

{kind=link}


Are you struggling to handle the ever-increasing quantity and number of information in right now’s continuously evolving panorama of recent information architectures? The huge tapestry of information varieties spanning structured, semi-structured, and unstructured information means information professionals must be proficient with varied information codecs reminiscent of ORC, Parquet, Avro, CSV, and Apache Iceberg tables, to cowl the ever rising spectrum of datasets – be they pictures, movies, sensor information, or different sort of media content material. Navigating this intricate maze of information might be difficult, and that’s why Apache Ozone has turn into a preferred, cloud-native storage answer that spans any information use case with the efficiency wanted for right now’s information architectures.
Apache Ozone, a extremely scalable, excessive efficiency distributed object retailer, gives the best answer to this requirement with its bucket format flexibility and multi-protocol help. Apache Ozone is appropriate with Amazon S3 and Hadoop FileSystem protocols and gives bucket layouts which might be optimized for each Object Retailer and File system semantics. With these options, Apache Ozone can be utilized as a pure object retailer, a Hadoop Appropriate FileSystem (HCFS), or each, enabling customers to retailer several types of information in a single retailer and entry the identical information utilizing a number of protocols offering the scale of an object retailer and the pliability of the Hadoop File system.
A earlier weblog publish describes the totally different bucket layouts obtainable in Ozone. This weblog publish is meant to supply steerage to Ozone directors and software builders on the optimum utilization of the bucket layouts for various functions.
To begin with, Ozone’s namespace contains the next conceptual entities:
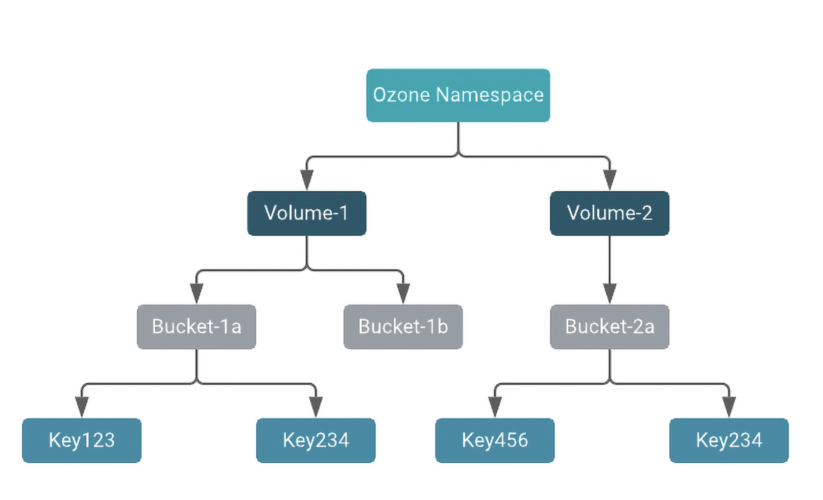
Fig.1 Apache Ozone Namespace format
- Volumes are the highest degree namespace grouping in Ozone. Quantity names should be distinctive and can be utilized for tenants or customers.
- Buckets can be utilized as mum or dad directories. Every quantity can include a number of buckets of information. Bucket names should be distinctive inside a quantity.
- Keys retailer information inside buckets. Keys might be recordsdata, directories, or objects.
Bucket Layouts in Apache Ozone
File System Optimized (FSO) and Object Retailer (OBS) are the 2 new bucket layouts in Ozone for unified and optimized storage in addition to entry to recordsdata, directories, and objects. Bucket layouts present a single Ozone cluster with the capabilities of each a Hadoop Appropriate File System (HCFS) and Object Retailer (like Amazon S3). Considered one of these two layouts ought to be used for all new storage wants.
An outline of the bucket layouts and their options are beneath.
