

{kind=link}
The Databricks Serverless compute infrastructure launches and manages tens of millions of digital machines (VMs) every day throughout three main cloud suppliers, and it’s a substantial problem in working the infrastructure at this scale with effectivity. At the moment, we need to share with you among the work that we have now lately completed to allow a real Serverless expertise: having not simply the compute assets but in addition all of the underlying methods able to tackle knowledge and AI workloads (e.g., full blown Apache Spark clusters or LLM serving) inside seconds at scale.
So far as we’re conscious, no different Serverless platform is able to operating the various units of knowledge and AI workloads at scale inside seconds. The important thing problem lies within the time and price required to arrange the VM setting for optimum efficiency, which includes not solely putting in numerous software program packages but in addition totally warming up the runtime setting. Take Databricks Runtime (DBR) for example: it requires warming up the JVM’s JIT compiler to supply the height efficiency to prospects proper from the beginning.
On this weblog, we current the system-level optimizations we have now developed to scale back the boot time of VMs preloaded with the Databricks software program (or just Databricks VMs) from minutes to seconds — a 7x enchancment for the reason that launch of our Serverless platform which now powers just about all Databricks merchandise. These optimizations span the complete software program stack, from the OS and container runtime all the best way to the hosted purposes, and allow us to save lots of tens of tens of millions of minutes in compute day by day and ship the perfect worth efficiency to Databricks Serverless prospects.
Booting a Databricks VM
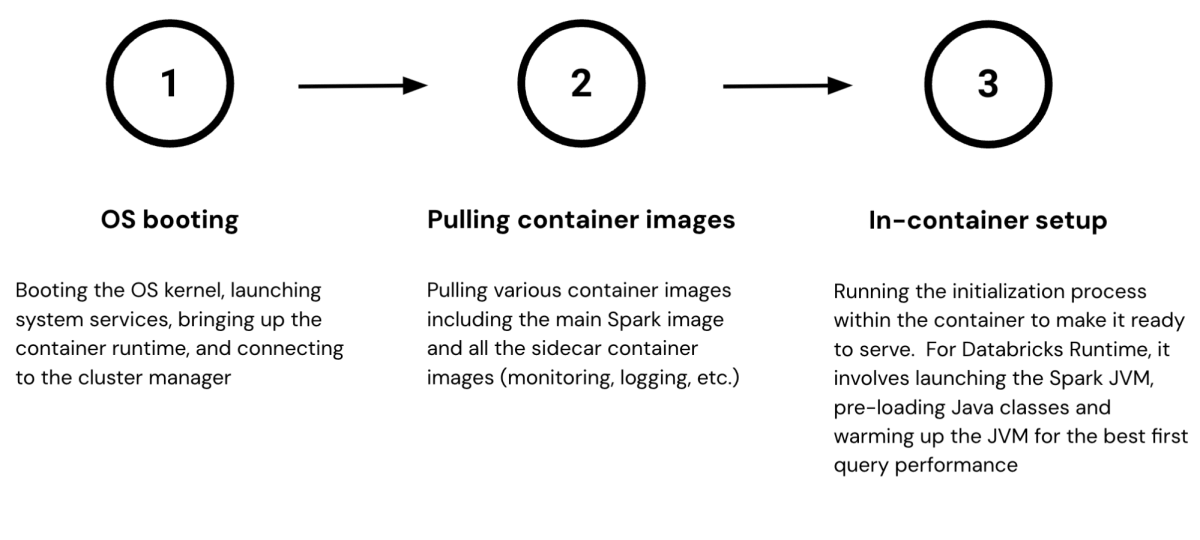
We describe the three fundamental boot levels from Determine 1 and briefly clarify why they take time beneath:
- OS booting. A Databricks VM begins with the final OS boot sequence: it boots the kernel, begins the system providers, brings up the container runtime, and eventually connects to the cluster supervisor which manages all of the VMs within the fleet.
- Pulling container pictures. At Databricks, we bundle purposes as container pictures to simplify runtime useful resource administration and streamline deployment. As soon as the VM connects to the cluster supervisor, it receives a listing of container specs and begins downloading a number of gigabytes of pictures from the container registry. These pictures embody not solely the newest Databricks Runtime but in addition utility purposes for log processing, VM well being monitoring, and metric emission, amongst different important capabilities.
