

{kind=link}

Replication is an important functionality in distributed programs to deal with challenges associated to fault tolerance, excessive availability, load balancing, scalability, knowledge locality, community effectivity, and knowledge sturdiness. It kinds a foundational factor for constructing sturdy and dependable distributed architectures. It is usually necessary to have a number of choices (like regular and prefixless replication) to do the replication course of, since each resolution has its personal benefits.
Streams Replication Supervisor (SRM) is an enterprise-grade replication resolution that permits fault tolerant, scalable, and sturdy cross-cluster Kafka matter replication. SRM replicates knowledge at excessive efficiency and retains matter properties in sync throughout clusters. Replication could be dynamically enabled for matters and shopper teams. SRM additionally delivers customized extensions that facilitate set up, administration, and monitoring, making SRM an entire replication resolution that’s constructed for mission-critical workloads.
Introduction
Kafka as an occasion streaming element could be utilized to all kinds of use circumstances. SRM offers cross-cluster Kafka matter replication to make it extra fault tolerant and sturdy. SRM is predicated on the Mirror Maker 2 (MM2) element of Kafka, which is the improved model of Mirror Maker (MM1). MM1 has been used for years in large-scale manufacturing environments, however not with out a number of limitations—that’s the reason MM2 was launched.
These are a number of the MM1 limitations that MM2 addresses:
- Subjects are created with default configuration, typically wanted to be repartitioned manually.
- ACL and configuration adjustments will not be synced throughout mirrored clusters. This makes it tough to handle a number of clusters.
- Data are repartitioned with DefaultPartitioner. Semantic partitioning could also be misplaced.
- Any configuration change means the cluster have to be bounced. This contains including new matters to the whitelist, which can be a frequent operation.
- No mechanism emigrate producers or shoppers between mirrored clusters.
- No assist for precisely as soon as supply. Data could also be duplicated throughout replication.
- Rebalancing causes latency spikes, which can set off additional rebalances.
When SRM replicates a subject, it renames the subject within the goal cluster by prefixing the identify of the subject with the alias (identify) of the supply cluster. This differs from the way in which replication labored in MM1, the place the goal matters had the identical identify because the supply (thus “prefixless”). The MM1 conduct is essential for some use-cases. For instance, cluster migration situations can’t be accurately carried out with the default replication conduct of SRM, the MM1 conduct is a should. Up till now, one of these replication was not obtainable or totally supported. Furthermore, MM1 was deprecated in one of many more moderen releases of Kafka (Kafka 3.0.0) and its use is not really useful.
To handle this, Cloudera launched a brand new MM1-compatible mode in SRM. Beginning with Cloudera Information Platform (CDP) Personal Cloud Base 7.1.9, prefixless replication is usually obtainable with replication monitoring assist in SRM. This makes it attainable emigrate cluster replication workloads from the deprecated MM1 to SRM with out change within the replicated matter names.
Replicated matter names
The naming of the replicated matters is outlined by the replication coverage that SRM is configured to make use of. By default, SRM makes use of the DefaultReplicationPolicy, which provides the supply cluster alias as a prefix to the identify of replicated matters. Prior to now, this was the one coverage obtainable natively in SRM and the design of the replication monitoring options within the service was based mostly on the belief that each replicated matter would all the time have a prefix. Due to this fact, SRM service function situations have been solely in a position to monitor replication flows that used a replication coverage that makes use of prefixes, such because the DefaultReplicationPolicy.
As soon as the IdentityReplicationPolicy was launched, customers have been in a position to replicate matters with out having prefixes added to the replicated matter names. Because of the design of the SRM service although, these replications couldn’t be monitored till the discharge of CDP Personal Cloud Base 7.1.9.
Notice: SRM helps customized matter naming insurance policies by way of a plugin referred to as replication coverage. There are two totally different Replication coverage varieties shipped with SRM by default:
- DefaultReplicationPolicy – default coverage. Prefixes matter names with “<source_cluster>.”