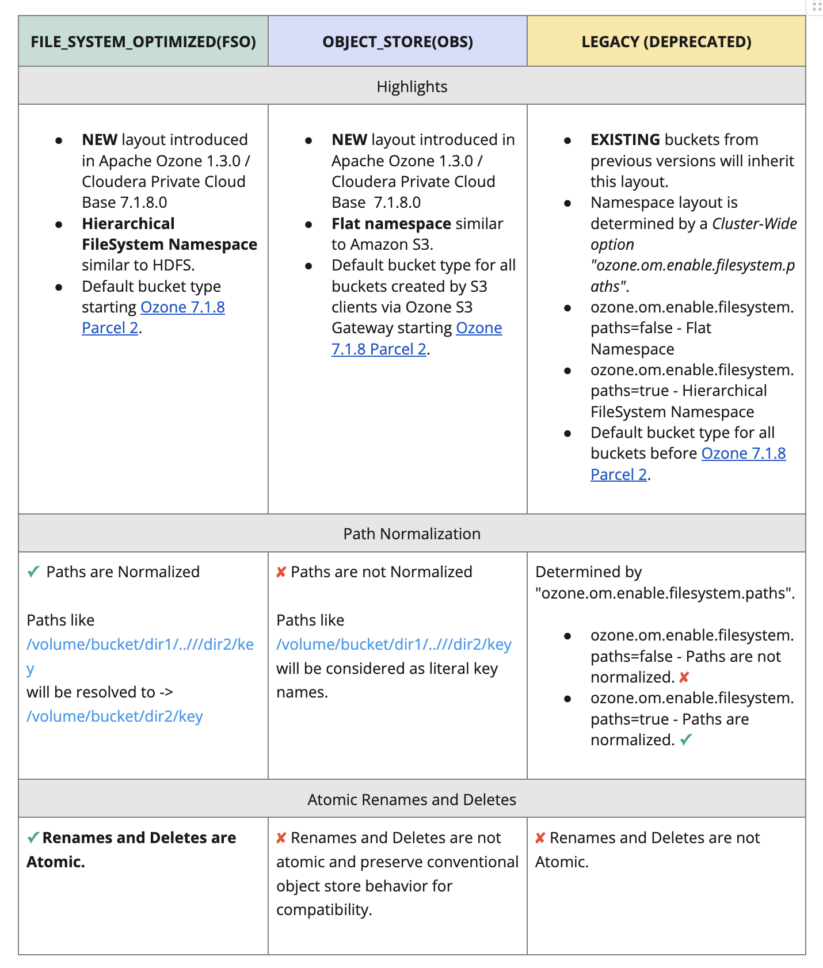
Fig 2. Bucket Layouts in Apache Ozone
Interoperability between FS and S3 API
Customers can retailer their information in Apache Ozone and might entry the information with a number of protocols.
Protocols offered by Ozone:
- ofs
- ofs is a Hadoop Appropriate File System (HCFS) protocol.
- ozone fs is a command line interface much like “hdfs dfs” CLI that works with HCFS protocols like ofs.
- Most conventional analytics functions like Hive, Spark, Impala, YARN and so on. are constructed to make use of the HCFS protocol natively and therefore they will use the ofs protocol to entry Ozone out of the field with no modifications.
- Trash implementation is on the market with the ofs protocol to make sure protected deletion of objects.
- S3
- Any cloud-native S3 workload constructed to entry S3 storage utilizing both the AWS CLI, Boto S3 shopper, or different S3 shopper library can entry Ozone through the S3 protocol.
- Since Ozone helps the S3 API, it will also be accessed utilizing the s3a connector. S3a is a translator from the Hadoop Appropriate Filesystem API to the Amazon S3 REST API.
- Hive, Spark, Impala, YARN, BI instruments with S3 connectors can work together with Ozone utilizing the s3a protocol.
- When accessing FSO buckets by means of the S3 interface, paths are normalized, however renames and deletes are not atomic.
- s3a will translate listing renames to particular person object renames on the shopper earlier than sending them to Ozone. Ozone’s S3 gateway will ahead the item renames to the FSO bucket.
- Entry to LEGACY buckets utilizing S3 interface is similar as entry to FSO bucket if, ozone.om.allow.filesystem.paths=true in any other case, it’s the identical as entry to OBS bucket.
- o3
- Ozone Shell (ozone sh) is a command line interface used to work together with Ozone utilizing the o3 protocol.
- Ozone Shell is beneficial to make use of for quantity and bucket administration, however it will also be used to learn and write information.
- Solely anticipated for use by cluster directors.
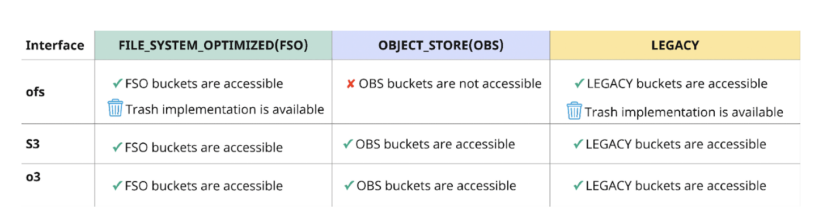
Fig 3. Interoperability between FS and S3 APIOzone’s help for interoperability between File System and Object Retailer API can facilitate the implementation of hybrid cloud use circumstances reminiscent of:
1- Ingesting information utilizing S3 interface into FSO buckets for low latency analytics utilizing the ofs protocol.