- In-container setup. Lastly, the VM brings up the workload container, initializes the setting and makes it able to serve. Take Databricks Runtime for example — its initialization course of includes loading 1000’s of Java libraries and warming up the JVM by executing a sequence of fastidiously chosen queries. We run the warm-up queries to pressure the JVM to just-in-time (JIT) compile bytecode to native machine directions for frequent code paths, and this ensures customers can benefit from the peak runtime efficiency proper from their very first question. Working a lot of warm-up queries can be certain that the system will present a low-latency expertise for every kind of queries and knowledge processing wants. Nonetheless, a bigger variety of queries can lead to the initialization course of taking minutes to complete.
For every of those levels we improved the latency by creating the optimizations beneath.
A purpose-built Serverless OS
For Databricks Serverless, we handle the complete software program stack, so we are able to construct a specialised Serverless OS that meets our must run ephemeral VMs. Our tenet is to make the Serverless OS nimble. Particularly, we embody solely important software program required for operating containers and adapt their boot sequence to carry up essential providers sooner than in a generic OS. We tune the OS to favor buffered I/O writes and cut back disk bottlenecks throughout boot.
Eradicating pointless OS parts hastens the boot course of not solely by minimizing what must be initialized (for instance, disabling the USB subsystem, which is totally pointless for a cloud VM), but in addition by making the boot course of extra amenable to a cloud setup. In VMs, the OS boots from a distant disk the place the disk content material is fetched to the bodily host throughout the boot, and cloud suppliers optimize the method by way of numerous caching layers of the disk content material based mostly on the prediction of block sectors which can be extra prone to be accessed. A smaller OS picture permits cloud suppliers to cache the disk content material extra successfully.
Moreover, we customise the Serverless OS to scale back I/O rivalry throughout the boot course of, which frequently includes vital file writes. As an illustration, we tune the system settings to buffer extra file writes in reminiscence earlier than the kernel has to flush them to disks. We additionally modify the container runtime to scale back blocking, synchronous writes throughout picture pulls and container creations. We design these optimizations particularly for short-lived, ephemeral VMs the place knowledge loss from energy outages and system crashes are of little concern.
A lazy container filesystem
After a Databricks VM connects to the cluster supervisor, it should obtain gigabytes of container pictures earlier than initializing the Databricks Runtime and different utility purposes, reminiscent of these for log processing and metrics emission. The downloading course of can take a number of minutes to complete even when using the complete community bandwidth and/or disk throughput. Then again, prior analysis has proven that whereas downloading container pictures accounts for 76% of container startup time, solely 6.4% of the info is required for containers to start helpful work initially.
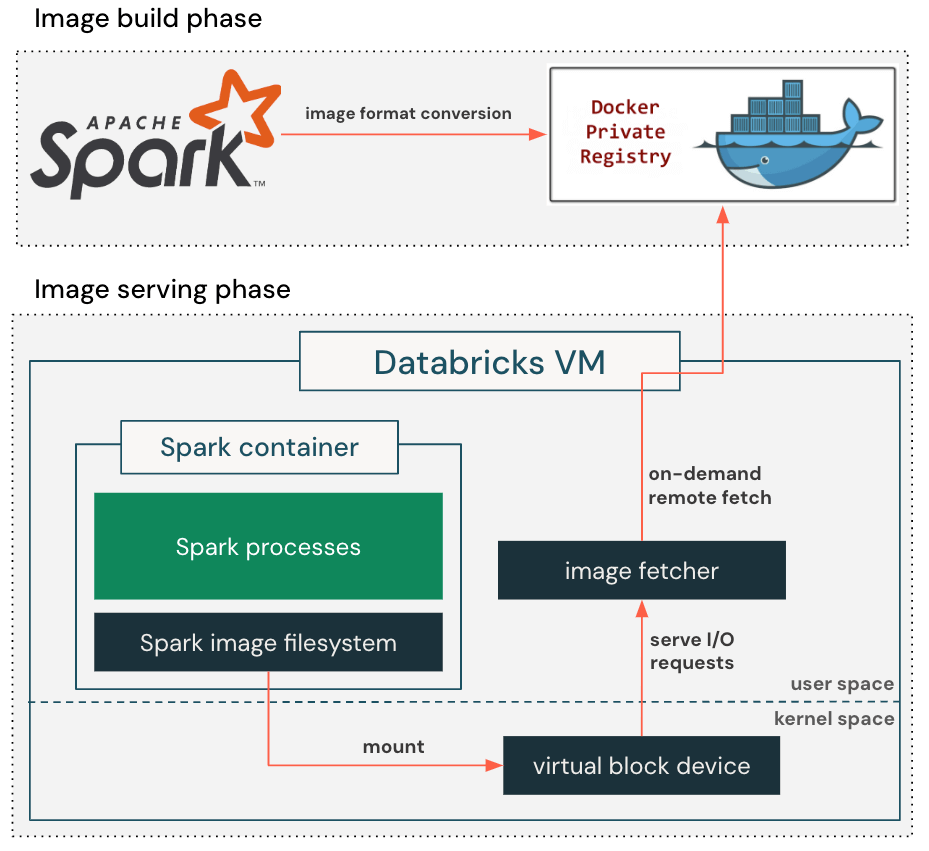
To use this commentary, we allow a lazy container filesystem as proven in Determine 2. When constructing a container picture, we add an additional step to transform the usual, gzip-based picture format to the block-device-based format that’s appropriate for lazy loading. This permits the container picture to be represented as a seekable block system with 4MB sectors in manufacturing.