- IdentityReplicationPolicy – coverage which doesn’t change matter names throughout replication. (with this coverage, replication monitoring doesn’t work till CDP 7.1.9 launch)
Distant matter discovery
SRM wants to have the ability to know which matters are replicas and what are their respective supply matters. It depends on the replication coverage and the subject naming conventions to find reproduction matters by default. The method lists all the matter names of a cluster, then detects the supply cluster identify. When utilizing the DefaultReplicationPolicy, SRM is aware of {that a} matter is a duplicate when it has a prefix that could be a legitimate cluster alias (<cluster_alias>.). The reproduction matter identify incorporates the alias of the supply cluster and identify of the supply matter. As an example, the subject identify could be source-cluster.topic-name. On this case source-cluster would be the alias of the supply cluster, whereas topic-name would be the identify of the subject within the supply cluster.
This discovery process has some limitations, because it depends on matter naming conventions to supply supply cluster data. When the IdentityReplicationPolicy is used, the supply cluster can’t be recognized by this methodology. Moreover, the present state of the replication (stopped, lively, and many others.) has no reference to the reproduction matter detection—if a subject has been faraway from the SRM replication configuration, the logic will nonetheless detect the prefixed matter as a duplicate matter.
The above shortcomings have been addressed within the CDP Personal Cloud Base 7.1.9. On this launch, SRM is shipped with a brand new property Use Inner Matter For Distant Subjects Discovery, which is enabled for brand spanking new installations. For upgraded clusters, this function can be disabled by default to make sure that present SRM deployments will proceed to work with out adjustments in conduct.
When Use Inner Matter For Distant Subjects Discovery is enabled, SRM drivers will write the checklist of supply matter—goal matter pairs that should be replicated to an inside, compacted matter (srm-meta.inside), saved on the goal cluster. SRM drivers will periodically verify which matters should be replicated and can write updates to the inner matter as wanted.
Purchasers attempting to find reproduction matters are in a position to scan the “srm-meta.inside” matter, and devour the most recent message—which lists the presently replicated matters. This knowledge additionally incorporates the source-target matter identify mappings. It makes the function impartial of the ReplicationPolicy that’s in use.
Prefixless replication
From CDP 7.1.9, SRM helps knowledge replication, checkpointing, and monitoring with the IdentityReplicationPolicy. Id replication, or prefixless replication, implies that reproduction matters’ names would be the similar as on the supply cluster (MM1-compatible mode, however with some great benefits of MM2). The IdentityReplicationPolicy will also be used for matter aggregation use circumstances, the place the identical matter on a number of clusters are replicated to the identical identically-named “aggregated matter” on a special cluster. After all, aggregation could be prevented if DefaultReplicationPolicy is in use or if the separate supply clusters have totally different matter names.
To allow prefixless replication for SRM, you solely want to pick the “Allow Prefixless Replication” property within the SRM service configuration.
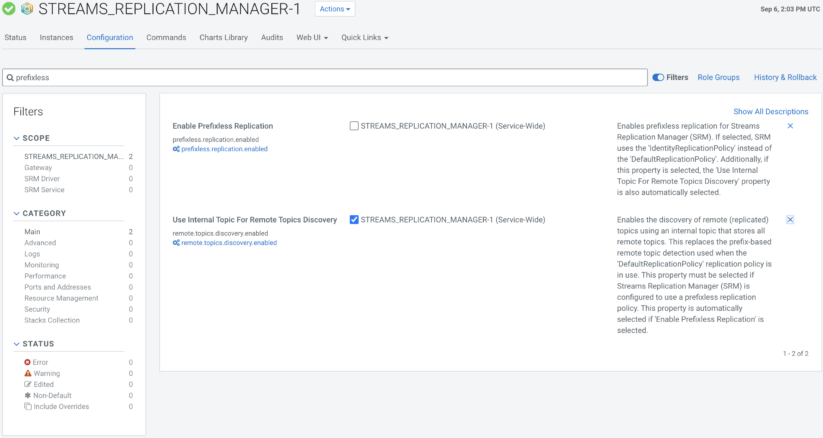
When “Allow Prefixless Replication” is chosen, SRM should additionally allow the “Use Inner Matter For Distant Subjects Discovery” function because of the limitations of reproduction discovery talked about beforehand on this weblog. Luckily, Cloudera Supervisor handles this routinely, so if a person permits the “Allow Prefixless Replication” possibility, Cloudera Supervisor will override the configuration of “Use Inner Matter For Distant Subjects Discovery” to allow it.
