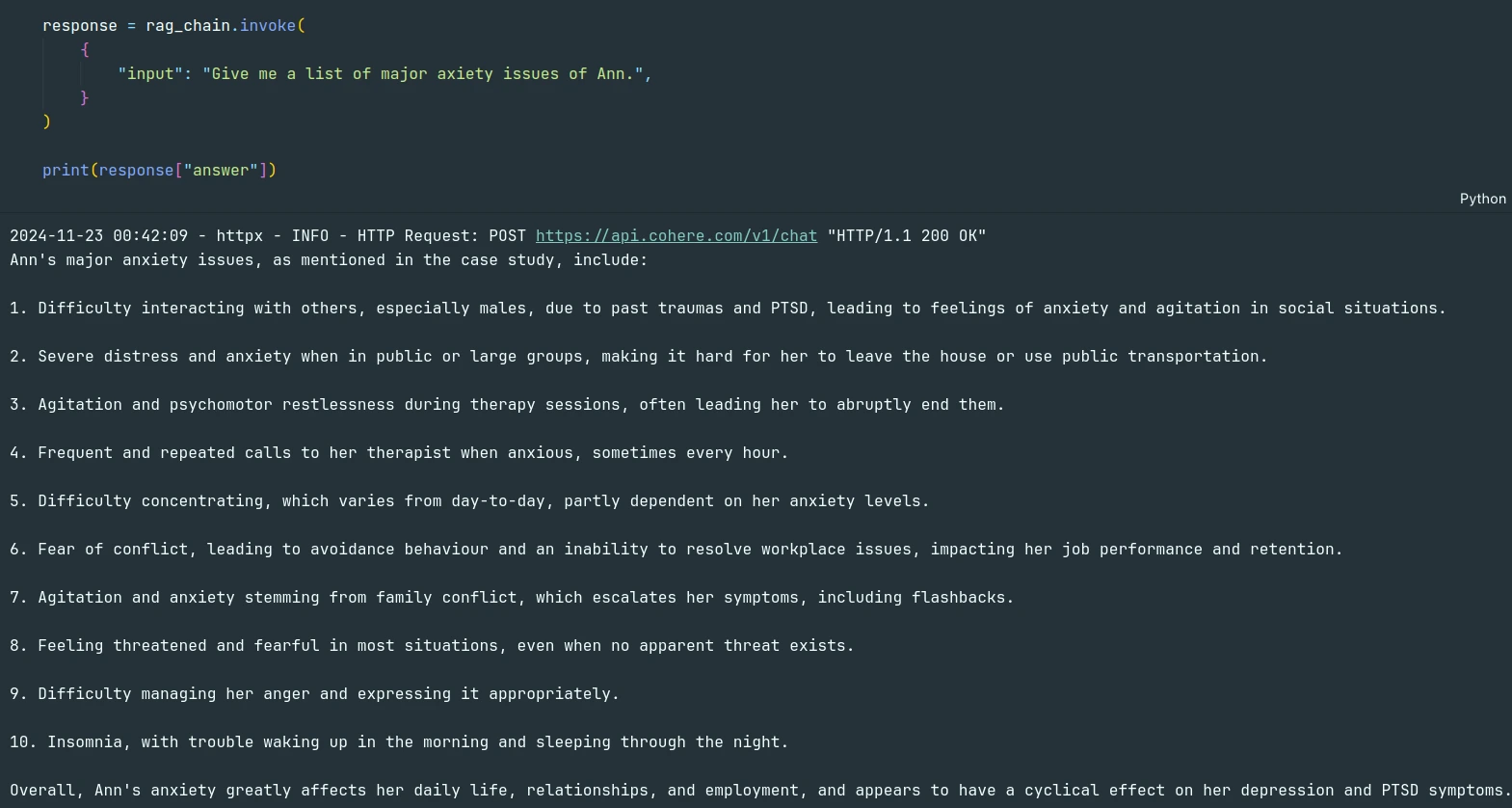
We are able to confirm that utilizing the sources.

Subsequent, let’s make the most of the historical past and the dialog database that we ingested and examine if the LLM makes use of them to reply one thing not talked about within the PDF.
response = rag_chain.invoke({
"enter": "Ann appears to have insomnia. What can she do to repair it?",
}
)
print(response["answer"])If we confirm the reply with the sources, we will see LLM truly makes use of the dialog database to reply concerning the brand new question.


Conclusion
The development of a medical chatbot, as outlined on this information, represents a big development within the utility of AI and machine studying applied sciences inside the healthcare area. By leveraging a
subtle pipeline that integrates vector shops, embeddings, and huge language fashions, we will create a chatbot able to understanding and responding to advanced medical queries with excessive accuracy and relevance. This chatbot not solely enhances entry to medical info for sufferers and healthcare seekers but additionally demonstrates the potential for AI to help and increase healthcare providers. The versatile and scalable structure of the pipeline ensures that it may well evolve to satisfy future wants, incorporating new information sources, fashions, and applied sciences as they develop into out there.
In conclusion, the event of this medical chatbot pipeline is a step ahead within the journey
in the direction of extra clever, accessible, and supportive healthcare instruments. It highlights the significance of integrating superior applied sciences, managing information successfully, and sustaining dialog context, setting a basis for future improvements within the subject.
Key Takeaways
- Uncover the method of making a Multi-Vector Chatbot with LangChain, Milvus, and Cohere for seamless conversations.
- Discover the mixing of vectorstores to allow environment friendly, context-aware responses in a Multi-Vector Chatbot.
- The success of a medical chatbot depends on precisely processing medical information and coaching the mannequin.
- Personalization and scalability are key to making a helpful and adaptable medical assistant.
- Leveraging embeddings and LLMs enhances the chatbot’s potential to supply correct, context-aware responses.
Often Requested Questions
A. A medical chatbot supplies medical recommendation, info, and help to customers via conversational interfaces utilizing AI expertise.
A. It makes use of massive language fashions (LLMs) and a structured database to course of medical information and generate responses to person queries based mostly on skilled data.
A. Vectorstores retailer vector representations of textual content information, enabling environment friendly retrieval of related info for chatbot responses.
A. Personalization includes tailoring the chatbot’s responses based mostly on user-specific information, like medical historical past or preferences, for extra correct and related help.
A. Sure, guaranteeing the privateness and safety of person information is vital, as medical chatbots deal with delicate info that should adjust to rules like HIPAA.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.
A Machine Studying and Deep Studying practitioner with a background in Laptop Science Engineering. My work pursuits embody Machine Studying, Deep Studying, Laptop Imaginative and prescient and NLP, with experience in Generative AI and Retrieval Augmented Technology.