When pulling container pictures, our personalized container runtime retrieves solely the metadata required to arrange the container’s root listing, together with listing construction, file names, and permissions, and creates a digital block system accordingly. It then mounts the digital block system into the container in order that the appliance can begin operating instantly. When the appliance reads a file for the primary time, the I/O request towards the digital block system will concern a callback to the picture fetcher course of, which retrieves the precise block content material from the distant container registry. The retrieved block content material can also be cached regionally to stop repeated community spherical journeys to the container registry, lowering the influence of variable community latency on future reads.
The lazy container filesystem eliminates the necessity to obtain the complete container picture earlier than beginning the appliance, lowering picture pull latency from a number of minutes to just some seconds. By spreading the picture obtain over an extended time period, it alleviates the strain on the blob storage bandwidth and avoids throttling.
Checkpointing/Restoring a pre-initialized container
Within the ultimate step, we initialize the container by executing a protracted in-container setup sequence earlier than marking the VM as able to serve. For Databricks Runtime, we pre-load all needed Java lessons and run an intensive process to heat up the Spark JVM course of. Whereas this method offers peak efficiency for customers’ preliminary queries, it considerably will increase boot time. Furthermore, the identical setup course of is repeated for each VM launched by Databricks.
We handle the pricey startup course of by caching the absolutely warmed-up state. Particularly, we take a process-tree checkpoint of a pre-initialized container and use it as a template to launch future cases of the identical workload sort. On this setup, the containers are “restored” instantly right into a constant, initialized state, bypassing the repeated and expensive setup course of completely.
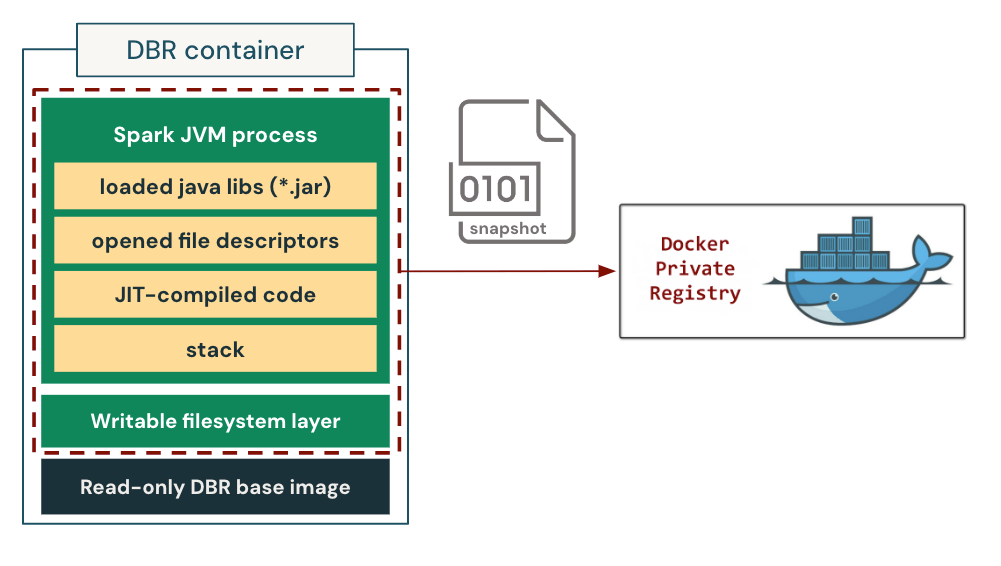
We implement and combine the checkpoint/restore functionality into our personalized container runtime. We present the way it works in Determine 3. Throughout checkpointing, the container runtime first freezes the entire course of tree of the container to make sure state consistency. It then dumps the method states, together with the loaded libraries, the opened file descriptors, the complete heap state (together with the JIT-compiled native code), and the stack reminiscence to the disk. It moreover saves the writable layer of the container filesystem to protect the information created/modified throughout the container initialization course of. This permits us to revive each the in-memory course of state and the on-disk filesystem state at a later time. We bundle the checkpoint into an OCI/Docker-compatible picture, then retailer and distribute it utilizing the container registry as if it have been a normal container picture.