Prefixless replication will not be freed from limitations or caveats. Concentrate on the next:
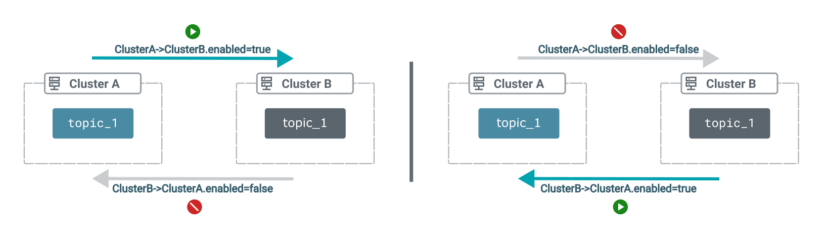
- Replication loop detection will not be supported
In consequence, you need to make sure that matters will not be replicated in a loop between your supply and goal clusters. You may guarantee this by establishing your matter enable and deny lists (often known as matter filters) in a approach that’s applicable in your use case.
For instance, assume you’ve got two replications that replicate matters between two clusters, however in several instructions. If each replications embody topic_1, they have to by no means be enabled on the similar time.
- All SRM providers should use the identical replication coverage
For instance, if you wish to use prefixless replication then all the SRM providers ought to use IdentityReplicationPolicy. In case of prefixed replication DefaultReplicationPolicy ought to be used all over the place. Clusters linked by replication flows, whatever the variety of SRM providers, ought to solely use one ReplicationPolicy. In any other case, replications can be combined up and undesirable uncomfortable side effects can occur.
- Group offset sync ought to be disabled
SRM makes a mapping about Kafka message offsets of the supply and goal clusters. Offset checkpoints are saved within the supply clusters and they are going to be interpreted provided that the message is coming from the present supply cluster. If extra supply clusters have the identical group offsets, then they will intervene with one another, so group offset sync ought to be disabled.
- Not all REST API endpoints and SMM UI options are supported
- The /v2/topic-metrics/{goal}/{downstreamTopic}/{metric} endpoint of the SRM Service v2 API doesn’t work correctly with prefixless replication. Use the /v2/topic-metrics/{supply}/{goal}/{upstreamTopic}/{metric} endpoint as an alternative.
- The replication metric graphs proven on the Matter Particulars web page of the SMM UI don’t work with prefixless replication. The graph will not be displayed.
Abstract
Prefixless replication allows you to use MM1-like replication conduct in CDP whereas accessing the numerous enterprise prepared options that SRM offers. Whereas aggregation is the primary use case for prefixless replication, it will also be used to construct conventional replication pipelines that present a security web in your Kafka knowledge if issues go amiss. Higher but, prefixless replication can also be an ideal software emigrate that previous Kafka deployment working on CDH, HDP, or HDF to CDP.
As well as, the adjustments and enhancements to distant matter discovery that have been launched alongside prefixless replication make SRM extra sturdy than ever as some core options inside SRM, like replication monitoring, not have to depend on matter prefixes to operate.
If you wish to be taught extra about SRM and Kafka in CDP Personal Cloud Base, jump over to Cloudera’s doc portal and see Streams Messaging Ideas, Streams Messaging How Tos, and/or the Streams Messaging Migration Information. That is the primary of a two-blog sequence, to proceed your journey on Streams Replication, click on right here.
To get arms on with SRM, obtain Cloudera Stream Processing Neighborhood version right here.
All for becoming a member of Cloudera?
At Cloudera, we’re engaged on fine-tuning huge knowledge associated software program bundles (based mostly on Apache open-source tasks) to supply our clients a seamless expertise whereas they’re working their analytics or machine studying tasks on petabyte-scale datasets. Examine our web site for a check drive!
In case you are excited by huge knowledge, want to know extra about Cloudera, or are simply open to a dialogue with techies, go to our fancy Budapest workplace at our upcoming meetups. Or, simply go to our careers web page, and grow to be a Clouderan!