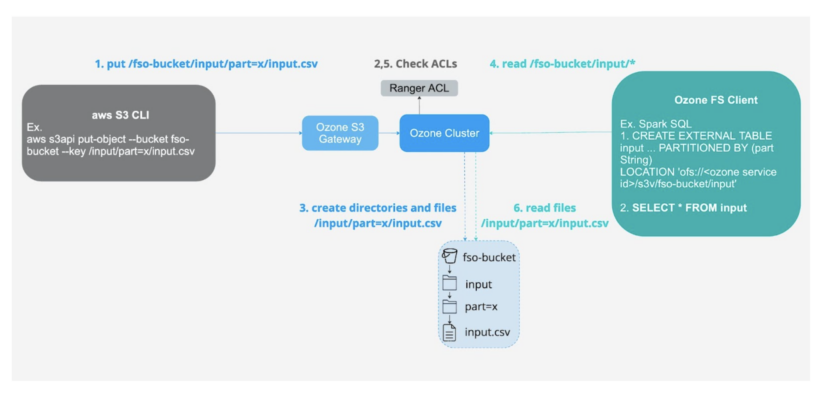
Fig 4. Ingest utilizing S3 API and eat utilizing FS API
2- Storing information on-premises for safety and compliance which will also be accessed utilizing cloud-compatible API.
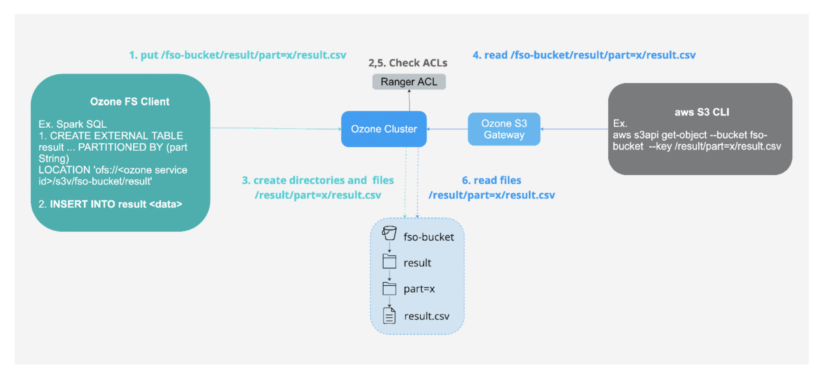
Fig 5. Ingest utilizing FS API and eat utilizing S3 API
When to make use of FSO vs OBS Bucket Layouts
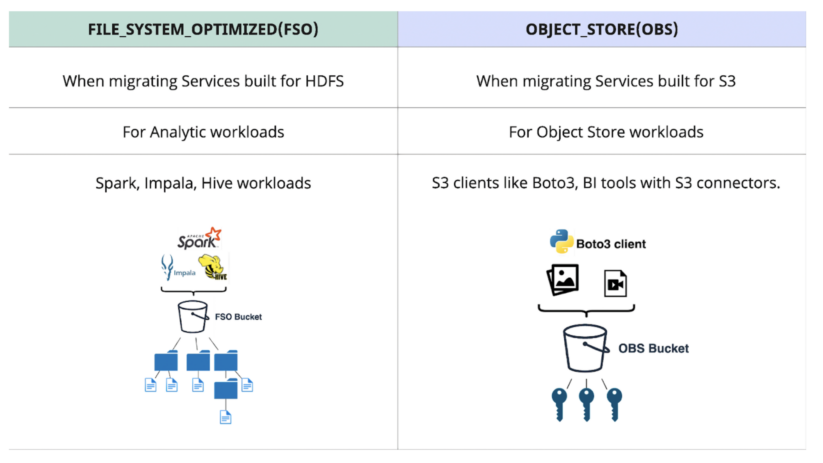
Fig 6. When to make use of FSO vs OBS
- Analytics companies constructed for HDFS are notably effectively fitted to FSO buckets:
- Apache Hive and Impala drop desk question, recursive listing deletion, and listing shifting operations on information in FSO buckets are sooner and constant with none partial ends in case of any failure as a result of renames and deletes are atomic and quick.
- Job Committers of Hive, Impala, and Spark typically rename their non permanent output recordsdata to a closing output location on the finish of the job. Renames are sooner for recordsdata and directories in FSO buckets.
- Cloud-native functions constructed for S3 are higher fitted to OBS buckets:
- OBS buckets present strict S3 compatibility.
- OBS buckets present wealthy storage for media recordsdata and different unstructured information enabling exploration of unstructured information.
Abstract
Bucket layouts are a robust characteristic that enable Apache Ozone for use as each an Object Retailer and Hadoop Appropriate File System. On this article, we have now lined the advantages of every bucket format and the way to decide on the very best bucket format for every workload.
In case you are concerned with studying extra about the best way to use Apache Ozone to energy information science, this is a good article. If you wish to know extra about Cloudera on non-public cloud, see right here.
Our Skilled Companies, Assist and Engineering groups can be found to share their data and experience with you to decide on the suitable bucket layouts on your varied information and workload wants and optimize your information structure. Please attain out to your Cloudera account crew or get in contact with us right here.
References:
[1] https://weblog.cloudera.com/apache-ozone-a-high-performance-object-store-for-cdp-private-cloud/
[2] https://weblog.cloudera.com/a-flexible-and-efficient-storage-system-for-diverse-workloads/