

{kind=link}

GPUs have an insatiable want for knowledge, and holding these processors fed could be a problem. That’s one of many huge causes that WEKA launched a brand new line of information storage home equipment final week that may transfer knowledge at as much as 18 million IOPS and serve 720 GB of information per second.
The most recent GPUs from Nvidia can ingest knowledge from reminiscence at unbelievable speeds, as much as 2 TB of information per second for the A100 and three.35 TB per second for the H100. This kind of reminiscence bandwidth, utilizing the most recent HBM3 customary, is required to coach the biggest massive language fashions (LLMs) and run different scientific workloads.
Conserving the PCI busses saturated with knowledge is essential for using the total capability of the GPUs, and that requires a knowledge storage infrastructure that’s able to maintaining. The oldsters at WEKA say they’ve performed that with the brand new WEKApod line of information storage home equipment it launched final week.
The corporate is providing two variations of the WEKApod, together with the Prime and the Nitro. Each households begin with clusters of eight rack-based servers and round half a petabyte of information, and might scale to assist lots of of servers and a number of petabytes of information.
The Prime line of WEKApods relies on PCIe Gen4 expertise and 200Gb Ethernet or Infiniband connectors. It begins out with 3.6 million IOPS and 120 GB per second of learn throughput, and goes as much as 12 million IOPS and 320 GB of learn throughput.
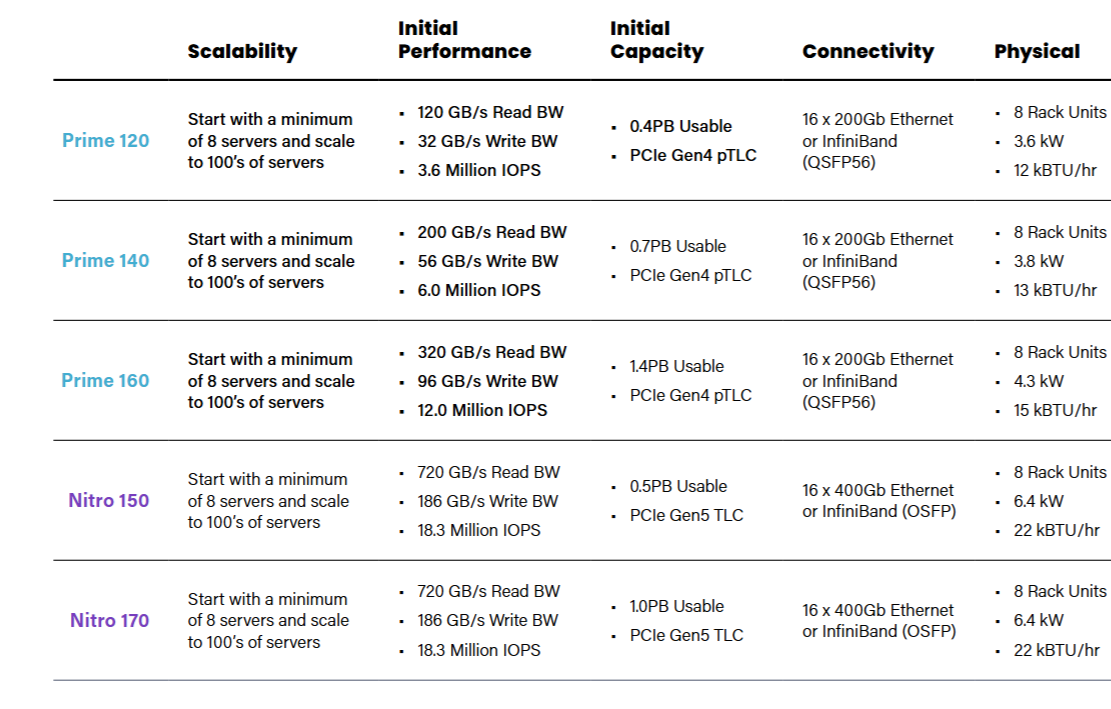
WEKApod specs
The Nitro line relies on PCIe Gen5 expertise and 400Gb Ethernet or Infiniband connectors. Each the Nitro 150 and the Nitro 180 are rated at 18 million IOPS of bandwidth and might hit knowledge learn speeds of 720 GB per second and knowledge write speeds of 186 GB per second.
Enterprise AI workloads require excessive efficiency for each studying and writing of information, says Colin Gallagher, vice chairman of product advertising and marketing for WEKA.
“A number of of our opponents have recently been claiming to be the perfect knowledge infrastructure for AI,” Gallagher says in a video on the WEKA web site. “However to take action they selectively quote a single quantity, typically one for studying knowledge, and depart others out. For contemporary AI workloads, one efficiency knowledge quantity is deceptive.”
That’s as a result of, in AI knowledge pipelines, there’s a crucial knowledge interaction between studying and writing of information because the AI workloads change, he says.
“Initially, knowledge is ingested from numerous sources for coaching, loaded to reminiscence, preprocessed and written again out,” Gallagher says. “Throughout coaching, it’s regularly learn to replace mannequin parameters, checkpoints of assorted sizes are saved, and outcomes are written for analysis. After coaching, the mannequin generates outputs that are written for additional evaluation or use.”
The WEKAPods make the most of the WekaFS file system, the corporate’s high-speed parallel file system, which helps a wide range of protocols. The home equipment assist GPUDirect Storage (GDS), an RDMA-based protocol developed by Nvidia, to enhance bandwidth and scale back latency between the server NIC and GPU reminiscence.
WekaFS has full assist for GDS and has been validated by Nvidia together with a reference structure, WEKA says. WEKApod Nitro is also licensed for Nvidia DGX SuperPOD.
WEKA says its new home equipment embody an array of enterprise options, comparable to assist for a number of protocols (FS, SMB, S3, POSIX, GDS, and CSI); encryption; backup/restoration; snapshotting; and knowledge safety mechanisms.
For knowledge safety particularly, it says it makes use of a patented distributed knowledge safety coding scheme to protect towards knowledge loss attributable to server failures. The corporate says it delivers the scalability and sturdiness of erasure coding, “however with out the efficiency penalty.”
“Accelerated adoption of generative AI functions and multi-modal retrieval-augmented era has permeated the enterprise quicker than anybody might have predicted, driving the necessity for inexpensive, highly-performant and versatile knowledge infrastructure options that ship extraordinarily low latency, drastically scale back the fee per tokens generated and might scale to fulfill the present and future wants of organizations as their AI initiatives evolve,” WEKA Chief Product Officer Nilesh Patel mentioned in a press launch. “WEKApod Nitro and WEKApod Prime provide unparalleled flexibility and selection whereas delivering distinctive efficiency, vitality effectivity, and worth to speed up their AI initiatives wherever and all over the place they want them to run.”
Associated Objects:
Legacy Knowledge Architectures Holding GenAI Again, WEKA Report Finds
Hyperion To Present a Peek at Storage, File System Utilization with World Website Survey
Object and File Storage Have Merged, However Product Variations Stay, Gartner Says