Whereas this method is conceptually easy, it does include its personal challenges:
- Databricks Runtime should be checkpoint/restore appropriate. It was not the case initially as a result of (1) Databricks Runtime might entry non-generic info (reminiscent of hostname, IP handle and even pod title) for numerous use circumstances whereas we might restore the identical checkpoint on many various VMs, and (2) Databricks Runtime was unable to deal with the sudden shift of the wall clock time because the restore might occur days and even weeks after when the checkpoint was taken. To deal with this, we launched a checkpoint/restore-compatible mode within the Databricks Runtime. This mode defers the binding of host-specific info till after restoration. It additionally provides the pre-checkpoint and post-restore hooks to allow customized logic throughout checkpoint/restore. For instance, Databricks Runtime can make the most of the hooks to handle the time shift by pausing and resuming heartbeats, re-establish exterior community connections, and extra.
- Checkpoints should not solely about Databricks Runtime variations. A checkpoint captures the ultimate course of state of the container, so it’s decided by many elements such because the Databricks Runtime model, utility configurations, heap measurement, the instruction set structure (ISA) of the CPU, and many others. That is intuitive, as restoring a checkpoint taken on a 64GB VM to a 32GB VM will doubtless lead to an out-of-memory (OOM) error whereas restoring a checkpoint taken on an Intel CPU to an AMD CPU might result in unlawful directions as a result of JVM’s JIT compiler producing optimum native code based mostly on the ISA. It presents a major problem in designing a checkpoint CI/CD pipeline that may hold tempo with the fast-evolving Databricks Runtime growth and compute infrastructure. Somewhat than enumerating all doable signatures throughout all these dimensions, we create checkpoints on-demand every time a brand new signature seems in manufacturing. The created checkpoints are then uploaded and distributed utilizing the container registry, in order that future launches of workloads with matching signatures will be instantly restored from them throughout the fleet. This method not solely simplifies the design of the checkpoint era pipeline but in addition ensures all created checkpoints are literally helpful in manufacturing.
- Restoring uniqueness. Launching a number of containers from the identical checkpoint can break the distinctiveness assure. For instance, the random quantity mills (RNGs) will share the identical seed and begin to output the identical sequence of random numbers after restoration. We observe the RNG objects created throughout initialization and make the most of the post-restore hook to reseed the RNG objects to revive their uniqueness.
Our analysis reveals that this optimization has diminished the initialization and warm-up time of Databricks Runtime from a number of minutes to round 10 seconds. This functionality additionally permits for a deeper JVM warm-up with out concern for time as it’s now not on the essential path.
Conclusion
At Databricks, we’re dedicated to delivering the perfect worth efficiency to our prospects by constantly innovating and maximizing worth on their behalf. This weblog describes a sequence of deep, system-level optimizations that cut back the boot time of Databricks VMs by 7x. This not solely allows a a lot better latency and efficiency expertise for Serverless prospects, but in addition permits us to ship this degree of consumer expertise on the lowest doable worth. In the meantime, we are going to issue within the diminished VM boot-up time when sizing the nice and cozy pool to additional drive down the Serverless prices (keep tuned for extra particulars!). Lastly, we want to thank the open-source communities as we benefited tremendously from them in bringing these optimizations into actuality. Begin your free trial at this time, and get a firsthand expertise with Databricks Serverless!